





|
|||||||


|



|
|
 |
|
|
Strumenti |
 04-03-2017, 20:56
04-03-2017, 20:56
|
#441 | ||
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Quote:
 Quote:
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
||

|

|

|
04-03-2017, 20:59
|
#442 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Forse non hai presente come funzionano le reti neurali, ma ogni neurone richiede un paio di parametri, quindi la quantità di dati non è stratosferica e una decina di neuroni e qualche layer è più che sufficiente per fare qualcosa di significativo... Non so quanti neuroni artificiali ci sono, ma probabilmente pochi, per fare meno calcoli possibili... Quindi non ci vuole poi tanto silicio... Se si usa poi i fixed point per l'aritmetica, ci vuole poco...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|

|
04-03-2017, 21:01
|
#443 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Parliamo di numeri: quanto occupa l'area della rete neurale? Quanti transistor approssimativamente possono essere impiegati? Quanti pattern riesce a memorizzare? Qual è la latenza delle risposte?
I numeri di possibili scenari, come quelli testati, te li ho già forniti. La teoria lascia il tempo che trova... P.S. Ovviamente ho presente come funzionino le reti neurali, sebbene non ne abbia mai sviluppata una.
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
|
|
|
|
04-03-2017, 21:27
|
#444 | |
|
Bannato
Iscritto dal: Dec 2001
Città: Palmi
Messaggi: 3241
|
Non sò quanta colpa, percentualmente parlando, possa esser attribuita alla scarsa ottimizzazione del sistema operativo nei confronti di Ryzen.
Credo ci possa esser qualcosa relegata alla non perfetta gestione dell'HyperThreading (o Multithreading) e più in generale del risparmio energetico di tutti i cores, e che ciò possa incidere al massimo tra il 10% ed il 15% non permettendo comunque a questa CPU di oltrepassare le prestazioni in games dei quad core Intel I7 7700 di settima generazione nel breve periodo (al massimo pareggiare i conti in qualche gioco nella migliore delle ipotesi). Il motivo è sempre lo stesso ovvero la poca scalabilità degli attuali motori grafici utilizzati in campo videoludico con processori aventi più di 4 cores. Se gli attuali motori grafici avessero già quest'oggi sfruttato meglio gli esacores e gli octacores, anche senza ottimizzazione del sistema operativo avremmo avuto nel corso di questa presentazione dei Ryzen prestazioni al top in ambito gaming per la nuovissima piattaforma AMD così come per gli octacores della controparte Intel. La cosa positiva dell'introduzione dei Ryzen è che grazie ad AMD ed ai prezzi concorrenziali dei suoi nuovi processori inizieranno ad aumentare il numero delle piattaforme octacores nei sistemi di gioco e questo porterà prima del previsto i programmatori a rendere più scalabili le prestazioni in multicores dei loro motori grafici a vantaggio anche di coloro che usano piattaforme basate su CPU Intel I7 69x0 ed anche delle serie ancor più vecchie 59x0-49x0-39x0. Quote:
|
|
|
|
|
|
04-03-2017, 22:04
|
#445 |
|
Senior Member
Iscritto dal: Apr 2004
Messaggi: 2944
|
Ryzen è un'architettura completamente nuova che parte già fortissimo al debutto. Tra ottimizzazioni del software, dei bios e in generale della piattaforma, del processo produttivo e future revision che sicuramente ci saranno mi aspetto notevoli miglioramenti nei prossimi mesi
__________________
AMD 9800X3D -MSI B650 EDGE - MSI 4090 GAMING X - 2X16GB GSKILL 6000MHZ CAS 30- SAMSUNG 980 PRO 2TB - Seasonic Prime Titanium 850W |
|
|
|
|
04-03-2017, 22:06
|
#446 | |
|
Senior Member
Iscritto dal: Jan 2007
Messaggi: 6723
|
Quote:
In soldoni è probabile che siano più simili a dei branch/prefetch predictor con una componente di apprendimento automatico più sofisticata rispetto ad un "conteggio" degli esiti precedenti. Non mi stupirei se parlassero di reti neurali anche per difendersi dai patent troll (difficile battere le reti neurali come prior art). |
|
|
|
|
|
04-03-2017, 22:15
|
#447 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
La penso come te, infatti, a parte sul nome che penso sia una questione di marketing.
