





Llama 3, Meta introduce il Large Language Model open source più potente di tutti: sfida Google e OpenAI

Meta Llama 3 è il nuovo LLM della società guidata da Mark Zuckerberg. Completamente open source, sfida le soluzioni di Google e OpenAI: è stato addestrato su due cluster con oltre 24.000 GPU NVIDIA.
di Manolo De Agostini pubblicata il 19 Aprile 2024, alle 08:31 nel canale WebMeta
Meta ha annunciato la disponibilità in modalità open source di Llama 3, la nuova generazione del potente modello linguistico di grandi dimensioni (Large Language Model).
Secondo la società guidata da Mark Zuckerberg, che ha annunciato Llama 3 e altre novità correlate sul proprio profilo Facebook, questa versione presenta "modelli linguistici pre-addestrati e ottimizzati per seguire istruzioni con 8B e 70B parametri, in grado di supportare un'ampia gamma di applicazioni d'uso". Non solo, sul sito dell'annuncio si legge un inequivocabile: "Crediamo che questi siano i migliori modelli open source della loro classe, punto".

Con Llama 3, Meta rende disponibili modelli aperti che puntano a essere alla pari con i migliori modelli proprietari attuali. "I modelli testuali che rilasciamo oggi sono i primi della collezione di modelli Llama 3. Il nostro obiettivo nel prossimo futuro è rendere Llama 3 multilingue e multimodale, avere una finestra di contesto più lunga e continuare a migliorare le prestazioni complessive delle funzionalità LLM fondamentali come il ragionamento e la codifica".
