





Pascal: nuova architettura con memoria 3D e NVLink

Jen-Hsun Huang ha rivelato al GTC le prossime due architetture NVIDIA per le future GPU: si tratta di Pascal e di Volta.
di Rosario Grasso pubblicata il 17 Marzo 2015, alle 19:10 nel canale Schede VideoNVIDIA
La prossima architettura NVIDIA, nome in codice Pascal, sarà pensata principalmente per sfruttare le nuove tecnologie come le DirectX 12. Pascal, che arriverà nel 2016, offrrirà il doppio delle performance per watt rispetto a Maxwell e sarà quattro volte più performante in termini di mixed precision.
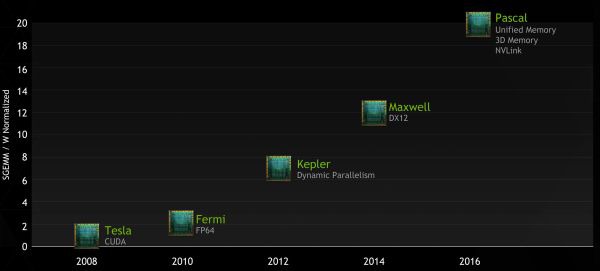
Sarà il primo chip grafico con memoria stacked, sfruttando una nuova tecnologia che consente di installare memoria DRAM su più strati. La memoria 3D chip stack all'interno dello stesso chip della GPU, infatti, permetterà al processore grafico di elaborare i dati più velocemente aumentando allo stesso tempo la larghezza di banda, con miglioramenti sensibili anche in termini di efficienza energetica.
Il nuovo sistema di memoria unificata, inoltre, permetterà alla CPU di accedere alla memoria della GPU e viceversa. Pascal si caratterizzerà anche per NVLink, il nuovo sistema di connessione che sostituirà l'attuale bus PCI-Express. NVLink migliorerà le comunicazioni tra CPU e GPU, passando a 80GB al secondo rispetto agli 16GB al secondo della connessione PCIe. Visto che NVLink richiede un nuovo design per le schede madri, però, è probabilmente che almeno inizialmente venga utilizzato solo per le soluzioni server.



 La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025
La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025 SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni
SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni Dalle radio a transistor ai Micro LED: il viaggio di Hisense da Qingdao al mondo intero
Dalle radio a transistor ai Micro LED: il viaggio di Hisense da Qingdao al mondo intero Microsoft annuncia diverse novità su Windows in Europa, per una maggiore adesione al DMA
Microsoft annuncia diverse novità su Windows in Europa, per una maggiore adesione al DMA Stranger Things 5: ecco il trailer e la data di uscita della stagione finale su Netflix
Stranger Things 5: ecco il trailer e la data di uscita della stagione finale su Netflix Sconti PlayStation 5 su Amazon: Slim con 2 DualSense a 459, PS VR2 a 399 e PS5 Pro in offerta a 749
Sconti PlayStation 5 su Amazon: Slim con 2 DualSense a 459, PS VR2 a 399 e PS5 Pro in offerta a 749 Roborock QV 35A: il robot che pulisce da solo e senza intoppi oggi è in offerta a 474
Roborock QV 35A: il robot che pulisce da solo e senza intoppi oggi è in offerta a 474 Gli iPhone in offerta oggi? C'è il 15 128GB a 645, oltre ai 16 Pro e Pro Max al minimo storico
Gli iPhone in offerta oggi? C'è il 15 128GB a 645, oltre ai 16 Pro e Pro Max al minimo storico Una domenica bestiale Amazon: LG OLED, super portatile Lenovo, iPhone 16 Pro e Pro Max, robot e altri super sconti
Una domenica bestiale Amazon: LG OLED, super portatile Lenovo, iPhone 16 Pro e Pro Max, robot e altri super sconti DJI Mini 4 Pro Fly More Combo: drone leggero che non richiede il patentino oggi in offerta super su Amazon
DJI Mini 4 Pro Fly More Combo: drone leggero che non richiede il patentino oggi in offerta super su Amazon realme GT 7T: display da 6000 nit, potentissimo, 7000 mAh, quasi un top di gamma a metà del prezzo che ti aspetti
realme GT 7T: display da 6000 nit, potentissimo, 7000 mAh, quasi un top di gamma a metà del prezzo che ti aspetti Ancora qualche pezzo per il portatile Lenovo con Core i7, 40GB RAM e 1TB SSD: va sempre a ruba
Ancora qualche pezzo per il portatile Lenovo con Core i7, 40GB RAM e 1TB SSD: va sempre a ruba TV OLED LG Serie C4 2024: immagini da cinema e 4K a 144Hz in sconto su Amazon
TV OLED LG Serie C4 2024: immagini da cinema e 4K a 144Hz in sconto su Amazon Smartwatch Amazfit in sconto: Active 2 a 97, ma ci sono offerte su tutta la gamma
Smartwatch Amazfit in sconto: Active 2 a 97, ma ci sono offerte su tutta la gamma Router e ripetitori AVM FRITZ! da 30 su Amazon: ecco tutte le offerte da non perdere
Router e ripetitori AVM FRITZ! da 30 su Amazon: ecco tutte le offerte da non perdere Adulting 101: i corsi per imparare come era la vita fino a qualche anno fa
Adulting 101: i corsi per imparare come era la vita fino a qualche anno fa



























