





Unicode è la codifica più utilizzata sul Web

Sul Web il tasso d'adozione della codifica Unicode ha superato quello dello standard ASCII, parola di Google
di Fabio Gozzo pubblicata il 08 Maggio 2008, alle 11:45 nel canale WebMark Davis, senior international software architect di Google, è di recente intervenuto sul blog ufficiale della compagnia di Mountain View con alcune interessanti considerazioni sugli standard di codifica dei caratteri attualmente utilizzati sul Web.
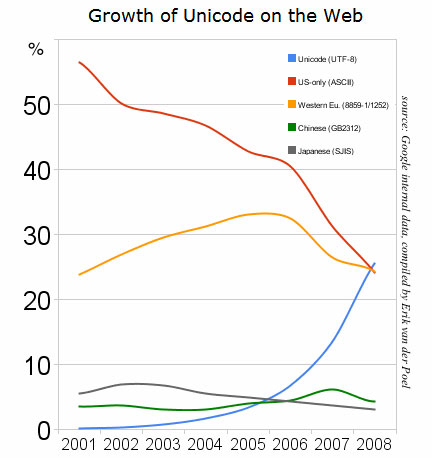
Basandosi su informazioni interne della compagnia, Davis afferma che attualmente lo standard più popolare per la codifica dei caratteri delle pagine Web non è più l'ASCII (American Standard Code for Information Interchange) ma l'Unicode.
Fonte: Google
In accordo con i dati rilasciati da Google, il sorpasso della codifica Unicode è avvenuto lo scorso dicembre e, nonostante il vantaggio sia tuttora minimo, è frutto di una crescita significativa è costante avvenuta nell'arco degli ultimi 3 anni.
La lenta ma graduale migrazione verso Unicode è in atto ormai da molto tempo e non è certo una sorpresa. Il sistema di codifica ASCII esteso utilizza 8 bit di memoria per memorizzare un singolo carattere ed è in grado di rappresentare solamente 256 simboli. Questa limitazione del formato ha portato alla nascita di diverse versioni dello standard al fine di soddisfare le diverse esigenze dei ceppi linguistici esistenti.
Per far fronte alla frammentazione e ai problemi di conversione dovuti all'esistenza di differenti versioni dello standard ASCII, è nato Unicode, un formato che si prefigge di poter rappresentare tutti i caratteri esistenti. Questo sistema di codifica è stato infatti pensato per poter essere facilmente espanso ed aggiornato, garantendo sempre la retrocompatibilità con le precedenti versioni. Attualmente sono utilizzate le codifiche a 8, 16 o 32 bit, indicate rispettivamente con le sigle UTF-8, UTF-16 e UTF-32.
La convergenza del Web verso il più recente standard di codifica Unicode riduce notevolmente le problematiche legate alla visualizzazione di differenti alfabeti, tuttavia ha come svantaggio una maggiore occupazione di memoria rispetto allo standard ASCII per la memorizzazione di un singolo carattere.

