





Nvidia A100, ci sono 54 miliardi di transistor nella GPU GA100 Ampere

Nvidia ha presentato l'acceleratore Nvidia A100, fino a 20 volte più potente di Tesla V100. A bordo la nuova GPU GA100 basata su architettura Ampere, prodotta a 7 nanometri. Il chip conta 54 miliardi di transistor ed è affiancato da 40 GB di memoria HBM2.
di Manolo De Agostini pubblicata il 14 Maggio 2020, alle 15:36 nel canale Schede VideoNVIDIATesla
Nvidia ha presentato il nuovo acceleratore Nvidia A100, successore del Tesla V100 presentato tre anni fa. La nuova proposta punta a scuotere il mercato HPC (High Performance Computing) e dell'intelligenza artificiale con prestazioni fino a 20 volte maggiori rispetto al predecessore.
Per raggiungere questo traguardo, Nvidia ha messo a punto una nuova architettura chiamata Ampere e una GPU identificata dal nome GA100. Realizzata con processo produttivo a 7 nanometri, questa GPU occupa un'area di 826 mm2, conta 54,2 miliardi di transistor e nell'incarnazione a bordo di Nvidia A100 offre 6912 CUDA core FP32 all'interno di 108 SM, affiancati da 432 Tensor core e altrettante unità texture.

Non ci troviamo di fronte al GA100 nella sua forma completa, in quanto la GPU conta nella sua massima espressione ben 128 SM per un totale di 8192 CUDA core, 512 Tensor core e altrettante texture unit. Per confronto, il predecessore GV100, realizzato a 12 nanometri e dotato di 21,1 miliardi di transistor, offre 5376 CUDA core FP32, 672 Tensor core e 336 unità texture in un'area di 815 mm2. In tale forma però non l'abbiamo mai visto, infatti la Tesla V100 offre al massimo 5120 CUDA core e 640 Tensor core per effetto di quattro SM disabilitati (80 attivi su 84).
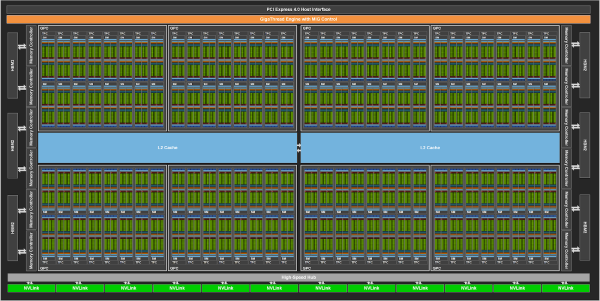
L'acceleratore Nvidia A100, dotato di connettività PCI Express 4.0, vede anche la presenza sullo stesso package della GPU di 40 GB di memoria HBM2 (5 stack), in grado di offrire un bandwidth di 1,6 TB/s su bus a 5120 bit (10 controller a 512 bit). Anche in questo caso però un GA100 al massimo livello offre qualcosina in più, ossia 6 stack HBM2 con 12 controller a 512 bit per un totale di 48 GB di memoria e un bus a 6144 bit.
La nuova proposta della casa di Santa Clara è inoltre dotata di collegamento NVLink 3.0 con 12 linee bidirezionali a 25 GB/s per un totale di 600 GB/s (300*2) nella comunicazione "GPU to GPU". Con la Tesla V100 il collegamento NVLink arrivava a 300 GB/s. La scheda ha un TDP di 400 watt.
| Data Center GPU | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA A100 |
| Nome in codice | GP100 | GV100 | GA100 |
| Architettura | NVIDIA Pascal | NVIDIA Volta | NVIDIA Ampere |
| Form Factor | SXM | SXM2 | SXM4 |
| SM | 56 | 80 | 108 |
| TPC | 28 | 40 | 54 |
| FP32 Core / SM | 64 | 64 | 64 |
| FP32 Core / GPU | 3584 | 5120 | 6912 |
| FP64 Core / SM | 32 | 32 | 32 |
| FP64 Core / GPU | 1792 | 2560 | 3456 |
| INT32 Core / SM | NA | 64 | 64 |
| INT32 Core / GPU | NA | 5120 | 6912 |
| Tensor Core / SM | NA | 8 | 4 |
| Tensor Core / GPU | NA | 640 | 432 |
| Boost Clock GPU | 1480 MHz | 1530 MHz | 1410 MHz |
| FP16 Tensor TFLOPS con FP16 Accumulate (picco) | NA | 125 | 312/624 |
| FP16 Tensor TFLOPS con FP32 Accumulate (picco) | NA | 125 | 312/624 |
| BF16 Tensor TFLOPS con FP32 Accumulate (picco) | NA | NA | 312/624 |
| TF32 Tensor TFLOPS (picco) | NA | NA | 156/312 |
| FP64 Tensor TFLOPS (picco) | NA | NA | 19.5 |
| INT8 Tensor TOPS (picco) | NA | NA | 624/1248 |
| INT4 Tensor TOPS (picco) | NA | NA | 1248/2496 |
| FP16 TFLOPS (picco) | 21.2 | 31.4 | 78 |
| BF16 TFLOPS (picco) | NA | NA | 39 |
| FP32 TFLOPS (picco) | 10.6 | 15.7 | 19.5 |
| FP64 TFLOPS (picco) | 5.3 | 7.8 | 9.7 |
| INT32 TOPS (picco) | NA | 15.7 | 19.5 |
| Unità texture | 224 | 320 | 432 |
| Interfaccia di memoria (bus) | 4096-bit HBM2 | 4096-bit HBM2 | 5120-bit HBM2 |
| Memoria | 16 GB | 32 GB / 16 GB | 40 GB |
| Data rate memoria | 703 MHz DDR | 877.5 MHz DDR | 1215 MHz DDR |
| Bandwidth memoria | 720 GB/sec | 900 GB/sec | 1.6 TB/sec |
| Cache L2 | 4096 KB | 6144 KB | 40960 KB |
| Memoria condivisa / SM | 64 KB | Configurabile fino a 96 KB | Configurabile fino a 164 KB |
| Dimensione file di registro / SM | 256 KB | 256 KB | 256 KB |
| Dimensione file di registro / GPU | 14336 KB | 20480 KB | 27648 KB |
| TDP | 300 Watt | 300 Watt | 400 Watt |
| Transistor | 15,3 miliardi | 21,1 miliardi | 54,2 miliardi |
| Dimensione die GPU | 610 mm2 | 815 mm2 | 826 mm2 |
| Processo produttivo | 16 nm FinFET+ | 12 nm FFN | 7 nm N7 |
Con "prestazioni 20 volte superiori" Nvidia si riferisce all'allenamento di intelligenze artificiali (operazioni a singola precisione, FP32) e inferenza (operazioni INT8). Si parla invece di prestazioni 2,5 volte maggiori di Tesla V100 con calcoli a doppia precisione (FP64). Un ruolo decisivo nel raggiungere queste prestazioni lo hanno i Tensor core, giunti alla terza generazione e migliorati ulteriormente grazie al supporto del nuovo formato TF32 (TensorFloat-32) che permette l'accelerazione di operazioni in virgola mobile a singola precisione. I nuovi Tensor core supportano inoltre, per la prima volta, anche i calcoli a doppia precisione. Come se non bastasse, le unità si avvalgono di nuova tecnica chiamata "structural sparsity" che raddoppia la velocità di esecuzione dei calcoli legati all'IA - supporta i formati TF32, FP16, BFLOAT16, INT8 e INT4.

