





NVIDIA GeForce GTX 480 e 470: Fermi, finalmente!

Con le schede GeForce GTX 480 e GTX 470 NVIDIA propone sul mercato le prime due soluzioni per sistemi desktop basate su architettura GF100 Fermi. L'attesa per questi prodotti č stata lunga: ne sarŕ valsa la pena?
di Gabriele Burgazzi, Paolo Corsini pubblicato il 27 Marzo 2010 nel canale Schede VideoNVIDIAGeForce
GF100 Fermi: la nuova architettura NVIDIA
Abbiamo segnalato in introduzione come NVIDIA abbia scelto, negli scorsi mesi, di fornire alcune informazioni ufficiali sulla propria architettura GF100 Fermi. Una prima occasione č stata il proprio GPU Technology Conference, tenutosi alla fine del mese di Settembre 2009, evento nel quale NVIDIA ha anticipato le caratteristiche architetturali di GF100 con riferimento ad utilizzi in ambiti di GPU Computing. L'attenzione era quindi incentrata sull'utilizzo dell'architettura Fermi con schede appartenenti alla famiglia Tesla, non sulle scelte architetturali fatte in funzione di un utilizzo di queste GPU in ambito grafico.
Nel mese di Gennaio 2010, poco dopo il CES di Las Vegas, NVIDIA ha invece fornito informazioni specifiche sulle scelte architetturali di GF100 Fermi legate all'utilizzo in ambito grafico; il target di riferimento era quindi quello delle soluzioni GeForce, le stesse che analizzeremo dal punto di vista prestazionale nelle pagine seguenti.
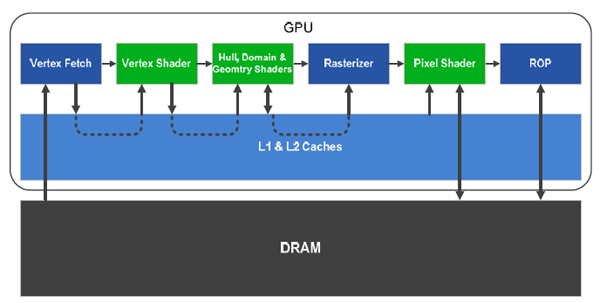
Dopo aver visto, negli scorsi mesi, quale sia l'architettura alla base delle GPU Fermi GF100 per applicazioni GPU Computing, concretizzate nella serie di schede della famiglia Tesla, illustriamo quelle che sono le specifiche tecniche della parte destinata al segmento videoludico che NVIDIA ha voluto rendere ora disponibili. Apriamo l'analisi con uno schema a blocchi che dettaglia gli elementi base delle GPU GF100 nel momento in cui vengono utilizzate per applicazioni grafiche:
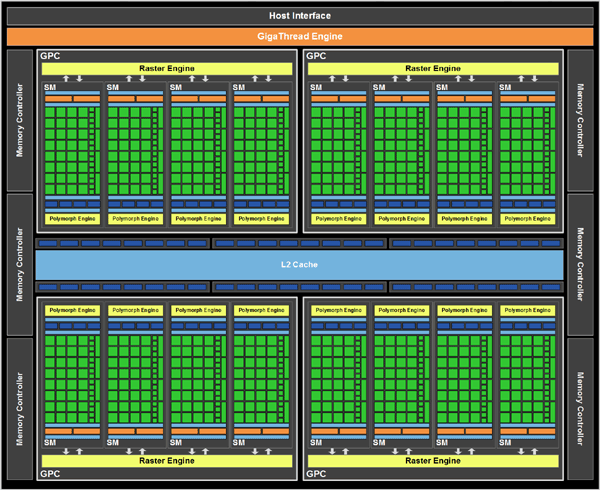
Nelle GPU GF100 sono integrati 512 CUDA Cores, nome scelto da NVIDIA per indicare i propri stream processors. Il numero di 512 č ovviamente quello massimo: le prime due concretizzazioni dell'architettura Fermi integrano rispettivamente 480 (GeForce GTX 480 ) e 448 (GeForce GTX 470) stream processors. Le GPU GF100 vedono i 512 CUDA Cores divisi in blocchi, ciascuno dei quali č indicato come streaming multiprocessor o SM; l'approccio richiama quanto giŕ visto con le precedenti generazioni di architetture video NVIDIA a shader unificati compatibili con le API DirectX 10, con alcune ovvie differenze. Se in G80 (GeForce 8800) e GT200 (GeForce GTX 200) i core erano raggruppati a blocchi di 8 all'interno di un SM, in GF100 l'approccio č cambiato con un numero di core 4 volte superiore per ogni SM: siamo quindi ora a 32 core. Riassumiamo questi dati nella seguente tabella:
