





|
|||||||


|



|
|
 |
|
|
Strumenti |
 09-09-2008, 17:15
09-09-2008, 17:15
|
#1 |
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Alcuni dubbi tecnici sulle attuali GPU...
Chi è in grado di rispondere alle seguenti domande? Una volta avrei potuto rispondere io stesso, ma purtroppo è da un bel po' che non sono più informatissimo sulle evoluzioni tecnologiche delle GPU ATi e nVidia... Ad ogni modo, ecco le domande:
1) Come mai le schede ATi, pur avendo un numero spropositato di unità shader unificate, è da un po' di anni mi pare che, tranne che per l'ultima serie 48xx, vanno peggio delle schede nVidia, le quali invece hanno unità shader in quantità notevolmente inferiore? 2) Come mai ATi continua a proporre schede video di fascia media con oltre 100 unità shader unificate, ma 4 rop invece che 8 ? Non è sprecato avere tutte quelle unità shader, se poi hai in uscita un notevole collo di bottiglia rappresentato dal pixel throughput dimezzato rispetto alla concorrenza? Finché la tipica risoluzione usata nei videogiochi era 1024x768 potevo anche capire, ma oggi la minima risoluzione è diventata 1280x800 (risoluzione standard di un notebook 15.4") ed i monitor LCD wide vanno da 1440x900 in su...
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |

|

|
|
09-09-2008, 18:05
|
#2 | ||
|
Bannato
Iscritto dal: Jun 2007
Messaggi: 1186
|
Quote:
Detto in modo moooolto semplice il rapporto di potenza tra un'unità shader nvidia ed una Ati è 1:2 ma ripeto, è troppo semplicistica come spiegazione, le due aziende hann oadottato approcci defferenti nella realizzazione delle proprie architetture. Quote:
|
||
|
|
|

