





AMD Radeon HD 7970: per la prima volta a 28 nanometri

Debutto prima del previsto per la nuova proposta top di gamma di AMD nel settore delle schede video. Con Radeon HD 7970 viene infatti presentata la nuova architettura, nota con il nome in codice di Southern Island, destinata a rappresentare la base delle future schede video consumer e professionali del produttore americano
di Gabriele Burgazzi , Paolo Corsini pubblicato il 22 Dicembre 2011 nel canale Schede VideoAMDRadeon
Tahiti: l'architettura
Le schede della famiglia Radeon HD 7900 sono le prime sviluppate da AMD ad essere basata sulla nuova generazione di architettura, meglio nota con il nome di Graphics Core Next o GCN. L'approccio prevede, nelle GPU Tahiti, un massimo di 32 Compute Units all'interno delle quali trovano posto 64 stream processors ciascuna.

A monte dell'architettura troviamo due geometry engines, scelta mutuata da quanto visto nelle GPU di precedente generazione basate su architettura Cayman; all'interno di ciascuna è presente una unità di tessellation di nona generazione, responsabile secondo AMD dei notevoli incrementi prestazionali con tessellation che abbiamo evidenziato in una parte specifica di questo articolo.
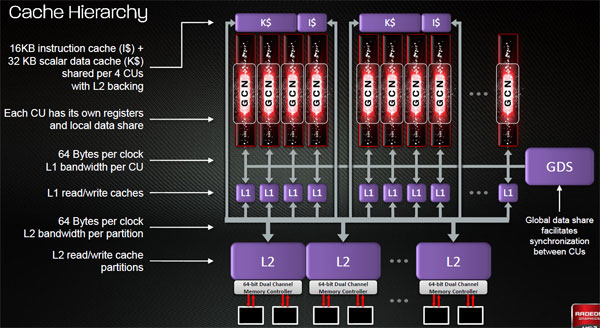
Nel chip Tahiti sono presenti numerose cache, con differenti livelli: quelle di primo livello sono di due tipologie, da 16 Kbytes per le istruzioni e da 32 Kbytes per i dati. Queste due tipologie di cache sono condivise da 4 Compute Unit, mentre per ogni CU sono presenti registri e data share locali. La bandwidth delle cache L1, di tipo read/write, è pari a 64 bytes per ciclo di clock. In totale sono presenti 128 Kbytes di cache L1 per istruzioni e 256 Kbytes di cache L1 per dati in schede che utilizzano tutti i 32 CU integrati come massimo nel chip Tahiti. La cache L2, presente in quantitativo di 768 Kbytes, è divisa in partizioni; ciascuna è capace di una bandwidth pari a 64 bytes per ciclo di clock. Una global data share mette in connessione le varie CU tra di loro, facilitando lo scambio dei dati tra questi componenti.

