





Unicode è la codifica più utilizzata sul Web

Sul Web il tasso d'adozione della codifica Unicode ha superato quello dello standard ASCII, parola di Google
di Fabio Gozzo pubblicata il 08 Maggio 2008, alle 11:45 nel canale WebMark Davis, senior international software architect di Google, è di recente intervenuto sul blog ufficiale della compagnia di Mountain View con alcune interessanti considerazioni sugli standard di codifica dei caratteri attualmente utilizzati sul Web.
Basandosi su informazioni interne della compagnia, Davis afferma che attualmente lo standard più popolare per la codifica dei caratteri delle pagine Web non è più l'ASCII (American Standard Code for Information Interchange) ma l'Unicode.
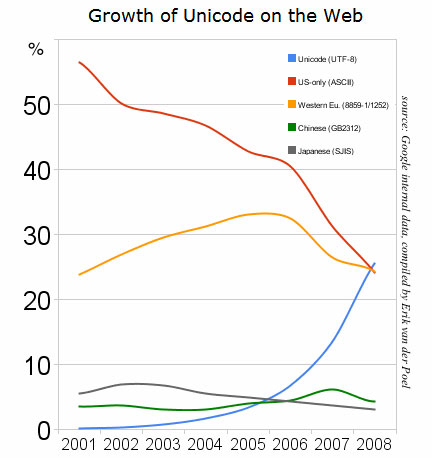
Fonte: Google
In accordo con i dati rilasciati da Google, il sorpasso della codifica Unicode è avvenuto lo scorso dicembre e, nonostante il vantaggio sia tuttora minimo, è frutto di una crescita significativa è costante avvenuta nell'arco degli ultimi 3 anni.
La lenta ma graduale migrazione verso Unicode è in atto ormai da molto tempo e non è certo una sorpresa. Il sistema di codifica ASCII esteso utilizza 8 bit di memoria per memorizzare un singolo carattere ed è in grado di rappresentare solamente 256 simboli. Questa limitazione del formato ha portato alla nascita di diverse versioni dello standard al fine di soddisfare le diverse esigenze dei ceppi linguistici esistenti.
Per far fronte alla frammentazione e ai problemi di conversione dovuti all'esistenza di differenti versioni dello standard ASCII, è nato Unicode, un formato che si prefigge di poter rappresentare tutti i caratteri esistenti. Questo sistema di codifica è stato infatti pensato per poter essere facilmente espanso ed aggiornato, garantendo sempre la retrocompatibilità con le precedenti versioni. Attualmente sono utilizzate le codifiche a 8, 16 o 32 bit, indicate rispettivamente con le sigle UTF-8, UTF-16 e UTF-32.
La convergenza del Web verso il più recente standard di codifica Unicode riduce notevolmente le problematiche legate alla visualizzazione di differenti alfabeti, tuttavia ha come svantaggio una maggiore occupazione di memoria rispetto allo standard ASCII per la memorizzazione di un singolo carattere.