|
09-09-2008, 18:44
|
#3 | ||
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Quote:
Quote:
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |
||
|
|
|
|
09-09-2008, 19:12
|
#4 |
|
Senior Member
Iscritto dal: Apr 2008
Città: La terra dei cachi
Messaggi: 3210
|
Probabilmente per entrambi i motivi...comunque visto il prezzo della 3650, di più non puoi aspettarti, sono delle oneste schede di fascia bassa.
|
|
|
|
|
09-09-2008, 19:20
|
#5 | |
|
Bannato
Iscritto dal: Jun 2007
Messaggi: 1186
|
Quote:
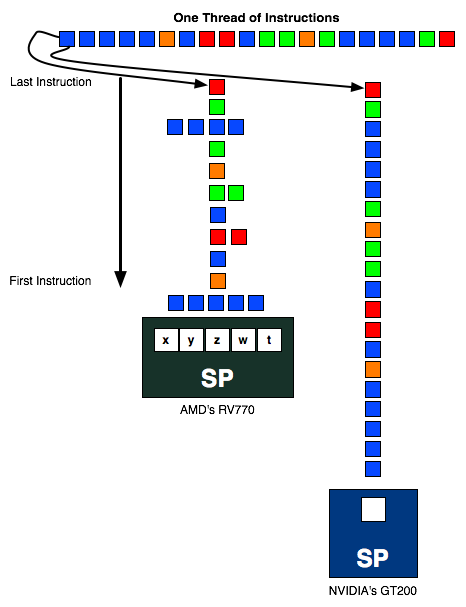
partiamo con due GPU attuali NVidia GT2xx Ati RV770 Il GTX280 ha come saprai 240 SP raggruppati a 8. Ognuno di questi raggruppamenti prende il nome di streaming multiprocessors. Un gruppo di 3 streaming multiprocessors viene indicato con il nome di thread processing cluster o TPC. Nel GTX280 abbiamo 10 TPC e 30 SM. Lo Streaming Processor progettato da AMD per la GPU RV770 invece è composto da un insieme 5 SM. La GPU RV770 dispone di 16 Streaming Processor per ogni Core SIMD. Quindi cambia strutturalmente il modo in cui sono organizzate internamente le GPU. Gli Stream Processing Unit sono tutti uguali e sono in grado di gestire operazioni di Multiply / ADD (la loro architettura deriva da quella di una unità FP MUL più una unità ADD). Questi blocchi sono praticamente identici a quelli utilizzati da NVIDIA nel chip GT200. Mentre GT200 dispone di 240 Stream Processor, RV770 ne prevede 800. Ma il blocco dell´RV770 più simile ad uno Stream Processor di NVIDIA non è la singola Stream Processing Unit bensì lo Streaming Processor: nell´RV770 ne troviamo 160. Questo significa che il confronto andrebbe fatto in maniera differente. GT200 dispone di 240 Streaming Processor in grado di gestire ognuno una istruzione alla volta. RV770 dispone di 160 Streaming Processor in grado di gestire fino a 5 istruzioni per ogni ciclo. La sola restrizione è che tutte le istruzioni facciano parte dello stesso thread. Ancora una volta sta ai programmatori con i propri drivers sfruttare in modo più o meno ottimale una determinata architettura. Un SIMD Core di RV770 può essere paragonato ad una unità SM del chip NVIDIA GT200 anche se con le dovute differenze. Il SIMD Core dispone di 16 SP mentre lo Streaming Multiprocessor ne prevede la metà. Inoltre, ogni SP dell´RV770 può processare 5 istruzioni alla volta contro una sola istruzione degli SP NVIDIA. Le texture units, comprese le texture cache sono accoppiate agli SP all´interno del SIMD Core, mentre nel chip GT200 queste sono posizionate al di fuori dello SM. Al contrario NVIDIA ha inserito nello SM la cache istruzioni e la cache delle costanti mentre AMD ha lasciato questi blocchi al di fuori. Con queste differenze architetturali, non è possibile rispondere con precisione alla tua domanda...posso però dirti che in totale RV770 può processare un massimo teorico di 800 istruzioni alla volta mentre GT200 ne può processare 240 (oltre ad ulteriori 240 attraverso le due unità SFU disponibili per ogni SM e solo in determinate situazioni). Ma i casi ottimale e peggiore differiscono molto prendendo in esame le due diverse architetture. Diciamo che nel caso migliore GT200 è capace di elaborare 480 istruzioni per ogni ciclo contro le 800 di RV770. Nel caso peggiore, però, l´architettura NVIDIA si ferma a 240 mentre quella AMD scende a 160. l´architettura NVIDIA preferisce lavorare su moltissimi thread semplici, composti da poche o meglio da una sola istruzione. L´approccio AMD mostra il meglio di sé, invece, con threads complessi e pieni di istruzioni. In aggiunta, l´architettura proposta da NVIDIA è sensibile solo al TLP, Thread Level Parallelism, che risulta abbastanza semplice da applicare e gestire per ottenere buoni risultati (l´estrazione del TLP deve tenere in considerazione solo i conflitti fra thread che si verificano quando questi devono condividere delle risorse). L´architettura AMD, invece, può essere sfruttata al meglio sia estraendo parallelismo a livello di thread, appunto TLP, che a livello di istruzioni (ILP o Thread Level Parallelism). Questo significa un maggiore sforzo di ottimizzazione da parte del Thread Scheduler che non sempre riuscirà a tenere la GPU AMD al massimo delle sue possibilità. Per concludere c'è la questione DX 10.1 ma in tal caso ognuno mostra pareri discordanti in merito quindi lascio a te la risposta, Spero che la spiegazione ti sia abbastanza chiara. Ultima modifica di tigershark : 09-09-2008 alle 19:26. |
|
|
|
|
|
09-09-2008, 20:50
|
#6 | ||
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Quote:
n. MAX teorico istruzioni per ciclo di clock; n. medio di istruzioni generate per ciclo di clock, prendendo in considerazione degli shader molto simili a quelli usati in giochi recenti. Poi, immagino che nel confronto fra i due concorrenti, entri in gioco anche il discorso della velocità di clock doppia per le shader unit delle GPU nVidia... Quote:
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |
||
|
|
|
|
10-09-2008, 09:47
|
#7 | |
|
Senior Member
Iscritto dal: Mar 2006
Messaggi: 8605
|
Quote:
 http://www.anandtech.com/video/showdoc.aspx?i=3341&p=6 Ma per ottenere quel risultato è necessario lavorare sui driver.
__________________
Steam Deck OLED 2 TB | Ryzen 7 7700 2x16GB Corsair Dominator Platinum 6400 MHz PowerColor Hellhound RX 7700 XT Trattative OK: 1mp3r4t0r, armenico11, Babumba92, CoolBits, Drigerott, gino1221, k.o.z, Macco, Mastermarcox, Mone_82, stacker, Velvet, Vladimiro Bentovich, frupoli, Sheva77, deg626, HcK190, Godmar, Simonxp, LCol84, pp2k, xeno the holy, SamuTnT, fantacaz |
|
|
|
|
|
10-09-2008, 09:55
|
#8 | |
|
Senior Member
Iscritto dal: Jan 2006
Messaggi: 4414
|
Quote:
L'unico modo per confrontare le schede è leggersi qualche recensione o farsi consigliare da qualcuno che l'ha lette. Al massimo nelle specifiche puoi vedere una variazione del clock rispetto al modello di riferimento. p.s. le 36xx stanno per essere sostituite dalle 46xx |
|
|
|
|
|
10-09-2008, 11:45