Ed è proprio il marketing di AMD che a mio avviso ha tratto in inganno il redattore di Bits and Chips, che ha preso per oro colato questo materiale puramente divulgativo: "Neural Net Prediction – an artificial intelligence neural network that learns to predict what future pathway an application will take based on past runs;" In realtà il modello è molto più semplice, e non ha nulla a che vedere con la memorizzazione di successive esecuzioni dell'applicazione, come si può facilmente intuire dalla slide tecnica di AMD: 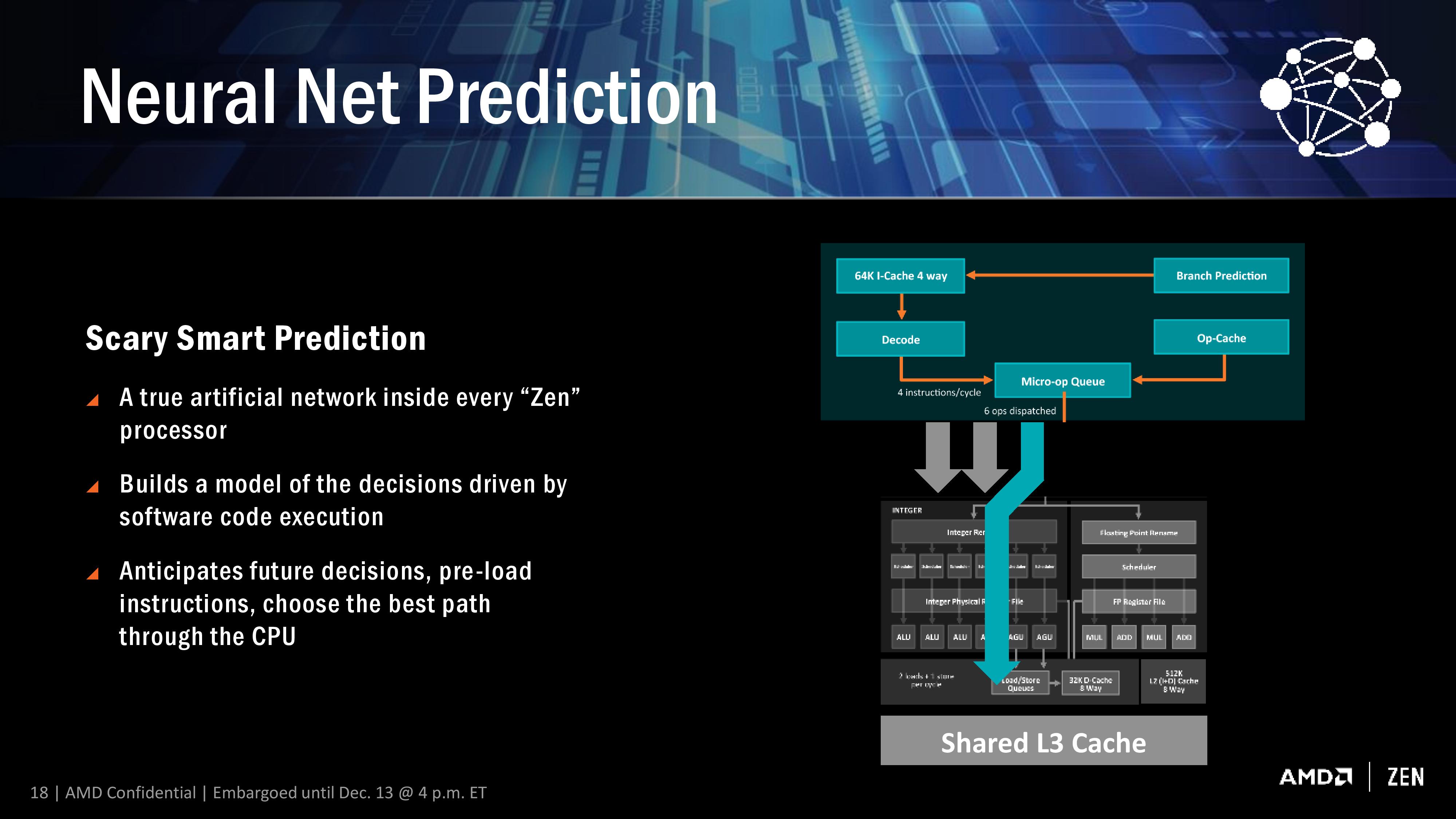 Soltanto una persona che non ha cognizione di come funzioni un moderno microprocessore poteva abboccare a uno slogan pubblicitario, e pensare che fosse stata infilata una rete neurale, pur semplificata, nel core. Tanto che ha voluto verificare al reset cosa succedesse.  A dimostrazione di come internet sia piena di gente che si spaccia come esperta in materia, ma che la "cultura", invece, se la sia fatta a colpi di ricerche, prendendo pezzi di qua e di là...
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
|
|
|
|
04-03-2017, 22:22
|
#448 | |
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 10395
|
Quote:
|
|
|
|
|
|
04-03-2017, 22:33
|
#449 | |
|
Senior Member
Iscritto dal: Jun 2004
Messaggi: 5623
|
Quote:
Fare previsioni in overclock al momento è affrettato,sia nel bene che nel male...si possono pure fare,ma hanno poco fondamento.
__________________
I love old school celeron 1300@2471 mhz a-data 3200 bh-5@330 mhz cas 2 2 2 5 abit nf7-s fsb@274,1 mhz I love homemade |
|
|
|
|
|
04-03-2017, 23:05
|
