





NVIDIA, i piani sull'intelligenza artificiale dei prossimi anni: nel 2028 arriva Feynman

Durante la GTC 2025 il CEO di NVIDIA Huang ha fatto il punto sulla roadmap degli acceleratori, che evolve con cadenza annuale. Dopo Blackwell Ultra, Rubin e Rubin Ultra spunta, con orizzonte 2028, l'architettura Feynman.
di Manolo De Agostini pubblicata il 18 Marzo 2025, alle 22:25 nel canale Schede VideoIntelligenza ArtificialeVeraRubinFeynmanBlackwellNVIDIA
NVIDIA ha fatto il punto sulla roadmap degli acceleratori di intelligenza artificiale, svelando che dopo l'architettura Rubin arriverà il progetto Feynman. Prima di approfondire, partiamo dalla generazione Blackwell che, salvo qualche inciampo iniziale, sembra aver messo il turbo.
Durante la conferenza alla GTC 2025, il CEO di NVIDIA ha dichiarato di aver piazzato 3,6 milioni di GPU Blackwell solo quest'anno alle principali realtà cloud statunitensi, e raggiunto ricavi di 11 miliardi di dollari con Blackwell. Numeri da capogiro, ma su cui non si può dormire sugli allori.
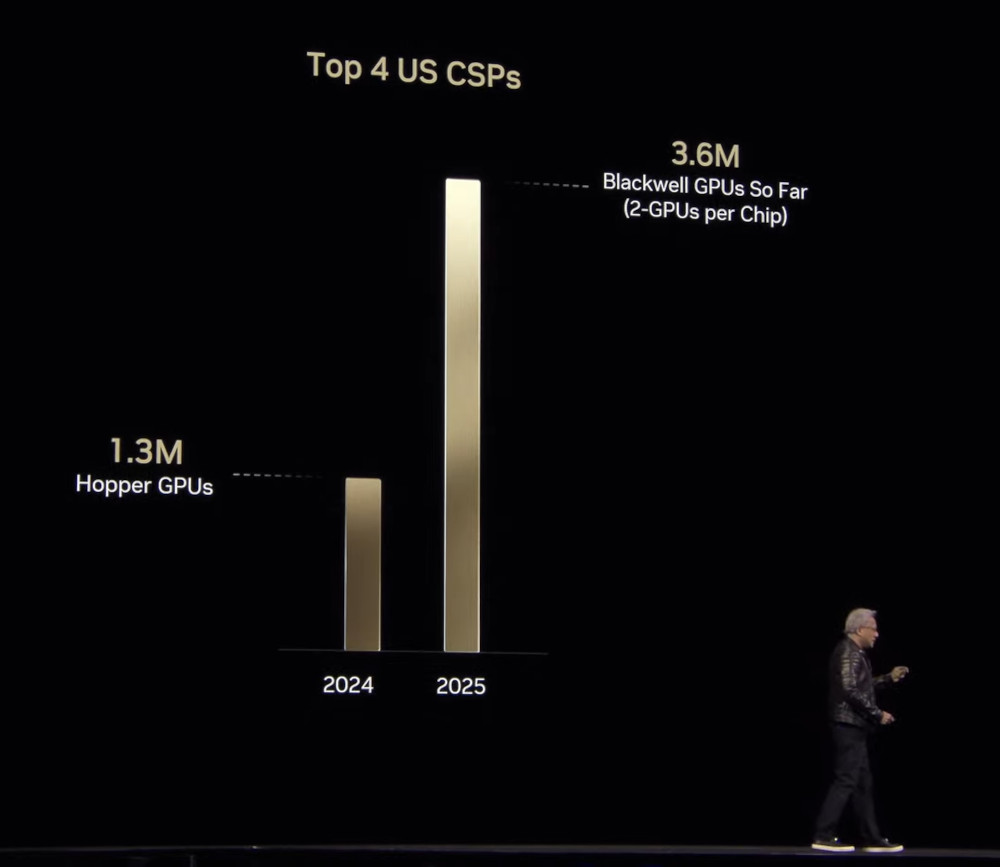
Per questo motivo, e al fine di dettare il ritmo dell'innovazione, NVIDIA si affiderà a Blackwell Ultra (GB300 e B300), in arrivo nella seconda metà di quest'anno. Al momento non ci sono dettagli specifici sulla GPU, ma NVIDIA sostiene che la nuova architettura fornirà il 50% in più di prestazioni FP4 rispetto a Blackwell, salendo così da 10/20 petaflops (Dense/Sparse) a 15/30 petaflops.
In attesa di ulteriori dettagli, sappiamo il chip sarà affiancato a 288 GB di memoria HBM3E anziché i 192 GB di Blackwell. NVIDIA ha rapportato Blackwell Ultra principalmente con H100 (Hopper), la GPU che nel 2022 ha avviato le sue fortune e a cui i clienti che l'hanno acquistata potrebbero voler iniziare a dire addio.