| GPU | G80 | GT200 | GeForce GTX 480 | GeForce GTX 470 |
| CUDA core | 128 | 240 | 480 | 448 |
| core per ogni SM | 8 | 8 | 32 | 32 |
| SM in totale | 16 | 30 | 15 | 14 |
Per quale motivo NVIDIA ha scelto di disabilitare rispettivamente 1 e 2 SM nelle schede GeForce GTX 480 e GeForce GTX 470, rispetto al massimo teorico di 16 disponibili nell'architettura? La risposta č molto semplice ed č legata alle rese produttive: disabilitando 1 o 2 SM tutte quelle GPU che presentano 1 o 2 SM non funzionanti correttamente possono venir qualificate per l'utilizzo in produzione, incrementando il numero di die utili per ogni wafer prodotto. La presenza di soluzioni con differente numero di SM permette inoltre a NVIDIA di meglio segmentare la propria offerta sul mercato: la scheda GeForce GTX 470, quindi, nasce sia per meglio sfruttare le rese produttive a disposizione sia per offrire una gamma piů flessibile ai clienti. Analisi simile, del resto, puň essere fatta nel recente passato per le prime schede GeForce GTX 260, dotate al debutto di 192 stream processors attivi contro i 240 complessivamente presenti nella GPU GT200.
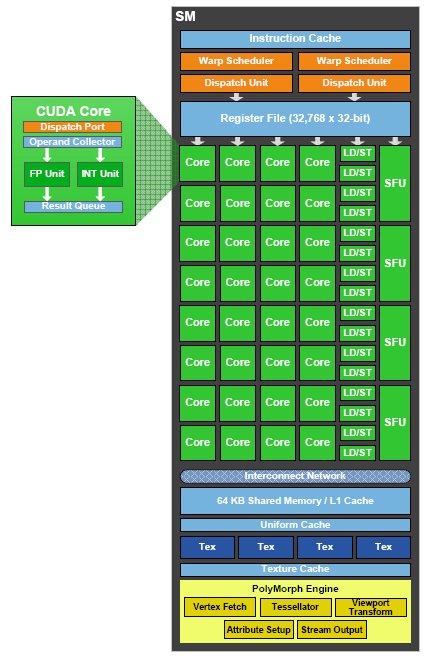
Come č costituito uno streaming multiprocessor? La parte centrale vede la presenza dei 32 CUDA cores: a gruppi di 4 sono associati a due unitŕ di load e store (LD/ST), mentre 2 di questi gruppi, per un totale di 8 CUDA cores, sono abbinati ad una unitŕ di tipo special function (SFU). A monte troviamo una cache per le istruzioni, seguita da due Warp Scheduler e da due unitŕ per le operazioni di dispatch, collegate al registro dei files capace di gestire un massimo di 32.768 entry a 32bit.
Ogni singolo CUDA Core integra al proprio interno un Dispatch Port, una unitŕ per la raccolta degli operanti, una unitŕ in floating point e una per i calcoli interni oltre ad una result queue. Le elaborazioni interne ad ognuno di questi core sono eseguite con precisione IEEE-754 2008 per le operazioni in virgola mobile e a 32bit per quelle con interi: la risultante sono unitŕ di elaborazione indipendenti per le due tipologie che sono pienamente compatibili con gli standard di mercato, caratteristica particolarmente utile non tanto in ambito gaming quanto in quello delle applicazioni GPU Computing.