#450 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Sempre che non usino la regressione logistica che è come fosse un solo neurone e per risposte binarie tipo salto/non salto, non devi neanche implementare la funzione logit, ma semplicemente mettere una soglia sulla combinazione lineare dei parametri...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
|
04-03-2017, 23:08
|
#451 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
|
04-03-2017, 23:18
|
#452 |
|
Bannato
Iscritto dal: May 2001
Messaggi: 6246
|
la "rete neurale" di cui si parla non c'entra con l'autoapprendimento reiterato.
è una delle parti del blocco decoder di Intel (un gran bel blocco). questa componente cerca semplicemente di ricostruire macro-ops SMT su codice vario, su thread appartenenti a diversi programmi. la predizione è nel metterli nella stessa risorsa, nello stesso core (perche' se mandi un thread a milano ed uno a napoli difficile poi che riesci a gestirli come unica entità ). Intel ha creato le sue istruzioni HT, AMD le ha copiate, ma la vera "battaglia" stà nello sfruttarle non da codice precompilato, ma da codice vario. Alpha insegna, ma erano anche monocore. e per inciso è (anche) per questo che ha uno scaling threading molto piu' alto degli intel: riesce a ricomporre qualche Macro-op SMT in piu' rispetto ad Intel. Ultima modifica di lucusta : 05-03-2017 alle 08:05. |
|
|
|
|
05-03-2017, 08:23
|
#453 |
|
Junior Member
Iscritto dal: Dec 2013
Messaggi: 16
|
la grafica?
per me che uso photoshop e dei giochi non m'interessa nulla si intuisce già se ryzen sia al livello di intel ?(io parlo del più caro)contro ovviamente il più caro di intel...