Il corpo centrale del chip è rappresentato dalle 32 CU, ciascuna delle quali integra 64 stream processors per un totale di 2.048 di questi componenti nell'implementazione adottata per la scheda Radeon HD 7970. Storicamente AMD utilizza la stessa GPU per differenti schede della medesima famiglia, disabilitando alcuni degli stream processors così da meglio segmentare i prodotti sul mercato: è pertanto ipotizzabile che la scheda Radeon HD 7950, non annunciata quest'oggi da AMD, possa seguire la stessa strada adottando una GPU Tahiti con meno di 32 CU attivate.
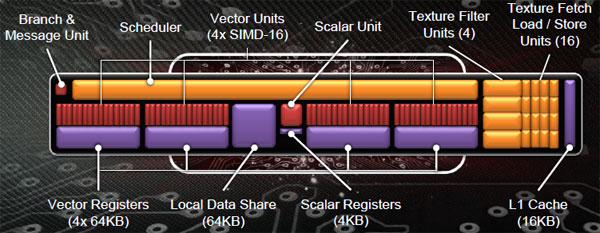
Cosa troviamo all'interno di ogni CU? Come segnalato, quella implementata nelle schede Radeon HD 7000 è una nuova architettura che differisce radicalmente sia da quella VLIW-5 delle schede Radeon HD 6000 sino ai modelli 6800 sia VLIW-4 delle proposte Radeon HD 6900. Troviamo 4 moduli SIMD, ciascuno composto da 16 stream processors (per un totale di 64 stream processors per ogni Compute Unit), con uno scheduler programmabile condiviso. Per ogni CU troviamo 4 texture unit, presenti quindi in numero di 128 nella scheda Radeon HD 7970; per ogni SIMD unit interna ad una CU troviamo un vector register da 64 Kbytes; una memoria di local data share sempre da 64 Kbytes è presente in ogni CU, affiancata da una memoria da 4 Kbytes dedicata alla scalar unit per i propri registri.
Ogni Compute Unit è in grado di eseguire contemporaneamente istruzioni da differenti kernels : un design di questo tipo è stato pensato da AMD in funzione di un throughput elevato, di una elevata utilizzazione delle risorse a disposizione e quindi di un notevole parallelismo. E' evidente come un design di questo tipo sia stato sviluppato da AMD tenendo conto anche delle necessità proprie delle elaborazioni di GPU Computing: del resto è presumibile che le architetture Tahiti verranno utilizzate anche per schede proposte nell'ambito professionale.
Confrontando un modulo CN, composto da 4 blocchi SIMD, con uno SIMD VLIW4 troviamo per entrambi la possibilità di eseguire sino a 64 operazioni multiply-add in singola precisione. Nell'approccio VLIW4 questo implica un processo di elaborazione che utilizza 1 istruzione VLIW per 4 ops ALU; in Tahiti abbiamo invece 4 SIMD che possono eseguire la stessa op ALU. La conseguenza è che se l'architettura VLIW4 è limitata dalla dipendenza delle istruzioni, quella Graphic Core Next è limitata dal tasso di occupazione delle SIMD. Il design scelto per l'architettura Graphic Core Next si rivela quindi essere non solo più semplice dal punto di vista di analisi e debug del codice, ma permette di operare con un approccio di compiler standardizzato sia per lo scheduling delle operazioni sia per la loro ottimizzazione.
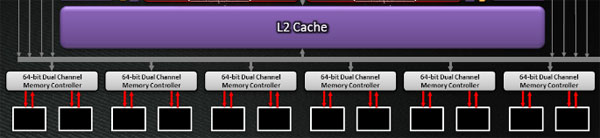
A chiudere l'architettura troviamo una cache L2 da 768 Kbytes di capacità complessiva, alla quale è direttamente collegato il controller memoria; quest'ultimo componente ha ampiezza di 384bit nella scheda Radeon HD 7970 ottenuta affiancando 6 memory controller dual channel a 64bit ciascuno. L'implicazione diretta è la presenza, in ogni scheda, di 12 chip memoria GDDR5 per un quantitativo complessivo di 3 Gbytes.

Ed ecco uno guardo complessivo all'architettura nello schema a blocchi; segnaliamo come il collegamento con la scheda madre avvenga attraverso link PCI Express 16x anche di tipo Gen 3, interfaccia che diventerà progressivamente popolare nel corso del 2012 con la disponibilità delle architetture Intel della famiglia Ivy Bridge. Nella tabella seguente abbiamo messo a confronto le specifiche tecniche principali delle schede Radeon HD 6970 (Cayman) e Radeon HD 7970 (Tahiti), evidenziandone le principali differenze.
| Radeon HD 6970 | Radeon HD 7970 | Note | |
processo produttivo |
40nm | 28nm | la scheda Radeon HD 7970 è la prima ad utilizzare tecnologia produttiva a 28 nanometri, con produzione della taiwanese TSMC |
Transistor |
2,64 miliardi | 4,31 miliardi | i transistor sono aumentati del 63% rispetto alla GPU di precedente generazione |
clock GPU |
880 MHz | 925 MHz | marginale incremento nella frequenza di clock massima, pari al 5% |
stream processors |
1.536 | 2.048 | gli stream processors son aumentati del 33% |
potenza computazionale |
2,70 TeraFLOPS | 3,79 TeraFLOPS | questo risultato è frutto dell'incremento nella frequenza di clock e nel numero di stream processors |
| texture units | 96 | 128 | le texture units sono crescite in modo proporzionale agli stream processors |
| texture fillrate | 84,5 GT/s | 118,4 GT/s | dinamica identica anche per il texture fillrate, aumentato per incidenza nel numero delle texture unit e per la frequenza di clock |
| ROPs | 32 | 32 | invariate ne ROPs |
| Pixel Fillrate | 28,16 GP/s | 29,6 GP/s | l'aumento del pixel fillrate è tutto dovuto alla maggiore frequenza di clock della GPU |
| bus memoria video | 256bit | 384bit | incremento del 50% di questo componente, con dirette ripercussioni sulla bandwidth massima a disposizione |
| quantità memoria video | GDDR5 2 Gbytes |
GDDR5 3 Gbytes |
aumenta del 50% il quantitativo di memoria onboard, per via dell'incremento nel bus memoria |
| clock effettivo memoria video | 5.500 MHz | 5.500 MHz | non varia la frequenza di clock della memoria video, sempre a 5.500 MHz: si tratta di un risultato di rilievo in considerazione dell'accresciuta complessità del bus passato a 384bit |
| bandwidth memoria video | 176 GB/s | 264 GB/s | parallelo incremento del 50%, viste le precedenti caratteristiche tecniche, anche per la bandwidth totale della memoria video |