Un'altra novità dell'architettura Ampere è la possibilità di partizionare la GPU (soluzione che Nvidia definisce Multi-instance GPU o MIG) per permetterle di eseguire in parallelo sette istanze diverse, ognuna con le proprie risorse.


L'acceleratore Nvidia A100 è già in produzione e arriverà sotto diverse forme: la prima è il sistema per il deep learning DGX A100 venduto a 200 mila dollari. Al suo interno ci sono otto GPU GA100 per una potenza di calcolo di 5 petaflops (IA) o 10 petaflops (INT8). Tra l'altro è interessante segnalare l'abbandono della piattaforma Intel Xeon in favore di due AMD EPYC 7742 (Rome) con 64 core ciascuno - una scelta obbligata, oggi come oggi, per avere compatibilità con il PCI Express 4.0. La piattaforma conta 15 TB di SSD PCI Express 4.0 e sei NVSwitch (bandwidth di 4,8 TB/s bidirezionale). Tra i primi acquirenti troviamo l'Argonne National Laboratory del Dipartimento dell'Energia statunitense.

C'è poi HGX A100, che non è altro che il blocco fondante di DGX destinato ai produttori di server, e l'inedito EGX A100, che combina una Nvidia A100 con Mellanox SmartNIC per l'ambito dell'edge computing. Nvidia ha anche annunciato DGX SuperPOD, un cluster formato da 140 sistemi DGX A100 che raggiunge una potenza di calcolo di 700 petaflops; sarà usato internamente in aree di ricerca come la genomica e la guida autonoma.
Per finire, l'azienda ha dichiarato che Atos, Dell Technologies, Fujitsu, Gigabyte, H3C, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta e Supermicro commercializzeranno server con il nuovo acceleratore e diversi fornitori di servizi cloud - tra cui Alibaba Cloud, Amazon Web Services, Baidu Cloud, Google Cloud e Tencent Cloud - sono pronti a offrire istanze basate su Nvidia A100.