Meta ha diffuso anche alcuni dati comparativi che vedono Llama 3 svettare sui modelli di Google e Mistral. Inoltre, i nuovi modelli Llama 3 con parametri 8B e 70B rappresentano un grande passo avanti rispetto a Llama 2, e sono il risultato di miglioramenti apportati al pre-addestramento e al post-addestramento.
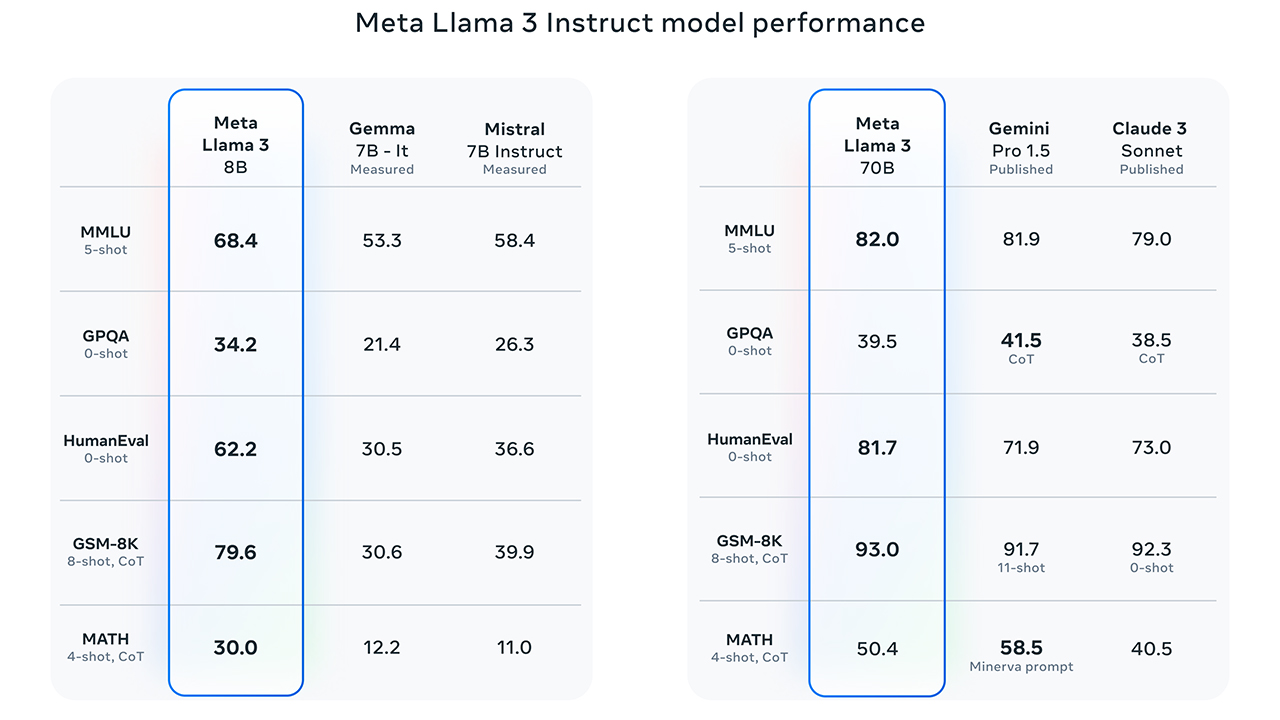
Clicca per ingrandire
Per sviluppare Llama 3, Meta ha creato un nuovo set di valutazione umana di alta qualità. Questo set di valutazione contiene 1.800 suggerimenti che coprono 12 casi d'uso chiave: richiesta di consigli, brainstorming, classificazione, risposta a domande chiuse, codifica, scrittura creativa, estrazione, interpretazione di un personaggio/persona, risposta a domande aperte, ragionamento, riscrittura e sintesi. Il grafico seguente mostra i risultati aggregati delle valutazioni umane in queste categorie e prompt rispetto a Claude Sonnet, Mistral Medium e GPT-3.5 (non GPT-4).
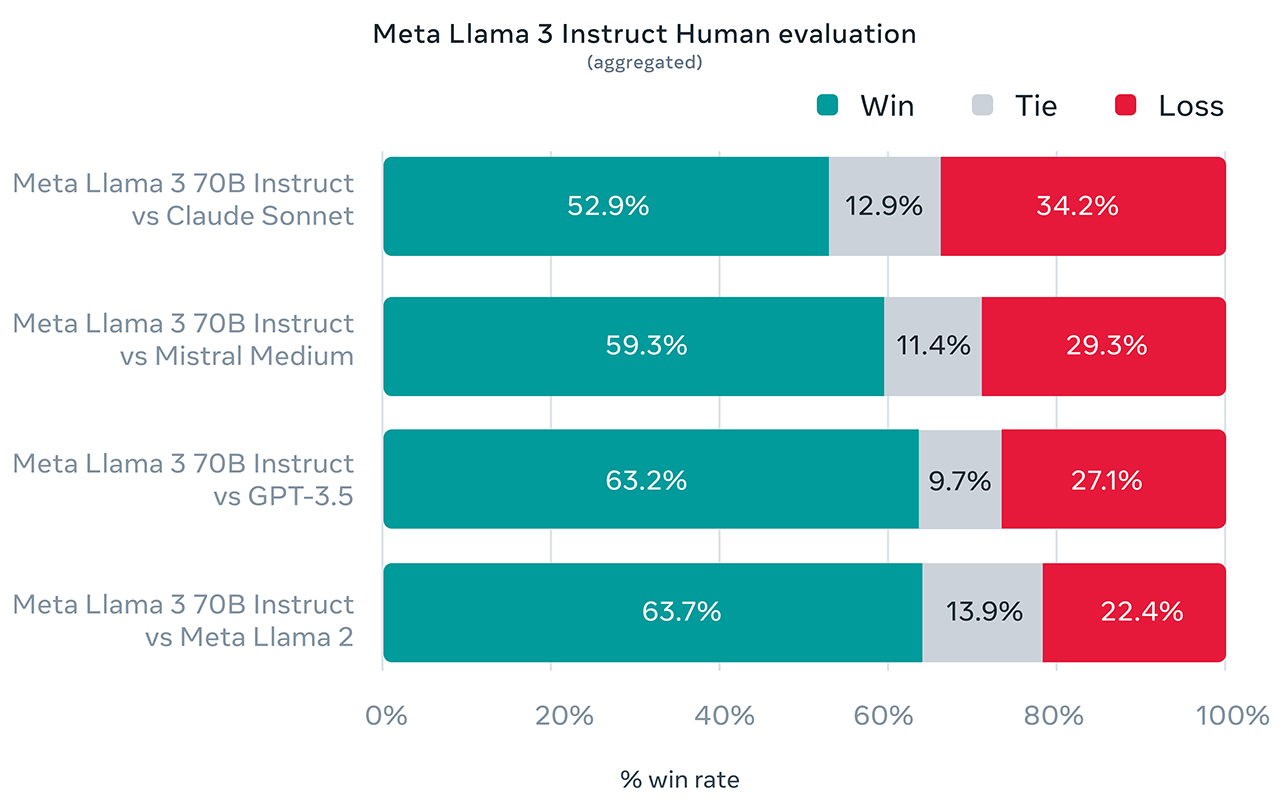
Clicca per ingrandire
"Il ranking delle preferenze da parte di annotatori umani basato su questo set di valutazione evidenzia le ottime prestazioni del nostro modello 70B rispetto ai modelli concorrenti di dimensioni comparabili in scenari del mondo reale. Il nostro modello pre-addestrato stabilisce inoltre un nuovo stato dell'arte per i modelli LLM su queste scale", spiega Meta.