|
|
|
|
|
05-03-2017, 08:50
|
#454 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
La chiamano rete neurale, ma non pensate che sia qualcosa di complicato. La cosa innovativa che fecero ai tempi è studiarne le proprietà e codificarne gli algoritmi di apprendimento, cercando quello ottimale. Non è niente di magico: una rete combinatoria con un po' di memoria... Quello che c'è dietro è lo studio delle proprietà e degli algoritmi di apprendimento... E' come guardare quel sito che raccoglie javascript di massimo 140 caratteri che fanno delle cose grafiche di una bellezza assurda, ma in 140 caratteri, e meravigliarsi... Con poco si può fare molto... P.S.: https://www.dwitter.net/top
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
|
05-03-2017, 08:57
|
#455 |
|
Senior Member
Iscritto dal: Jul 2015
Messaggi: 5783
|
@cdmauro
Sul 2600 ( Sandy bridge) con disse stock avevo notato che con cinebench multi: 1 run x 2 run x+ 7/8% 3 run ×+ 2 4 run x - 2% Per poi ripartire dal run 2 Avevo concluso che: Nel run 1 i dati non erano tutti disponibili in l3 Nel 2 i dati erano tutti in l3 e max turbo Nel 3 il clock si abbassata al valore di targa senza turbo Nel 4 addirittura la frequenza oscilla tra la nominale e - 100mhz Su dual x5690 a liquido invece il primo run era basso mentre tutti gli altri in turbo max. In ryzen invece vedo una progressione crescente che ancora non riesco a giustificare ( e per vedere se sia rete neurale bisognerebbe eseguire test che non siano influenzati dalla l3). |
|
|
|
|
05-03-2017, 09:53
|
#456 | ||
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Infatti è plausibile che sia proprio ciò che è avvenuto con quei test.
Quote:
Hai esperienza con le reti neurali, e quindi sai già quanto sia complesso implementare anche un solo neurone con un certo numero di input, e che fornisca un risultato. Infatti prima, e non a caso, parlavi di utilizzare matematica a precisione fissa, per ridurre i costi, ma anche questo ha un costo non indifferente quando devi pensare di implementare tutto in hardware. Infatti ti servono dei moltiplicatori, e più precisamente te ne serve uno per pesare ogni input. I moltiplicatori, come sai, sono abbastanza costosi in termini di transistor utilizzati, sono aree del chip molto attive e quindi consumano corrente e dissipano calore, e inoltre soffrono di una certa latenza. Ci sono diverse implementazioni in hardware, che sono dei compromessi a seconda di quello che ti serve: se vuoi velocità (bassissima latenza) devi mettere sul piatto un bel po' di energivori transistor; viceversa, se vuoi risparmiare transistor (e consumi) avrai latenze più elevate. Non si scappa. Poi devi mettere assieme il tutto, e ti servono n-1 sommatori. Anche questi costano, anche se molto meno rispetto ai moltiplicatori, ma si portano dietro alcuni problemi (il riporto). E fin qui siamo alla mera computazione dei calcoli per l'azione. Se vuoi dare la possibilità alla rete di correggersi nel tempo, in base agli input, devi necessariamente passare da una delle possibili funzioni d'attivazione, e qui le cose si fanno MOLTO, MOLTO DIFFICILI, visto che si utilizzano funzioni trascendentali condite da divisioni. Implementarle in hardware? Certo, tutto è possibile, ma a costi elevatissimi (se vogliamo ottenere i risultati senza addormentarci nell'attesa che vengano elaborati), e comunque anche nella migliore delle ipotesi la latenza sarebbe elevata. Infine c'è da scegliere una funzione di threshold, da applicare al risultato precedente, per stabilire l'output del neurone. E' l'unica parte che sarebbe semplice da implementare, perché potrebbe anche bastare un comparatore. Tutto questo, come già detto, per implementare UN solo neurone, e parliamo di vagonate di transistor da utilizzare allo scopo, che IMO competono tranquillamente con quelli impiegati in un'ALU di un'unità SIMD. Fin qui mi sono limitato all'implementazione di un generico neurone. Adesso passiamo al nostro caso più concreto: un core che ha a che