In ottica GPU Computing sono varie le novità introdotte da AMD nell'architettura Southern Island: troviamo due compute engines di tipo asincrono, capaci di schedulare processi in modo indipendente operando in parallelo con il graphics commend processor. Due DMA engines collegano i due compute engines di tipo asincrono con la cache L2: il quantitativo di 768 Kbytes è molto elevato per un'architettura di GPU e lascia intendere come sia un componente implementato proprio per migliorare le prestazioni in ambito di GPU Computing.
Le prestazioni con double precision giungono sino ad un picco di 947 GigaFlops, valore pari a 1/4 della potenza in single precision. Per completare il pacchetto di funzionalità specifiche AMD ha integrato piena protezione ECC sia per la memoria DRAM sia per le cache integrate nella GPU.
 Mario Kart World lancia Switch 2: la magia Nintendo ora in 4K
Mario Kart World lancia Switch 2: la magia Nintendo ora in 4K La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025
La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025 SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni
SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni Vertiv amplia la gamma CoolChip CDU con nuovi dispositivi per il raffreddamento a liquido
Vertiv amplia la gamma CoolChip CDU con nuovi dispositivi per il raffreddamento a liquido  Trump rilancia sui social: "Biden è morto nel 2020 ed è stato sostituito da un robot"
Trump rilancia sui social: "Biden è morto nel 2020 ed è stato sostituito da un robot" Photoshop sbarca anche su Android: Adobe apre la beta pubblica dellapp completa
Photoshop sbarca anche su Android: Adobe apre la beta pubblica dellapp completa The Witcher 4: la nuova Gameplay Tech Demo mostra il pieno potenziale di Unreal Engine 5 e del nuovo titolo CDPR
The Witcher 4: la nuova Gameplay Tech Demo mostra il pieno potenziale di Unreal Engine 5 e del nuovo titolo CDPR Agentic Experience, l'IA basata su agenti secondo Qlik
Agentic Experience, l'IA basata su agenti secondo Qlik LG OLED Serie C4 2024: cinema e gaming al top con il 4K a 144Hz, ora in offerta su Amazon
LG OLED Serie C4 2024: cinema e gaming al top con il 4K a 144Hz, ora in offerta su Amazon La FDA lancia Elsa: l'intelligenza artificiale entra nell'agenzia che vigila su farmaci e alimenti negli USA
La FDA lancia Elsa: l'intelligenza artificiale entra nell'agenzia che vigila su farmaci e alimenti negli USA Prato perfetto con Sunseeker Elite X7, il robot tagliaerba definitivo con AI
Prato perfetto con Sunseeker Elite X7, il robot tagliaerba definitivo con AI WordPress forma un team AI per l'integrazione dell'intelligenza artificiale nel core della piattaforma
WordPress forma un team AI per l'integrazione dell'intelligenza artificiale nel core della piattaforma HONOR 200 Lite a 179 su Amazon: display luminoso e fotocamera 108 MP a prezzo contenuto
HONOR 200 Lite a 179 su Amazon: display luminoso e fotocamera 108 MP a prezzo contenuto WWDC 2025, se vi aspettate una rivoluzione in ambito IA potreste rimanere delusi
WWDC 2025, se vi aspettate una rivoluzione in ambito IA potreste rimanere delusi One UI 7, non vi piacciono alcune novità? Ecco due modifiche che potete annullare
One UI 7, non vi piacciono alcune novità? Ecco due modifiche che potete annullare HUAWEI Pura 80, è ufficiale: la nuova serie flagship sarà lanciata l'11 giugno in Cina
HUAWEI Pura 80, è ufficiale: la nuova serie flagship sarà lanciata l'11 giugno in Cina


