Clicca per ingrandire
I risultati sono frutto di diversi miglioramenti chiave come "un tokenizzatore con un vocabolario di 128.000 token che codifica il linguaggio in modo molto più efficiente, il che porta a prestazioni del modello sostanzialmente migliorate". Meta afferma che i benchmark "mostrano che il tokenizzatore offre una migliore efficienza dei token, producendo fino al 15% in meno di token rispetto a Llama 2".
Per migliorare l'efficienza di inferenza dei modelli Llama 3, Meta ha adottato le Group Query Attention (GQA) nelle dimensioni 8B e 70B, addestrando i modelli su sequenze di 8192 token. "Abbiamo osservato che nonostante il modello abbia 1 miliardo di parametri in più rispetto a Llama 2 7B, l'efficienza del tokenizzatore e il GQA migliorato contribuiscono a mantenere l'efficienza dell'inferenza alla pari con Llama 2 7B".
Meta ha inoltre investito molto nei dati di pre-addestramento. "Llama 3 è preaddestrato su oltre 15T token, tutti raccolti da fonti disponibili al pubblico. Il nostro set di dati di addestramento è sette volte più grande di quello utilizzato per Llama 2 e include quattro volte più codice. Per prepararsi ai futuri casi d'uso multilingue, oltre il 5% del set di dati di pre-addestramento di Llama 3 è costituito da dati non inglesi di alta qualità che coprono oltre 30 lingue. Tuttavia, non ci aspettiamo lo stesso livello di prestazioni in queste lingue come in inglese".
Per garantire che Llama 3 sia addestrato su dati della massima qualità, Meta ha sviluppato una serie di pipeline di filtraggio dei dati usando Llama 2 per "generare i dati di addestramento per i classificatori di qualità del testo che stanno alimentando Llama 3".
Esperimenti approfonditi hanno permesso di combinare dati provenienti da diverse fonti al set di dati di pre-addestramento finale. "Questi esperimenti ci hanno permesso di selezionare un mix di dati che garantisce che Llama 3 funzioni bene in tutti i casi d'uso, tra cui domande trivia, STEM, codifica, conoscenza storica, ecc", afferma Meta.
Gli ingegneri di Meta hanno addestrato Llama 3 su due cluster contenenti un totale di 24.576 GPU NVIDIA H100 Tensor Core, collegate a una rete NVIDIA Quantum-2 InfiniBand. Con il supporto di NVIDIA, Meta ha ottimizzato la rete, il software e le architetture dei modelli. In future, per far avanzare ulteriormente lo stato dell'arte dell'intelligenza artificiale generativa, Meta scalerà la propria infrastruttura fino a 350.000 GPU H100.
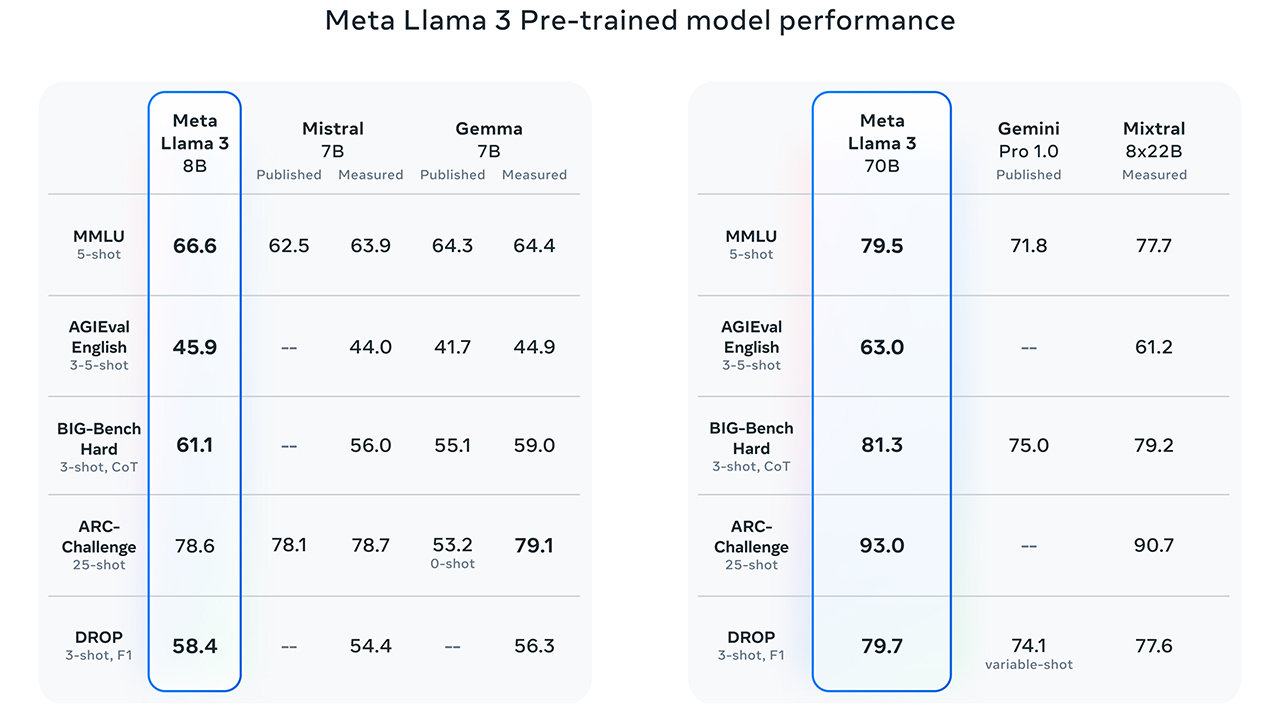
Clicca per ingrandire
"Ci siamo impegnati a sviluppare Llama 3 in modo responsabile e stiamo offrendo diverse risorse per aiutare le persone a utilizzarlo in modo altrettanto responsabile, tra cui nuovi strumenti di protezione e sicurezza con Llama Guard 2, Code Shield e CyberSec Eval 2. Nei prossimi mesi, prevediamo di introdurre nuove funzionalità, finestre contestuali più lunghe, ulteriori dimensioni del modello e prestazioni più elevate. Abbiamo anche avviato l'addestramento di Llama 3 su un modello con 400B parametri".
I modelli di Llama 3 saranno presto disponibili su AWS, Databricks, Vertex AI di Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA e Snowflake, con il supporto delle piattaforme hardware offerte da AMD, AWS, Dell, Intel, NVIDIA e Qualcomm.
NVIDIA è già pronta per Llama 3