 BOOX Note Air4 C è uno spettacolo: il tablet E Ink con Android per lettura e scrittura
BOOX Note Air4 C è uno spettacolo: il tablet E Ink con Android per lettura e scrittura Recensione Sony Xperia 1 VII: lo smartphone per gli appassionati di fotografia
Recensione Sony Xperia 1 VII: lo smartphone per gli appassionati di fotografia Attenti a Poco F7: può essere il best buy del 2025. Recensione
Attenti a Poco F7: può essere il best buy del 2025. Recensione DJI OSMO Mobile SE a 69: il gimbal compatto che trasforma i video dello smartphone in riprese da pro
DJI OSMO Mobile SE a 69: il gimbal compatto che trasforma i video dello smartphone in riprese da pro Scope elettriche da record su Amazon: due modelli potentissimi sotto i 120, ecco perché piacciono così tanto
Scope elettriche da record su Amazon: due modelli potentissimi sotto i 120, ecco perché piacciono così tanto GTA 6 a 80 euro? Take-Two frena sul prezzo e punta tutto sul valore percepito
GTA 6 a 80 euro? Take-Two frena sul prezzo e punta tutto sul valore percepito I 3 portatili più convenienti su Amazon: sono 2 tuttofare Lenovo e un HP Victus gaming con RTX 5060
I 3 portatili più convenienti su Amazon: sono 2 tuttofare Lenovo e un HP Victus gaming con RTX 5060 AirPods Pro 2 a soli 199: su Amazon anche AirPods 4 in sconto, ecco le differenze che contano
AirPods Pro 2 a soli 199: su Amazon anche AirPods 4 in sconto, ecco le differenze che contano 2 Smart TV 4K Hisense con doppio sconto su Amazon: sono OLED e QLED, 55" e 75", fateci un bel pensierino
2 Smart TV 4K Hisense con doppio sconto su Amazon: sono OLED e QLED, 55" e 75", fateci un bel pensierino Portatili Apple ai minimi: MacBook Pro con chip M4 a 1.648 e Macbook Air 13 16GB7256GB, sempre M4, a 998
Portatili Apple ai minimi: MacBook Pro con chip M4 a 1.648 e Macbook Air 13 16GB7256GB, sempre M4, a 998 Come mantenere Windows 10 sicuro dopo il 2025: tutto sul programma ESU
Come mantenere Windows 10 sicuro dopo il 2025: tutto sul programma ESU Finalmente è tornato su Amazon l'iPhone 16 128GB a 749, in tutti i colori, ma ci sono anche i 16e e 16 Pro in offerta
Finalmente è tornato su Amazon l'iPhone 16 128GB a 749, in tutti i colori, ma ci sono anche i 16e e 16 Pro in offerta Auto nuove? Per il 65% degli italiani sono troppo care, non dovrebbero costare oltre i 20.000 euro
Auto nuove? Per il 65% degli italiani sono troppo care, non dovrebbero costare oltre i 20.000 euro Droni solari Airbus volano nella stratosfera grazie alle nuove batterie al silicio: test riusciti a oltre 20 km di quota
Droni solari Airbus volano nella stratosfera grazie alle nuove batterie al silicio: test riusciti a oltre 20 km di quota Colpo da 15 milioni di dollari: chi ha rubato un carico di prodotti AMD e Apple?
Colpo da 15 milioni di dollari: chi ha rubato un carico di prodotti AMD e Apple? Elon Musk lancia l'allarme su GPT-5: 'OpenAI divorerà Microsoft'. Ma Nadella lo sfida con un sorriso
Elon Musk lancia l'allarme su GPT-5: 'OpenAI divorerà Microsoft'. Ma Nadella lo sfida con un sorriso iPhone 17 Pro sarà più costoso, ma anche più conveniente
iPhone 17 Pro sarà più costoso, ma anche più conveniente



























28 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoMa come, niente boost 2,8 GHz a 150 watt di tdp?
Ma come, non erano 50 tf?
Già mi vedo i bios da 700 watt per la gaming
Just around the corner
Il chip nella sua forma migliore ha 8192 core, ma nel caso della Nvidia A100 sono attivi molti meno.
No dai, giusto un pochino
Diciamo che una caffettiera per due ci sta comoda..
Non è sbagliato, ma per chiarezza metto un "fino a". Tieni presente che ho dovuto correre, tra mille dettagli tecnici ecc. Qualcosa può essermi sfuggito. Grazie mille dell'imbeccata
Clmdlmlmslmslmslms
Va beh ma questo è logico.
Il guadagno prestazionale è direttamente legato al tipo di calcoli che vengono fatti da una determinata applicazione.
Alcune probabilmente beneficiano tantissimo di nuove istruziuoni implementate ne nuovo hardware rispetto alle precedenti versioni, altre invece hanno un guadagno marginale.
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".