





Radeon serie X1000: le nuove GPU ATI

Dopo una lunga attesa, ATI presenta le prime soluzioni video basate su architetture R520, RV530 e RV515, destinate a rivoluzionare tutti e 3 i principali segmenti di mercato. Architettura Shadel Model 3.0 e processo produttivo a 90 nanometri caratterizzano queste tecnologie, qui analizzate nell'architettura
di Paolo Corsini , Raffaele Fanizzi pubblicato il 05 Ottobre 2005 nel canale Schede VideoATIRadeonAMD
Un nuovo memory controller
L'efficienza dell'architettura di un chip video può trovare, nel controller memoria, un importante collo di bottiglia alle prestazioni. Per questo motivo ATI ha introdotto un nuovo memory controller nelle schede Radeon X1000, completamente rinnovato rispetto a quello implementato nelle architetture R4xx.
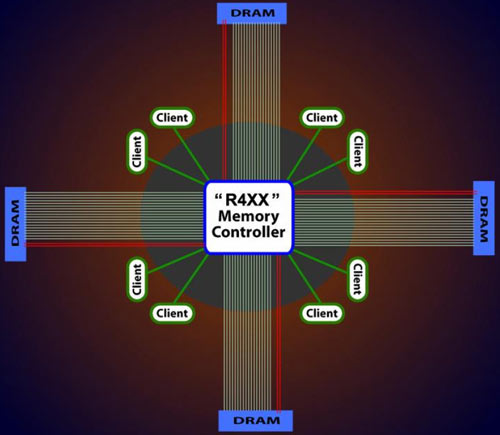
memory controller R4xx
Il controller memoria delle schede Radeon basate su chip R4xx prevedeva che tutte le chiamate fatte dai vari client a dati contenuti nella memoria, dovessero passare in modo centralizzato attraverso il memory controller. Questo approccio, visivamente riassunto nello schema qui sopra riportato, ha quale chiaro collo di bottiglia la necessità di far passare tutti i comandi all'interno del controller memoria, con possibile introduzione di latenza nel caso in cui i comandi aumentino di numero nell'unità di tempo.
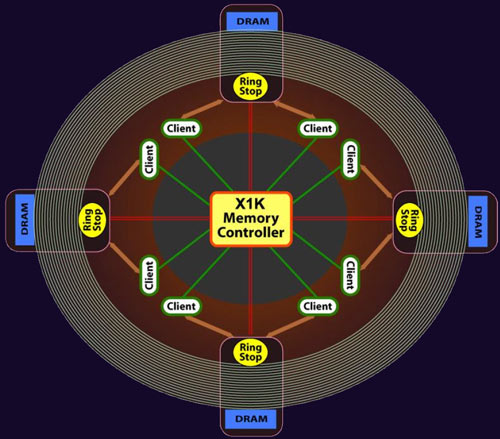
memory controller R5xx
Il memory controller implementato nelle architetture Radeon 1000, viceversa, parte da un approccio differente. Il controller, chiamato X1K, è posto al centro ma i vari client possono ottenere i dati direttamente senza che questi debbano ritornare al memory controller. Spieghiamo il funzionamento con un esempio: un client richiede al memory controller dei dati presenti nella memoria; quest'ultimo stabilisce quale sia la memoria DRAM che può eseguire questa richiesta, e invia il comando. Il dato richiesto parte dalla memoria DRAM individuata, spostandosi lungo il bus ring (l'anello esterno nello schema) sino a giungere al ring stop più vicino al client che ha eseguito quella richiesta.