In un post, NVIDIA afferma che una singola GPU NVIDIA H200 Tensor core ha generato circa 3000 token al secondo, abbastanza per servire simultaneamente 300mila utenti - in un test iniziale usando Llama 3 con 70B di parametri. "Questo significa che un singolo server NVIDIA HGX con otto GPU H200 può fornire 24.000 token al secondo e supportare oltre 2400 utenti nello stesso momento". Per i dispositivi edge, la versione con 8 miliardi di parametri di Llama 3 ha generato fino a 40 token al secondo su Jetson AGX Orin e 15 token al secondo su Jetson Orin Nano.
Anche Intel accoglie Llama 3
Contestualmente all'annuncio di Meta, Intel ha dichiarato di aver validato il suo portfolio di prodotti IA per i primi modelli Llama 3 8B e 70B sugli acceleratori Gaudi, i processori Xeon, Core Ultra e sulle schede video Arc. La casa di Santa Clara ha condiviso alcuni benchmark che chi è interessato può trovare a questo indirizzo.


In particolare, Intel segnala che i processori Intel Xeon 6 di prossimo arrivo, le soluzioni Granite Rapids basate interamente su P-core, "mostrano un miglioramento di 2 volte nella latenza di inferenza su Llama 3 8B rispetto ai processori Xeon di 4a generazione e la capacità di eseguire LLM come Llama 3 70B sotto i 100 ms per token generato". Infine, i processori Core Ultra "generano già velocità di lettura migliori rispetto a quelle tipiche di un essere umano".
Qualcomm e Meta insieme per Llama 3
Qualcomm Technologies e Meta hanno annunciato che collaboreranno per permettere l'esecuzione dei modelli LLM di Meta Llama 3 direttamente su smartphone, PC, visori VR/AR, veicoli e altro ancora. "La possibilità di eseguire Llama 3 sui dispositivi offre vantaggi significativi, tra cui reattività superiore, maggiore privacy, maggiore affidabilità ed esperienze più personalizzate per gli utenti", spiega Qualcomm.