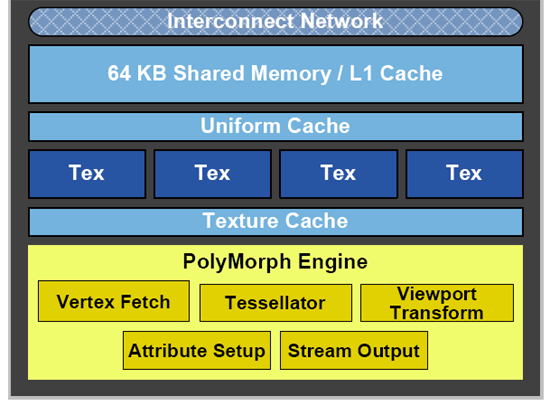
Per ogni streaming microprocessor troviamo una cache dedicata da 64 Kbytes di capacitŕ, partizionabile come memoria condivisa e come cache L1: i rapporti sono 1:3 oppure 3:1. Il rapporto č funzione del tipo di applicazione che viene eseguita: ricordiamo come GT200 integrasse una memoria cache da 16 Kbytes non partizionabile.
Ogni SM integra al proprio interno 4 texture units, per un totale quindi di 60 unitŕ di questo tipo presenti all'interno delle schede GeForce GTX 480 e 56 per quelle GeForce GTX 470. Le textures units sono dotate di una propria cache dedicata integrata all'interno dello specifico SM.
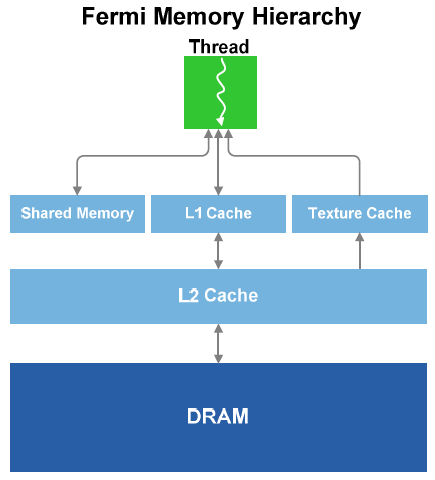
A completare la gerarchia della cache segnaliamo anche la presenza di una cache L2 integra alla GPU, di tipo unificato tra i vari SM, in quantitativo di 768 Kbytes. La gerarchia della cache vede quindi ogni thread a gestire in primo livello la cache da 64 Kbytes integrata in ogni SM, divisa in un blocco condiviso e in un secondo blocco di tipo L1 con dimensioni che possono essere pari a 16K/48K oppure 48K/16K.
La cache L1 dedicata alle operazioni di load e store non era stata implementata da NVIDIA dell'architettura GT200; in GF100 permette di incrementare le prestazioni soprattutto con applicazioni di fisica e di ray tracing. La cache condivisa era invece presente in quantitativo di 16 Kbytes nelle soluzioni GT200: in GF100 puň essere pari a 16 Kbytes oppure a 48 Kbytes, alternandosi in questo con quella L1 dedicata, cosě da avere a disposizione piů cache per i dati che sono ricorrenti ta i vari threads.
Tra le innovazioni implementate da NVIDIA in GF100 Fermi segnaliamo anche superiore velocitŕ nelle operazioni di content switching: questa funzionalitŕ č utile nei giochi nel momento in cui la GPU debba passare dall'elaborare una componente grafica all'esecuzione di altra tipologia di codice, come ad esempio quello PhysX, massimizzando l'utilizzo di ogni thread in parallelo.
La texture cache specifica per le 4 unitŕ di elaborazione presenti in ogni SM č in quantitativo pari a 12 Kbytes: in questo caso il valore č rimasto invariato rispetto a quanto implementato nelle GPU GT200. Uscendo dallo specifico SM nel quale il thread viene processato si incontra la cache L2 unificata, triplicata in quantitŕ rispetto a GT200 sino a 768 Kbytes, e a seguire il controller memoria GDDR5 da 384bit di ampiezza nella scheda GeForce GTX 480 e da 320bit in quella GeForce GTX 470. La differente ampiezza č ottenuta variando il numero di chip memoria: 10 per la scheda GeForce GTX 470, per un quantitativo complessivo di 1.280 Mbytes, e 12 per quella GeForce GTX 480, con in totale 1.536 Mbytes a disposizione.