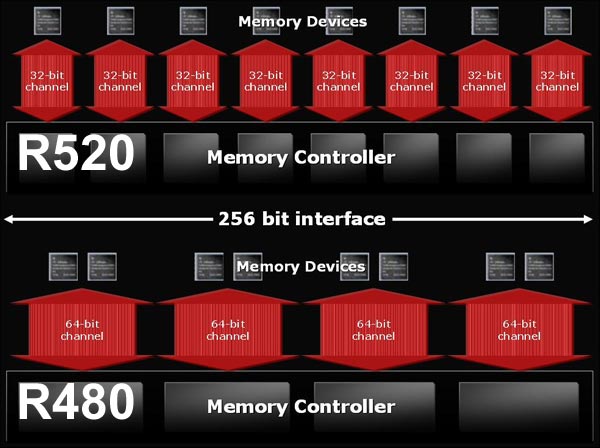
Il nuovo memory controller con ring bus a 512bit non dev'essere confuso con un memory controller a 512bit di ampiezza; quello implementato nella soluzione R520 è infatti del tipo a 256bit, esattamente come per le architetture NVIDIA di pari fascia di prezzo. Il memory controller opera quindi con la stessa ampiezza di banda di quello previsto per le soluzioni R480, ma ha connessioni dirette con i chip DRAM a 32bit per ciascun chip memoria montato sulla scheda, rispetto ad un approccio con 4 canali a 64bit di ampiezza, che gestiscono ciascuno 2 chip memoria.
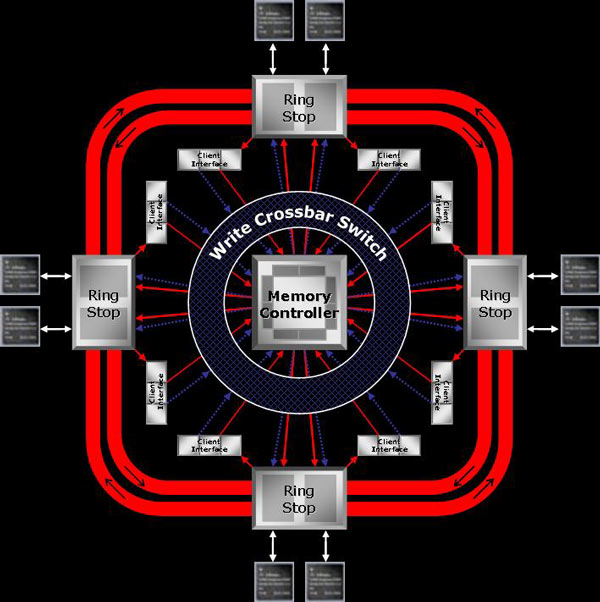
Il memory controller implementa, stando alle informazioni forniteci da ATI, varie
funzionalità di Arbitrarion che dovrebbero permettere di ottenere una migliore efficienza
complessiva nella ricerca dei dati da fornire ai vari client, a seconda delle richieste da
questi fatte.
Il memory controller può inoltre venir aggiornato nella propria logica di gestione
arbitraria, attraverso nuove versioni di driver. A seconda delle applicazioni, le
richieste dei vari client possono essere pesate tra di loro; questo implica che il memory
controller esegue con priorità massima particolari richieste dei client che considera
essere prioritarie rispetto ad altre.


Non contenta di aver stravolto il funzionamento del memory controller, ATI ha eseguito un’ulteriore profonda ottimizzazione di tutte le operazioni di gestione dei dati lavorando innanzitutto sul quantitativo e sulla tipologia di cache implementata. In particolare, tutti i processori grafici visti fino ad ora utilizzano cache con mappatura diretta o associativa a N vie. Il nuovo memory controller, invece, include una cache di tipo “full associative” in grado di far riferimento non solo ad un blocco di memoria limitato, ma virtualmente alla totalità della memoria. Conseguenza di tale funzionamento è una significativa riduzione delle richieste verso la banda passante esterna ed un più efficiente utilizzo di quest’ultima. ATI ha stimato in casi bandwidth bound, cioè limitati dalla banda passante, un incremento dell’efficienza complessiva del 25% grazie a questa nuova architettura della cache.