fare con delle istruzioni da eseguire, registri da usare, operazioni da/verso la memoria, risorse (porte) da utilizzare. La slide di AMD lascia già intendere che questa rete agisca a livello di micro-op, e dunque avrà a che fare con questa tipologia di dato, ma in base alla descrizione dovrà tenere conto anche delle risorse che ho elencato prima. Dunque IMO almeno le micro-op e le porte utilizzate (perché servono per costruire la "storia" su cui dovrà lavorare) dovrebbero rappresentare gli input del neurone. Come output penso sia sufficiente, per semplicità, considerare a quale porta smistare la micro-op. Le porte sono soltanto 10, e dunque parliamo di una piccola informazione. Ma le macro-op, come sai, occupano parecchio spazio perché sono dense, dovendo codificare al loro interno un bel po' di informazioni. Dunque dimensionare le risorse per manipolare questo tipo di input richiede un bel po' di spazio, che influisce su tutto il discorso di cui sopra. Puoi semplificare il tutto se cataloghi le macro-op per "tipologia", magari aggiungendo un apposito campo al loro interno, ma non so quante tipologie di macro-op siano necessarie. Le istruzioni x86 sono centinaia e centinaia (parecchie migliaia se teniamo conto anche delle combinazioni dovute ad esempio all'uso di flag, delle diverse modalità d'indirizzamento verso la memoria, dell'uso o meno di costanti, di lock, prefissi che cambiano il segmento attualmente usato, ecc. ecc.. E queste sono tutte informazioni di cui si DEVE tenere conto in questo contesto, perché possono influenzare l'uso di alcune risorse all'interno del core), dunque servirebbero in ogni caso un po' di bit. In realtà la questione è ancora più complicata se teniamo conto che le micro-op si possono successivamente dividere in uop, e che queste ultime possono poi provenire dalla uop-ROM. Mi fermo qui, ma direi che ce n'è abbastanza per capire la portata dell'introduzione di una rete neurale all'interno del core di un processore. Per cui sono più che convinto che la soluzione implementata sia quella che ha precedentemente descritto LMCH. Quote:
Ricorda che parliamo di un processore che opera intorno ai 3,5Ghz, che per ciclo di clock può eseguire il dispatch di fino a 6 micro-op e ritirare 8 uop. Immagina una rete neurale che, per ogni ciclo di clock, debba gestire tutto ciò (perché è di questo che si parla, se rifletti attentamente sul diagramma presente nella slide, e sulla descrizione delle operazioni), e penso che le conclusioni le potrai trarre tu stesso. Ciò che voglio dire, e che comunque anche in altre occasioni è capitato di discutere, è che non si può pensare a delle cose astrattamente solo perché "si può fare", ma è strettamente necessario calarle nelle preciso contesto di cui si parla. Capire, insomma, se un'idea possa o meno essere compatibile con la realtà delle cose. Nello specifico, se conosci come funzionano le reti neurali, di come lavorano, di come si potrebbero implementare in hardware, e infine di come funziona a runtime il core di un processore, l'ultima cosa che uno potrebbe pensare è di vederne implementata una al suo interno. Per realizzare certe operazioni, come quelle discusse nella slide, ci sono ben altre soluzioni, molto più economiche e veloci, ma che hanno ben poco a che spartire con le reti neurali. Soprattutto, sono soluzioni che funzionano nel contesto locale, cioè analizzando l'attuale contesto elaborativo, perché è impensabile che un core si possa trascinare dire una sorta di "memoria storica" delle centinaia di miliardi di istruzioni eseguite. Spero di essere stato chiaro. E son d'accordo con la risposta a lucusta: non penso che Intel implementi roba del genere. Poi queste son cose che ritengo rientrerebbero nei famigerati trade secret dell'azienda, visto che è preferibile siano implementati ben nascosti fra i transistor, essendo molto difficili da carpire a operazioni di reverse engineering. In soldoni: è roba che un'azienda non pubblicizzerebbe nemmeno di striscio.