Clicca per ingrandire
Sfruttando le istruzioni FP4 e utilizzando Blackwell Ultra insieme alla nuova libreria software Dynamo per modelli di ragionamento come DeepSeek, NVIDIA sostiene che un rack NVL72 può fornire prestazioni di inferenza 30 volte superiori rispetto a una configurazione Hopper del tutto simile. Inoltre, Blackwell Ultra può far girare una copia interattiva di DeepSeek-R1 671B fornendo risposte in 10 secondi anziché il minuto e mezzo di H100. NVIDIA sostiene che ciò è possibile perché Blackwell Ultra processa 1000 token al secondo, 10 volte in più di quanti ne può gestire Hopper.
NVIDIA ha in cantiere GB300 NVL72 e HGX B300 NVL16. Nel primo caso si tratta di un sistema con 36 schede, dotate ognuna di una CPU e due GPU, capace di raggiungere prestazioni FP4 di 1,1 exaflops. A bordo 20 TB di memoria HBM3E e 40 TB di LPDDR5X per le CPU Grace. HGX B300 NVL16, invece, prevede 16 GPU B300 e processori x86 connessi tramite NVLink. Al momento non è dato sapere il fornitore della CPU, con NVIDIA che ha usato sia soluzioni AMD che Intel finora.

Clicca per ingrandire
Dopo Blackwell Ultra, nella seconda parte del 2026 sarà la volta dell'architettura GPU Rubin con memoria HBM4, accompagnata dalla nuova CPU Vera con 88 core Arm custom e 176 thread, nonché un'interfaccia NVLink a 1,8 TB/s per il collegamento alle GPU Rubin.
Alle GPU Rubin la società affiancherà sempre 288 GB di memoria, ma la bandwidth passerà da 8 a 13 TB/s. L'anno seguente, sempre nella seconda metà, toccherà all'aggiornamento Rubin Ultra con memoria HBM4E.

Clicca per ingrandire
Parlando di Rubin, NVIDIA ha dichiarato che "Blackwell è stato chiamato in modo sbagliato". Cosa significa? Poiché Blackwell B200 prevede due die per GPU, NVIDIA sostiene che avrebbe dovuto chiamare NVL72 raddoppiandone il numero, ovvero NVL144. Ed è proprio così che avverrà a partire da Rubin.
NVIDIA prevede che Rubin NVL144 offrirà prestazioni pari a 3,6 petaflops con calcoli FP4 dense, un salto di 3,3 volte rispetto agli 1,1 petaflops di Blackwell NVL72. Con l'avvento di Rubin Ultra assisteremo anche all'arrivo di NVL576, un rack con 576 GPU che porterà le prestazioni a raggiungere nuove vette: 15 exaflops in inferenza FP4 e 5 exaflops in addestramento FP8.

Clicca per ingrandire
Rubin Ultra avrà quattro die per package, ovvero collegherà due GPU, offrendo prestazioni di calcolo FP4 di 100 petaflops e 1 TB di memoria HBM4E. La nuova architettura permetterà a NVL576 di offrire 14 volte le prestazioni di GB300 NVL72.

Clicca per ingrandire
Infine, nel 2028 arriverà l'architettura Feynman, in onore al famoso fisico teorico. Al momento NVIDIA non si è sbilanciata a parlare di questa architettura con dovizia di dettagli, tuttavia ha indicato che le affiancherà una memoria HBM di prossima generazione, il che potrebbe significare HBM4E o HBM5. Inoltre, NVIDIA non prevede di creare una nuova CPU da affiancare a Feynman, e quindi resterà Vera introdotta con l'architettura Rubin.