"Celebriamo l'approccio aperto di Meta con Llama 3 e condividiamo il loro impegno nel potenziare gli sviluppatori e stimolare l'innovazione nel campo dell'intelligenza artificiale", ha affermato Durga Malladi, vicepresidente senior e direttore generale della tecnologia, pianificazione e soluzioni edge di Qualcomm Technologies.
"La leadership nell'intelligenza artificiale on-device, unita alla nostra vasta portata su vari dispositivi edge, ci consente di espandere i vantaggi dell'ecosistema Llama in tutto il mondo e consentire a clienti, partner e sviluppatori di creare una nuova generazione di esperienze AI rivoluzionarie".



 Lenovo Legion Go 2: Ryzen Z2 Extreme e OLED 8,8'' per spingere gli handheld gaming PC al massimo
Lenovo Legion Go 2: Ryzen Z2 Extreme e OLED 8,8'' per spingere gli handheld gaming PC al massimo AWS re:Invent 2025: inizia l'era dell'AI-as-a-Service con al centro gli agenti
AWS re:Invent 2025: inizia l'era dell'AI-as-a-Service con al centro gli agenti Cos'è la bolla dell'IA e perché se ne parla
Cos'è la bolla dell'IA e perché se ne parla Fortnite non arriverà sull'App Store giapponese, nonostante l'apertura alle terze parti di Apple
Fortnite non arriverà sull'App Store giapponese, nonostante l'apertura alle terze parti di Apple Vodafone ha la rete mobile migliore in Italia: ecco i risultati del nuovo report Opensignal
Vodafone ha la rete mobile migliore in Italia: ecco i risultati del nuovo report Opensignal Lenovo Legion Go 2 con SteamOS: il debutto potrebbe essere vicinissimo
Lenovo Legion Go 2 con SteamOS: il debutto potrebbe essere vicinissimo L'aggiornamento ai contenuti pre-espansione di Midnight ha una data ufficiale
L'aggiornamento ai contenuti pre-espansione di Midnight ha una data ufficiale Sony prepara il terreno per la sua handheld: come potrebbe essere la nuova PlayStation portatile
Sony prepara il terreno per la sua handheld: come potrebbe essere la nuova PlayStation portatile DAZN per Android blocca l'accesso all'utente se nel telefono solo installate app indesidederate
DAZN per Android blocca l'accesso all'utente se nel telefono solo installate app indesidederate Amazon non si ferma più e abbassa altri articoli top: ecco la lista aggiornata degli affari migliori
Amazon non si ferma più e abbassa altri articoli top: ecco la lista aggiornata degli affari migliori Fire TV Stick 4K ancora in super offerta su Amazon: la nuova Select costa solo 19, basse anche le Plus e Max
Fire TV Stick 4K ancora in super offerta su Amazon: la nuova Select costa solo 19, basse anche le Plus e Max ECOVACS DEEBOT T80 OMNI e T50 OMNI Gen2 sono i robot più venduti: potenza, qualità al top, stessi prezzi Black Friday
ECOVACS DEEBOT T80 OMNI e T50 OMNI Gen2 sono i robot più venduti: potenza, qualità al top, stessi prezzi Black Friday Ribassi Bose su Amazon: QuietComfort over ear in forte calo, 179, ma anche le in ear sono scontate
Ribassi Bose su Amazon: QuietComfort over ear in forte calo, 179, ma anche le in ear sono scontate Il portatile tuttofare migliore di Amazon: 569, è un HP, ha 32GB di RAM, 1TB di SSD e Intel Core i5
Il portatile tuttofare migliore di Amazon: 569, è un HP, ha 32GB di RAM, 1TB di SSD e Intel Core i5 SpaceX: un satellite ha fotografato il satellite Starlink 35956 danneggiato in orbita mostrando le sue condizioni
SpaceX: un satellite ha fotografato il satellite Starlink 35956 danneggiato in orbita mostrando le sue condizioni



























5 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoLo dico perche' magari qualcuno dell'IA di Meta non e' che si fidi troppo..
Continua a girare questa disinformazione che è stata chiarita anche dall'OSI...
https://opensource.org/blog/metas-l...not-open-source
Facebook contribuisce a molti progetti opensource, stupisce ma è così...
Domanda interessante, in totale per addestrare entrambi i modelli le emissioni sono state equivalenti a 2290 tonnellate di Co2 (700w per GPU per 7.7 milioni di ore ) interamente compensate dal programma di sostenibilità di Meta
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".