23 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoNon resta che sperare in miglioramenti sostanziali dello standard Pci Express in grado di limitare il collo di bottiglia che produce inferiori prestazioni nel caso d'uso di sistemi a memoria unificata.
Problema non di poco conto, dato che non essere limitati alla memoria della scheda video, ma fortemente penalizzati al livello di prestazioni, non è in grado di soddisfare determinati requisiti in determinate applicazioni.
Mentre al livello di collegamenti tra sole schede video nVidia (GPU↔GPU connections) ritengo usciranno soluzioni, senza problemi, dato che non penso richiedano modifiche di nessun genere alla scheda madre.
Riferimenti:
NVLink, Pascal and Stacked Memory: Feeding the Appetite for Big Data
NVIDIA Updates GPU Roadmap; Unveils Pascal Architecture For 2016
What Is NVLink? And How Will It Make the World’s Fastest Computers Possible?
Sul fronte HSA la situazione attuale è questa http://www.phoronix.com/scan.php?pa...-1.0-Final-Spec
cosi' buttiamo tutti i sistemi con gpu integrata nella cpu
Ma anche no, visto che la memoria video (GDDR) ha latenze molto più elevate rispetto alla memoria di sistema (DDR), che incidono negativamente sul codice più "general purpose" che è quello eseguito dalla CPU (anche quando esegue codice SIMD, che è più lineare e trae vantaggio dalla maggior banda, le istruzioni non posso rimanere appese per centinaia e centinaia di cicli di clock perché le prestazioni ne risentono tantissimo).
Banda != velocità. C'è anche la latenza come parametro prestazionale.
Spero che questo nvlink fallisca miseramente... che cavolo di bisogno c'è di fare una soluzione proprietaria quando pci-express 4 è alle porte e garantirà 32GB/s di banda per collegamenti 16x?
Sul fronte HSA la situazione attuale è questa http://www.phoronix.com/scan.php?pa...-1.0-Final-Spec
Perché accedere alla memoria su scheda discreta non è uguale ad accedere alla memoria di sistema condivisa tra CPU e GPU integrata?
Non puoi accedere alla memoria della GPU discreta se il controller di memoria a bordo della CPU (che ora è di Intel/AMD, non più su chipset esterno come un tempo) non ha un bus fatto apposta per accedervi.
Spero che questo nvlink fallisca miseramente... che cavolo di bisogno c'è di fare una soluzione proprietaria quando pci-express 4 è alle porte e garantirà 32GB/s di banda per collegamenti 16x?
Si parla di 32GB contro 80. 2,5 volte. Forse per giocare a Battlefield non ha importanza, ma per le operazioni di calcolo ogni GB è importante.
Non è reinventare la ruota o creare una soluzoine proprietaria tanto per: è necessaria per nvidia per superare i limiti imposti da Intel/AMD con i loro memory controller e linee PCI risicate.
Dal punto di vista dei componenti coinvolti cambia l'implementazione fisica, ma il meccanismo è lo stesso. In pratica se non hai la memoria unificata non puoi nemmeno cominciare a fare questa cosa.
Non credo ci siano differenze insanabili tra le due implementazioni ( ma magari mi sbaglio ), per questo mi sono chiesto "perchè non si sono messi d'accordo con AMD piuttosto che introdurre l'ennesimo meccanismo proprietario?".
Poi ho letto "deep learning" e ho capito il perchè!
Non credo ci siano differenze insanabili tra le due implementazioni ( ma magari mi sbaglio ), per questo mi sono chiesto "perchè non si sono messi d'accordo con AMD piuttosto che introdurre l'ennesimo meccanismo proprietario?".
Poi ho letto "deep learning" e ho capito il perchè!
Perché quella AMD non è l'unica piattaforma su cui le schede nvidia devono funzionare. Anzi. Interesse su quelle pari a zero.
Le discrete di nvidia devono funzionare principalmente sui server (da qui l'accordo con IBM) e poi sulle worstation.
Se Intel non vuole (come ovvio che sia) che il suo memory controller possa accedere a pezzi di memoria esterni a velocità supersonica, per nvidia non c'è altro modo che inventarsi una soluzione diversa che bypassi il problema alla radice. E che vale per tutti.
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".