 La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025
La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025 SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni
SAP Sapphire 2025: con Joule l'intelligenza artificiale guida app, dati e decisioni Dalle radio a transistor ai Micro LED: il viaggio di Hisense da Qingdao al mondo intero
Dalle radio a transistor ai Micro LED: il viaggio di Hisense da Qingdao al mondo intero Una domenica bestiale Amazon: LG OLED, super portatile Lenovo, iPhone 16 Pro e Pro Max, robot e altri super sconti
Una domenica bestiale Amazon: LG OLED, super portatile Lenovo, iPhone 16 Pro e Pro Max, robot e altri super sconti DJI Mini 4 Pro Fly More Combo: drone leggero che non richiede il patentino oggi in offerta super su Amazon
DJI Mini 4 Pro Fly More Combo: drone leggero che non richiede il patentino oggi in offerta super su Amazon realme GT 7T: display da 6000 nit, potentissimo, 7000 mAh, quasi un top di gamma a metà del prezzo che ti aspetti
realme GT 7T: display da 6000 nit, potentissimo, 7000 mAh, quasi un top di gamma a metà del prezzo che ti aspetti Ancora qualche pezzo per il portatile Lenovo con Core i7, 40GB RAM e 1TB SSD: va sempre a ruba
Ancora qualche pezzo per il portatile Lenovo con Core i7, 40GB RAM e 1TB SSD: va sempre a ruba TV OLED LG Serie C4 2024: immagini da cinema e 4K a 144Hz in sconto su Amazon
TV OLED LG Serie C4 2024: immagini da cinema e 4K a 144Hz in sconto su Amazon Smartwatch Amazfit in sconto: Active 2 a 97, ma ci sono offerte su tutta la gamma
Smartwatch Amazfit in sconto: Active 2 a 97, ma ci sono offerte su tutta la gamma Router e ripetitori AVM FRITZ! da 30 su Amazon: ecco tutte le offerte da non perdere
Router e ripetitori AVM FRITZ! da 30 su Amazon: ecco tutte le offerte da non perdere Adulting 101: i corsi per imparare come era la vita fino a qualche anno fa
Adulting 101: i corsi per imparare come era la vita fino a qualche anno fa Blue Origin ha lanciato con successo la missione suborbitale NS-32 con New Shepard
Blue Origin ha lanciato con successo la missione suborbitale NS-32 con New Shepard L'amministrazione Trump ha ritirato la candidatura di Jared Isaacman come amministratore della NASA
L'amministrazione Trump ha ritirato la candidatura di Jared Isaacman come amministratore della NASA La NASA potrebbe chiudere le missioni OSIRIS-APEX, New Horizons e Juno cancellandone altre per risparmiare soldi
La NASA potrebbe chiudere le missioni OSIRIS-APEX, New Horizons e Juno cancellandone altre per risparmiare soldi Trump vieta anche la vendita di software per la progettazione di chip alle società cinesi
Trump vieta anche la vendita di software per la progettazione di chip alle società cinesi Le migliori offerte del weekend Amazon: portatili, robot, iPhone, Kindle ai prezzi più bassi di sempre
Le migliori offerte del weekend Amazon: portatili, robot, iPhone, Kindle ai prezzi più bassi di sempre Dreame L40 Ultra a 699, prezzo shock: vale quasi quanto lX40 Ultra da 999 (ma costa 300 in meno!)
Dreame L40 Ultra a 699, prezzo shock: vale quasi quanto lX40 Ultra da 999 (ma costa 300 in meno!)



























6 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoSe invece non lo fara' e qualcun altro lo fara' al posto suo, beh allora diverra' na nuova Nvidia.
Se invece non lo fara' e qualcun altro lo fara' al posto suo, beh allora diverra' na nuova Nvidia.
Non sono un esperto di IA. Ma da quello che capisco, queste soluzioni sono più per l'addestramento che per l'esecuzione di IA già addestrata. Quest'ultimo scenario è dove CPU or NPU sono più efficienti.
Esatto... questi sono acceleratori IA specializzati per l'addestramento di modelli di grosse dimensioni da applicare ad enormi moli di dati.
Per l'esecuzione di semplici compiti di IA o ML, come venivano chiamati fino a poco tempo fa, su dispositivo ( manipolazione d'immagini, video e testo, organizzazione dei dati personali, assistenti di input, etc. ), sono sufficienti le NPU integrate nelle CPU e/o GPU consumer. Una potenza di 35/38 TOPS è più che sufficiente per accelerare i compiti sopra citati.
In questo caso le viene in aiuto anche la complessità di gestione di tutti quei dati per addomesticare la quale è partita diversi anni fa a costruire SW ad hoc. Che si appoggiano sul suo standard proprietario CUDA, e quindi non compatibili con altro HW.
Direi che ha messo in piedi un mercato perfetto, che prima non esistreva, dove sarà difficilissimo scalzarla. Almeno finché dura la corsa all'AGI, cioè fino a quando nessuno può permettersi di usare qualcosa che non sia il top anche se l'alternativa costa un decimo.
Agli altri le briciole a cui non serve il top, quindi l'inferenza per gli utenti "povery" nei datacenter cloud.
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".