|
#9 | |
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Quote:
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |
|
|
|
|
|
13-09-2008, 14:49
|
#10 | ||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
RV770 ha unità di calcolo di tipo vliw, ovvero ognuna è composta da 5 alu capaci di eseguire una MADD (una di queste può, in alternativa, eseguire una sfu) e da una unità per il controllo di flusso, con un approccio di tipo parallelo. Questo significa che ogni unità di calcolo delle 160 presenti su una HD48x0 può eseguire contemporaneamente fino a 5 operazioni (più una per il dynamic branching) in parallelo, purchè siano relative allo stesso thread. In conclusione, mentre GT200 ha, in teoria, la possibilità di operare sempre al massimo delle proprie capacità di calcolo, RV770 ha una capacità di calcolo che può oscillare dalle 160 alle 800 operazioni matematiche per ciclo di clock. Altre differenze si hanno nelle operazioni di texturing: nVIDIA ha più unità di texture filtering mentre ATi ha più unità di texture address e fa uso di texture cache di tipo fully associative (mentre quelle di nVIDIA sono di tipo set associative 2-way): il primo approccio è di tipo brute force (punta sulla quantità di operazioni possibili) il secondo tende a ridurre a zero il rischio di cache miss. Differenti sono pure le rop's o RBE; quelle di nVIDIA sono ottimizzate per le operazioni di riempimento dello z-buffer (le unità preposte a svolgere le color ops sono in grado di fare anche z-ops, raddoppiando, di fatto, lo z-fillrate); quelle ATi sono ottimizzate per l'uso del MSAA box filter in modalità 4x e 8x avendo più unità di interpolazione lineare e più punti di "spilling". Sempre relativamente alle rop's i chip ATi hanno la possibilità di adoperare 2 differenti render target per color e z-ops: questo permette di risparmiare banda passante ed eseguire un passaggio di rendering in meno per l'applicazione di MSAA con motori grafici che fanno uso di deferred rendering. Altra differenza, infine, nel memory controller, di tipo simmetrico quello di nVIDIA con 8 canali da 64 bit (32+32) sia lato ram che lato gpu, asimmetrico quello di ATi con 4 canali lato ram e 32 lato gpu (il primo garantisce una canale più ampio verso le ram ma costituirebbe un collo di bottiglia in caso di utilizzo di ram veloci, il secondo presenta un canale enorme lato gpu, puntando sull'uso di ram veloci e sull'utilizzo di algoritmi per il rispermio di banda verso la ram (multirender target, tessellation, texture matrix, cubemap matrix, color compression soprattutto con MSAA attivo, ecc). Quote:
Ultima modifica di yossarian : 13-09-2008 alle 14:58. |
||
|
|
|
|
14-09-2008, 15:10
|
#11 | |
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Quote:
In conclusione, quindi, mi pare di capire che nVidia adotti un approccio più pratico, volto a dare risultati tangibili nell'immediato, mentre ATi preferisce guardare al futuro, sperando che la complessità degli shader aumenti molto più di quanto si aspetti nVidia. Devo dire, però, che non mi aspettavo che ATi adottasse una cache full-associative, visto che una set-associative odierna permette di risparmiare una quantità notevole di transistor ad un costo di performance praticamente trascurabile.
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |
|
|
|
|
|
14-09-2008, 20:09
|
#12 | ||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
Una set associative 4-way ha una complessità comparabile a quella di una fully associative, mentre una 2-way ha bisogno, comunque, di essere affiancata da un buon circuito di branching (che ne aumenta la complessità). |
||
|
|
|
|
14-09-2008, 20:54
|
#13 | ||
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Quote:
Quote:
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |
||
|
|
|
|
14-09-2008, 21:07
|
#14 |
|
Bannato
Iscritto dal: Dec 2003
Città: Monteveglio(Bo)
Messaggi: 10006
|
In RV770 per caso nelle rop's è stato reinserito il circuito di resolve per fare MSAA di tipo lineare? Io sapevo che in R600 e RV670 la avevano messo nello shader core,mentre in RV770 non so se è nelle rop's o nello shader core.
|
|
|
|
|
15-09-2008, 02:11
|
#15 | |||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
Questo tipo di filosofia è riscontrabile in tutto il chip se si fa un confronto tra le due architetture, tranne che nel caso delle unità di shading, dove la situazione è completamente ribaltata (efficienza per nVIDIA, approccio di tipo "brute force" per ATi). Quote:
|
|||
|
|
|
|
15-09-2008, 14:52
|
#16 |
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Ok, ma allora perché le schede nVidia di fascia media (tipo le 8600) usano il doppio delle ROP rispetto alle soluzioni ATi? Andrebbero uguale se ne avessero 4 invece di 8?
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |
|
|
|
|
15-09-2008, 15:52
|
#17 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Le rop's dei chip NV, se fossero la metà, impiegherebbero, per ogni frame, semplicemente il doppio del tempo a riempire lo z-buffer, cosa che avviene con quelle dei chip ATi che, però, riguadagnano con le operazioni successive (cosa che i chip NV non sarebbero in grado di fare). Domanda per domanda, tra una 260 e una 4870, il vantaggio nel pixel fillrate teorico è del 25% a vantaggio della prima (tenendo conto anche delle differenti frequenze di funzionamento); tale vantaggio dovrebbe aumentare per le operazioni in cui le rop's possono costituire un collo di bottiglia. Eppure non è affatto così, anzi ocn i filtri aumenta il vantaggio della 4870. Come te lo spieghi? |
|
|
|
|
|
15-09-2008, 16:30
|
#18 | ||
|
Senior Member
Iscritto dal: Mar 2005
Messaggi: 4959
|
Quote:
Quote:
__________________
Cerchi software open source? Vieni su OpenWanted e aiutami a creare la Lista Open!! -> Elenco BUG di Windows 7 <- |
||
|
|
|
|
15-09-2008, 19:20
|
#19 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
|
|
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 09:14.