 HONOR CHOICE Projector Air Pro: piccolo, portatile e con Netflix
HONOR CHOICE Projector Air Pro: piccolo, portatile e con Netflix ASUS ProArt GoPro Edition è il notebook compatto per chi crea
ASUS ProArt GoPro Edition è il notebook compatto per chi crea Fable e Sol a confronto: due cartoni animati creati su un PC con RTX 3090
Fable e Sol a confronto: due cartoni animati creati su un PC con RTX 3090 OpenAI taglia i prezzi di due modelli GPT-5.6: Luna costa l'80% in meno dopo 3 settimane dal lancio
OpenAI taglia i prezzi di due modelli GPT-5.6: Luna costa l'80% in meno dopo 3 settimane dal lancio RTX Spark pronto a dominare anche i tablet? Spuntano le immagini di un convertibile Lenovo
RTX Spark pronto a dominare anche i tablet? Spuntano le immagini di un convertibile Lenovo Il primo telefono davvero senza bordi non è di Apple, né di Samsung: ma è ancora un concept
Il primo telefono davvero senza bordi non è di Apple, né di Samsung: ma è ancora un concept DeepSeek V4-Flash, API in beta pubblica: il modello cinese piccolo è migliore di quello grande?
DeepSeek V4-Flash, API in beta pubblica: il modello cinese piccolo è migliore di quello grande? Dati su disfunzione erettile e perdita di peso condivisi con Meta, dice la FTC
Dati su disfunzione erettile e perdita di peso condivisi con Meta, dice la FTC Arriva e-invoice, il servizio di fiskaly che unisce fatturazione elettronica e corrispettivi
Arriva e-invoice, il servizio di fiskaly che unisce fatturazione elettronica e corrispettivi Champions League, F1 e MotoGP: ecco la promo estiva di Sky Sport a 24,99
Champions League, F1 e MotoGP: ecco la promo estiva di Sky Sport a 24,99 Amazon alza a 220 miliardi le stime sugli investimenti in IA, ma potrebbero non bastare
Amazon alza a 220 miliardi le stime sugli investimenti in IA, ma potrebbero non bastare World of Warcraft e Dungeons & Dragons insieme: il crossover che molti aspettavano è realtà
World of Warcraft e Dungeons & Dragons insieme: il crossover che molti aspettavano è realtà AXOL Server ridisegna l'infrastruttura di Centrogest: Proxmox e backup immutabile
AXOL Server ridisegna l'infrastruttura di Centrogest: Proxmox e backup immutabile MSI ha ucciso AMD EXPO ULL? High-Efficiency Mode, la modalità che fa volare i 'vecchi' kit RAM
MSI ha ucciso AMD EXPO ULL? High-Efficiency Mode, la modalità che fa volare i 'vecchi' kit RAM Falso Portale dell'Automobilista ruba patenti e codici fiscali: attenti al phishing
Falso Portale dell'Automobilista ruba patenti e codici fiscali: attenti al phishing Apple chiude il miglior trimestre di giugno della sua storia, poi arriva la doccia fredda
Apple chiude il miglior trimestre di giugno della sua storia, poi arriva la doccia fredda



























24 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoCosì poi servivano 20 versione del sito...
quando è che ci passa anche hwupgrade?
Tutte le altre lingue hanno gli accenti, e lettere "strane" per non parlare delle lingue con scrittura diversa dai caratteri romani...
Per me sono pochi i siti che usano Unicode...
Occupa più byte solo quando si passa dal 128° carattere in poi, prima occupa 1B. In base al valore dei bit più significativi si sa quanti byte formano il prossimo carattere.
Se usiamo solo caratteri presenti in ASCII standard la dimensione del testo sarà identica. Se usiamo solo caratteri NON presenti sarà almeno il doppio.
Non è uno svantaggio la dimensione dei caratteri perchè non c'è altro modo per rappresentare i caratteri se non aumentando la quantità di bit necessari per descriverli. Il vantaggio è invece l'eliminazione dei byte non necessari alla rappresentazione.
UTF-32 contiene caratteri lunghi 8, 16, 24 E 32bit.
Occupa più byte solo quando si passa dal 128° carattere in poi, prima occupa 1B. In base al valore dei bit più significativi si sa quanti byte formano il prossimo carattere.
Se usiamo solo caratteri presenti in ASCII standard la dimensione del testo sarà identica. Se usiamo solo caratteri NON presenti sarà almeno il doppio.
Non è uno svantaggio la dimensione dei caratteri perchè non c'è altro modo per rappresentare i caratteri se non aumentando la quantità di bit necessari per descriverli. Il vantaggio è invece l'eliminazione dei byte non necessari alla rappresentazione.
UTF-32 contiene caratteri lunghi 8, 16, 24 E 32bit.
*
UTF Rulezz
Occupa più byte solo quando si passa dal 128° carattere in poi, prima occupa 1B. In base al valore dei bit più significativi si sa quanti byte formano il prossimo carattere.
Se usiamo solo caratteri presenti in ASCII standard la dimensione del testo sarà identica. Se usiamo solo caratteri NON presenti sarà almeno il doppio.
Non è uno svantaggio la dimensione dei caratteri perchè non c'è altro modo per rappresentare i caratteri se non aumentando la quantità di bit necessari per descriverli. Il vantaggio è invece l'eliminazione dei byte non necessari alla rappresentazione.
UTF-32 contiene caratteri lunghi 8, 16, 24 E 32bit.
Interessante. Visto che sembri ferrato in materia, ti faccio una domanda: apro un documento di testo in formato ANSI con Notepad (sono su una macchina con Windows XP), lo salvo in Unicode e la dimensione del file raddoppia. Il file contiene solo caratteri ASCII standard (ho fatto una prova scrivendo una serie di aaaaaaaaaaaaaa bbbbbbbbbbbbb cccccccccccc copiata ed incollata n volte per renderlo un po' corposo). Colpa di come Notepad / Windows gestiscono Unicode o dipende da qualcos'altro?
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".