 Polestar 3 Performance, test drive: comodità e potenza possono convivere
Polestar 3 Performance, test drive: comodità e potenza possono convivere Qualcomm Snapdragon X2 Elite: l'architettura del SoC per i notebook del 2026
Qualcomm Snapdragon X2 Elite: l'architettura del SoC per i notebook del 2026 Recensione DJI Mini 5 Pro: il drone C0 ultra-leggero con sensore da 1 pollice
Recensione DJI Mini 5 Pro: il drone C0 ultra-leggero con sensore da 1 pollice BOE non convince: Apple cambia fornitori per i pannelli OLED degli iPhone 17 Pro
BOE non convince: Apple cambia fornitori per i pannelli OLED degli iPhone 17 Pro Samsung realizzerà il suo Snapdragon 8 Elite Gen 5: il chip non sarà utilizzato dai Galaxy S26
Samsung realizzerà il suo Snapdragon 8 Elite Gen 5: il chip non sarà utilizzato dai Galaxy S26 Non solo smartphone per POCO: sono in arrivo due nuovi tablet Android
Non solo smartphone per POCO: sono in arrivo due nuovi tablet Android Google vuole portare la traduzione in tempo reale anche sugli occhiali smart grazie all'AI
Google vuole portare la traduzione in tempo reale anche sugli occhiali smart grazie all'AI Il nuovo entry-level della gamma MacBook sta arrivando: chip A18 Pro e tastiera senza retroilluminazione
Il nuovo entry-level della gamma MacBook sta arrivando: chip A18 Pro e tastiera senza retroilluminazione Google: per sostenere l'AI bisogna raddoppiare la capacità di calcolo ogni sei mesi
Google: per sostenere l'AI bisogna raddoppiare la capacità di calcolo ogni sei mesi Amazon Black Friday weekend: le offerte appena aggiornate e i bestseller imperdibili
Amazon Black Friday weekend: le offerte appena aggiornate e i bestseller imperdibili Black Friday, assalto ai robot economici: ecco i modelli con super potenza, lavaggio evoluto e maxi sconti da non perdere
Black Friday, assalto ai robot economici: ecco i modelli con super potenza, lavaggio evoluto e maxi sconti da non perdere Le auto cinesi battono tutti: ecco chi accelera più di Tesla e Lamborghini
Le auto cinesi battono tutti: ecco chi accelera più di Tesla e Lamborghini I 2 portatili tuttofare più venduti del Black Friday: MSI Modern da 549 spopola, ma c'è un HP da 499 eccezionale
I 2 portatili tuttofare più venduti del Black Friday: MSI Modern da 549 spopola, ma c'è un HP da 499 eccezionale Roborock Q7 M5 da 10.000Pa in offerta Black Friday: il robot che lava e aspira scende a 149, occasione da prendere al volo
Roborock Q7 M5 da 10.000Pa in offerta Black Friday: il robot che lava e aspira scende a 149, occasione da prendere al volo LG OLED B5 e C5 in super sconto Black Friday: i modelli da 55'' e 65'' a prezzi mai visti
LG OLED B5 e C5 in super sconto Black Friday: i modelli da 55'' e 65'' a prezzi mai visti Il nuovo iPhone 17e sta arrivando: ecco tutte le novità rispetto al 16e
Il nuovo iPhone 17e sta arrivando: ecco tutte le novità rispetto al 16e Pensi ancora che i robot non ti ruberanno il lavoro? Guarda qui e inizia a tremare
Pensi ancora che i robot non ti ruberanno il lavoro? Guarda qui e inizia a tremare



























24 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoCosì poi servivano 20 versione del sito...
quando è che ci passa anche hwupgrade?
Tutte le altre lingue hanno gli accenti, e lettere "strane" per non parlare delle lingue con scrittura diversa dai caratteri romani...
Per me sono pochi i siti che usano Unicode...
Occupa più byte solo quando si passa dal 128° carattere in poi, prima occupa 1B. In base al valore dei bit più significativi si sa quanti byte formano il prossimo carattere.
Se usiamo solo caratteri presenti in ASCII standard la dimensione del testo sarà identica. Se usiamo solo caratteri NON presenti sarà almeno il doppio.
Non è uno svantaggio la dimensione dei caratteri perchè non c'è altro modo per rappresentare i caratteri se non aumentando la quantità di bit necessari per descriverli. Il vantaggio è invece l'eliminazione dei byte non necessari alla rappresentazione.
UTF-32 contiene caratteri lunghi 8, 16, 24 E 32bit.
Occupa più byte solo quando si passa dal 128° carattere in poi, prima occupa 1B. In base al valore dei bit più significativi si sa quanti byte formano il prossimo carattere.
Se usiamo solo caratteri presenti in ASCII standard la dimensione del testo sarà identica. Se usiamo solo caratteri NON presenti sarà almeno il doppio.
Non è uno svantaggio la dimensione dei caratteri perchè non c'è altro modo per rappresentare i caratteri se non aumentando la quantità di bit necessari per descriverli. Il vantaggio è invece l'eliminazione dei byte non necessari alla rappresentazione.
UTF-32 contiene caratteri lunghi 8, 16, 24 E 32bit.
*
UTF Rulezz
Occupa più byte solo quando si passa dal 128° carattere in poi, prima occupa 1B. In base al valore dei bit più significativi si sa quanti byte formano il prossimo carattere.
Se usiamo solo caratteri presenti in ASCII standard la dimensione del testo sarà identica. Se usiamo solo caratteri NON presenti sarà almeno il doppio.
Non è uno svantaggio la dimensione dei caratteri perchè non c'è altro modo per rappresentare i caratteri se non aumentando la quantità di bit necessari per descriverli. Il vantaggio è invece l'eliminazione dei byte non necessari alla rappresentazione.
UTF-32 contiene caratteri lunghi 8, 16, 24 E 32bit.
Interessante. Visto che sembri ferrato in materia, ti faccio una domanda: apro un documento di testo in formato ANSI con Notepad (sono su una macchina con Windows XP), lo salvo in Unicode e la dimensione del file raddoppia. Il file contiene solo caratteri ASCII standard (ho fatto una prova scrivendo una serie di aaaaaaaaaaaaaa bbbbbbbbbbbbb cccccccccccc copiata ed incollata n volte per renderlo un po' corposo). Colpa di come Notepad / Windows gestiscono Unicode o dipende da qualcos'altro?
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".