A completare l'architettura segnaliamo la presenza di 4 unit per le operazioni di rasterizzazione, ciascuna quindi collegata ad un blocco di 4 SM, e 16 Polymorph Engine, nome scelto da NVIDIA per indicare le geometry units, ciascuno integrato in un SM. Analizzeremo questo componente nello specifico nelle pagine seguenti, parlando di capacitŕ di elaborazione geometrica delle soluzioni GF100. La scheda GeForce GTX 480 integra 48 ROPs, numero che scende a 40 per la scheda GeForce GTX 470. A titolo di confronto le architetture ATI RV880, utilizzate nelle schede Radeon HD serie 5800, integrano 32 ROPs, al pari delle soluzioni NVIDIA GeForce GTX 200; per le schede G80 il numero era pari a 24.
| GPU | G80 | GT200 | GTX 470 | GTX 480 |
| CUDA core | 128 | 240 | 448 | 480 |
| ROPs | 24 | 32 | 40 | 48 |
| numero core per ROPs | 5,3 | 7,5 | 11,2 | 10 |
E' interessante evidenziare come nelle varie architetture NVIDIA gli stream processors incrementino piů che proporzionalmente rispetto al numero di ROPs, a confermare quanto importante sia la capacitŕ di elaborazione degli shader nella generazione delle scene 3D piů recenti.
 Recensione Zenfone 11 Ultra: il flagship ASUS ritorna a essere un 'padellone'
Recensione Zenfone 11 Ultra: il flagship ASUS ritorna a essere un 'padellone' Appian: non solo low code. La missione è l’ottimizzazione dei processi con l'IA
Appian: non solo low code. La missione è l’ottimizzazione dei processi con l'IA Lenovo ThinkVision 3D 27, la steroscopia senza occhialini
Lenovo ThinkVision 3D 27, la steroscopia senza occhialini  La Cina ha lanciato la missione Shenzhou-18 con tre astronauti diretti verso la stazione spaziale cinese
La Cina ha lanciato la missione Shenzhou-18 con tre astronauti diretti verso la stazione spaziale cinese La sonda spaziale NASA Psyche comunica via laser con la Terra da 226 milioni di chilometri
La sonda spaziale NASA Psyche comunica via laser con la Terra da 226 milioni di chilometri Dacia Duster, prima guida: con le versioni ibride spacca il mercato
Dacia Duster, prima guida: con le versioni ibride spacca il mercato Arriva l'ok da Parlamento europeo sul diritto alla riparazione. Ecco cosa cambierà
Arriva l'ok da Parlamento europeo sul diritto alla riparazione. Ecco cosa cambierà Amazon scatenata: iPad a 399€, airfryer 38€, smartphone, portatili e moltissimi articoli in svendita!
Amazon scatenata: iPad a 399€, airfryer 38€, smartphone, portatili e moltissimi articoli in svendita! SK hynix, costruzione della Fab M15X ai nastri di partenza: previsto boom delle memorie HBM
SK hynix, costruzione della Fab M15X ai nastri di partenza: previsto boom delle memorie HBM Oggi 459€ per utenti Prime il portatile low cost con AMD Ryzen 7 5700U (8C/16T a 4,3GHz), 16GB RAM, SSD 512GB, Full HD!
Oggi 459€ per utenti Prime il portatile low cost con AMD Ryzen 7 5700U (8C/16T a 4,3GHz), 16GB RAM, SSD 512GB, Full HD! Sta per succedere! La prima gara a guida autonoma sarà il 27 aprile: come vederla online
Sta per succedere! La prima gara a guida autonoma sarà il 27 aprile: come vederla online Parthenope: un nuovo RPG investigativo tutto italiano e ambientato a Napoli
Parthenope: un nuovo RPG investigativo tutto italiano e ambientato a Napoli Urbanista Malibu: ecco come va la cassa Bluetooth con ricarica solare
Urbanista Malibu: ecco come va la cassa Bluetooth con ricarica solare Gas Station Simulator è costato 110 mila euro e ha guadagnato più di 10 milioni su Steam
Gas Station Simulator è costato 110 mila euro e ha guadagnato più di 10 milioni su Steam AOC Graphic Pro U3, tre nuovi monitor per i professionisti creativi
AOC Graphic Pro U3, tre nuovi monitor per i professionisti creativi


