Concludiamo l’analisi delle novità del memory controller analizzando le innovazioni apportate alla tecnologia Hyper-Z. Gli ingegneri canadesi hanno fatto uso della precisione di calcolo in floating point a 32 bit per migliorare le loro tecniche di Hidden Superficial Removal, cioè di rimozione delle superfici nascoste: la nuova architettura alla base di R520 identifica fino a 65% di pixel nascosti in più rispetto a R480. Infine, anche gli algoritmi di compressione dei dati relativi allo z-buffer sono migliorati ed ora raggiungono il livello di compressione più elevato (8:1) in più occasioni.
La totalità di queste innovazioni rende R520 estremamente efficiente nella gestione della banda passante, un vantaggio particolarmente significativo nel rendering alle alte risoluzioni e con antialiasing e filtro anisotropico abilitati.
 La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025
La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025 SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni
SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni Dalle radio a transistor ai Micro LED: il viaggio di Hisense da Qingdao al mondo intero
Dalle radio a transistor ai Micro LED: il viaggio di Hisense da Qingdao al mondo intero 'Napalm Girl': 400 fotografi contro la decisione del WPP di sospendere la paternità di Nick Ut
'Napalm Girl': 400 fotografi contro la decisione del WPP di sospendere la paternità di Nick Ut Gli italiani ce l'hanno più piccolo della media europea (il televisore)
Gli italiani ce l'hanno più piccolo della media europea (il televisore) Google Maps cambia logo nell'interfaccia mobile: ecco la piccola novità
Google Maps cambia logo nell'interfaccia mobile: ecco la piccola novità Windows 11 in calo a maggio, mentre cresce Windows 10 che a ottobre non sarà più supportato
Windows 11 in calo a maggio, mentre cresce Windows 10 che a ottobre non sarà più supportato Qual è lo smartphone più venduto in Europa? La TOP 10 è dominata due marchi
Qual è lo smartphone più venduto in Europa? La TOP 10 è dominata due marchi ECOVACS DEEBOT T50 PRO OMNI: il robot aspirapolvere da 15.000 Pa con lavaggio ad acqua calda è in offerta su Amazon a soli 699
ECOVACS DEEBOT T50 PRO OMNI: il robot aspirapolvere da 15.000 Pa con lavaggio ad acqua calda è in offerta su Amazon a soli 699 Apple Watch: tutte le offerte su Amazon a Giugno! Series 10 da 46mm a soli 359, sconti anche su Series 9 e SE
Apple Watch: tutte le offerte su Amazon a Giugno! Series 10 da 46mm a soli 359, sconti anche su Series 9 e SE La Via Lattea e la galassia di Andromeda potrebbero non scontrarsi secondo nuovi dati di Hubble e Gaia
La Via Lattea e la galassia di Andromeda potrebbero non scontrarsi secondo nuovi dati di Hubble e Gaia Samsung, finisce l'idillio con Google? Su Galaxy S26 potrebbe arrivare Perplexity al posto di Gemini
Samsung, finisce l'idillio con Google? Su Galaxy S26 potrebbe arrivare Perplexity al posto di Gemini Squid Game 3, il trailer della terza stagione è qui! Trama, cast e data di uscita
Squid Game 3, il trailer della terza stagione è qui! Trama, cast e data di uscita Speciale offerte videocamere e webcam Insta360: 6 modelli tra 4K, 8K, POV e panoramiche a 360°
Speciale offerte videocamere e webcam Insta360: 6 modelli tra 4K, 8K, POV e panoramiche a 360° Microsoft annuncia diverse novità su Windows in Europa, per una maggiore adesione al DMA
Microsoft annuncia diverse novità su Windows in Europa, per una maggiore adesione al DMA Stranger Things 5: ecco il trailer e la data di uscita della stagione finale su Netflix
Stranger Things 5: ecco il trailer e la data di uscita della stagione finale su Netflix Sconti PlayStation 5 su Amazon: Slim con 2 DualSense a 459, PS VR2 a 399 e PS5 Pro in offerta a 749
Sconti PlayStation 5 su Amazon: Slim con 2 DualSense a 459, PS VR2 a 399 e PS5 Pro in offerta a 749


