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
||
|
|
|
|
05-03-2017, 10:18
|
#457 |
|
Senior Member
Iscritto dal: Mar 2005
Città: Sconosciuta
Messaggi: 2562
|
Dato che qualcuno mi sta scrivendo per chiedermi il mio parere sulla nuova uscita di questi processori.. posto qui le mie considerazioni.
Sono contento per Amd di aver tirato fuori dei processori che possono competere con gli i7.. BRAVA AMD! Cmq diciamoci la verità la stragrande maggioranza delle persone non compra i7 da diverse centinaia di euro e quindi neanche ryzen.. Ma è giusto che AMD possa controbattere anche in quella nicchia.. A mio avviso oggi in un pc contano molto gli ssd, m.2, usb 3..poi se uno ha un procio da 200 euro o 400..secondo me non sta tanto li la differenza. Per quanto riguarda i prezzi..be' sono concorrenziali anche se personalmente non so se comprerei il modello x da 450 euro..preferirei spendere molto meno..e penso sia così anche per molti giocatori incalliti.. Byez
__________________
CM HAF 500~EVGA 750G5~DeepCool LS 720~Asus TUF gaming X670E~Ryzen 7700X~2x16Gb DDR5 6000~Asus Prime RX 9070 16gb+Samsung 980 pro+870 evo+WD Black 4Tb -- 2° PC: CM Silencio 452+Nepton 240m+CM650V2~Asus 970 pro~FX 8370-2X8Gb~6500XT~Samsung 950 pro+Crucial MX 300- 3° PC: Athlon II x4 645-2x4Gb-Crucial MX 300. Monitors: AOC 24G2U/BK & Samsung S24F350 |
|
|
|
|
05-03-2017, 10:31
|
#458 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Siccome la predizione è del tipo si no, probabilmente sarà solo la sommatoria pesata di n parametri (probabilmente semplicemente global e local history e qualche altro parametro più qualche feedback) e poi un bias così da dover solo vedere il bit più significativo (il segno) per decidere se saltare o no. Nulla di trascendentale (pun intended)... Semplicemente i coefficienti non sono fissi, ma variati con qualche criterio, probabilmente derivato dalla branca dell'inteligenza artificiale... Il perceptron che io sappia, c'è già in Jaguar e non è così complesso da implementare... Al max lo usano anche per il prefetch in Zen, mi sembra di aver capito, ma non so in che modo...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! Ultima modifica di bjt2 : 05-03-2017 alle 10:34. |
|
|
|
|
|
05-03-2017, 10:42
|
#459 | |
|
Senior Member
Iscritto dal: Aug 2007
Città: Milano
Messaggi: 11985
|
Quote:
Diciamo piuttosto che e' un buon risultato, visto che finora ha arrancato un bel po'. Comunque i test SENZA Turbo non si possono vedere. Sono inutili. La funzione Turbo e' integrata nei processori, non e' una funzionalita' della scheda madre o un overclock manuale. Toglierla significa invalidare i test che avete fatto, messi cosi' non significano nulla. Perche' magari uno prende Ryzen convinto che sia allo stesso livello, poi scopre che col Turbo attivo il 7700K prende il volo e giustamente smadonna...
__________________
CLOUD STORAGE FREE | Asus G51JX (Thread Ufficiale) | Quale notebook per giocare? | PC (in corso): 2x Intel Xeon E5-2670 v1 2,6GHz - 96GB RAM - SAS 10-15k rpm - GPU TBD| |
|
|
|
|
|
05-03-2017, 10:54
|
#460 | |
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Quote:
Forse ti riferisci ai test effettuati per calcolare l'IPC, ma lì è una cosa completamente diversa, e roba come il Turbo/XFR DEVE essere disabilitata. @bjt2: un percertrone è già più semplice, ma IMO sarà una logica predittiva molto simile (a livello implementativo) a un branch predictor, come affermava anche LMCH.
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
|
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 16:31.















