





|
|||||||


|



|
|
 |
|
|
Strumenti |
 27-09-2017, 21:07
27-09-2017, 21:07
|
#41 |
|
Senior Member
Iscritto dal: Oct 2009
Messaggi: 25109
|
perchè al momento ne hai 19 di errori, 1E9 = 19 in decimale e quindi meno di 51
ciao ciao
__________________
Pc - [LianLi Pc70]-[Corsair Ax860]-[Asrock z-170 extreme 6]-[Intel i7 6700k]-[16gb ddr4 Kingston HyperX Fury]-[Ssd 870evo 4Tb + 860evo 1Tb + 14Tb Toshiba MG + 16Tb Seagate Exos + 18Tb Seagate Exos]-[Lg 34gn850b]-[Razer D-Back Plasma Red]-[Windows 11 Pro 64bit 25H2  ] ]
|

|

|
|
28-09-2017, 12:52
|
#42 | ||
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
Quote:
Ma anche fossero stati 19 sarebbe stato scorretto confrontarli con il 51 della colonna soglia dato che i valori nelle colonne Attuale(CUrrent) Peggiore(worst) e soglia ( threshold) sono normalizzati in una scala arbitraria scelta dal produttore. E non variano nemmeno linearmente nel senso che se il valore grezzo aumenta di 1 non è che Attuale e peggiore variano sempre di 1. Dipende da che parametro e per quale produttore. Quindi intanto ha 489 errori, ma Attuale e Peggiore sono sempre al massimo che per WD e per quel parametro è 200. E giustamente non c'è nessu allarme del diagnostico su quel parametro. Come mai? Infatti Quote:
http://www.hwupgrade.it/forum/showpo...6&postcount=23 non risponde mentre tu levi la "E" da un esadecimale per far tornare le cose.  Ve lo spiego tra poco il mistero, appena ho finito di scrivere quello che sta diventando un "papiro" sullo s.m.a.r.t.
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 28-09-2017 alle 13:01. |
||
|
|
|

|
28-09-2017, 13:53
|
#43 | ||
|
Senior Member
Iscritto dal: Feb 2009
Messaggi: 50674
|
Quote:
Dopo ogni tot errori nella colonna Valori Grezzi, dovrebbe abbassarsi di un punto il valore scritto soprattutto alla colonna Attuale . Il perchè non lo faccia, questo devo essere sincero, non lo so, forse perchè il numero degli errori deve essere 800 o 1.000 o anche di più, perchè il valore alla colonna Attuale, scenda da 200 a 199 . E non so neanche perchè, se ci sono pochi o molti errori, alla colonna Valori grezzi della voce Errori lettura, come nel tuo caso, in esadecimale 1E9, che in decimale, che è il valore da prendere in considerazione diventano ben > 489 rimanga imperterrito il pallino blu, che non dovrebbe neanche essere giallo, ma rosso fuoco.......... Quote:
Guarda al post n.22 lo stato dell' hd dell' utente, è Eccellente........ eppure come detto al post n.23, gli Errori lettura, erano in decimale oltre 4.000...........più dei tuoi 489, anche se 489 è un numero già alto di per sè...........cosa è successo ? Quello previsto si è verificato, basta leggere l' utente cosa ha scritto al post n. 26 > http://www.hwupgrade.it/forum/showth...6#post45043146 Purtroppo è cosi, quando ci sono errori alla voce > Errori lettura, la situazione è di per sè, già grave........è bisogna allarmarsi, mai prendere questo valore in modo superficiale: se ci sono errori alla colonna Valore grezzi > è grave Gli Errori lettura, sono il cuore, la testa dell' hd, perchè sono le testine che ci sono all' interno dell' hd stesso . All' interno dell' hd ci sono 4 o più piatti, ogni piatto ha la sua testina che legge e che scrive . Se le testine, che per leggere e scrivere, sfiorano la superficie dei dischi, iniziano a toccare la superfice, invece di sfiorarla .......perchè magari si è piegato il rotore che le tiene, perchè una delle 4 o più testine si è leggerissimamente piegata o...........iniziano i dolori, alias, cambiare l' hd immediatamente . Sicuramente non usarlo più, se non per salvare i dati . Le testine si possono far riparare, ma è un lavoro di estrema precisione, che deve essere fatto da chi di dovere, da chi sa farlo e ha un suo costo.............. Il perchè i vari tool non evidenzino il fatto che, se ci sono degli errori, alla voce Errori lettura, è Grave, non lo so..... Ma so che se ci sono degli errori alla voce Errori Lettura, è molto più grave, rispetto al fatto che ci siano errori, alle voci : - Settori riallocati - Settori scrittura pendente - Settori non corregibili . Altre voci pericolose se presenti...sono Errori scrittura, che dipendono dagli Errori lettura, sono dipendenti tra di loro, perchè il problema sono sempre le testine e anche > Richiami di ricalibrazione > Questo attributo indica il numero di volte in cui è stata richiesta la ricalibrazione (a condizione che il primo tentativo non abbia avuto successo). Un aumento di questo attributo indica problema nel sistema meccanico. Se succede questo è gravissimo..........una volta compromessa la meccanica, hai vogliaaaa........... Pericolosi anche, se presenti gli > Errori seek > Numero degli errori di posizionamento delle testine magnetiche. Se sono presenti - problemi nel sistema di posizionamento meccanico, - danneggiamenti del rotore (è quello che tiene le testine, in modo tale che le testine leggo e scrivono, sfiorando la superficie dei dischi) - o un aumento della temperatura, il numero di errori di posizionamento aumenterà. Un elevato numero di errori di posizionamento indica un peggioramento delle condizioni della superficie del disco e del suo sistema meccanico. Anche qui, entra in gioco il sistema meccanico, alias............l' hd sta per andare........... Speriamo che maurilio968 Rimane sempre blu........ 
__________________
Aomei in Prog. & Utility - Lic OEM - Q di Merc Ott '22 - W10 Spot Images Seasons from '20 to Summer 2022 - DailyPic dalle Eccezioni alle Unique Images + Rec > DailyPic Unique Images Novembre 2022 Ultima modifica di tallines : 28-09-2017 alle 14:04. |
||
|
|
|
|
28-09-2017, 13:56
|
#44 |
|
Senior Member
Iscritto dal: Feb 2009
Messaggi: 50674
|
Come funziona l’Hard Disk o disco rigido >
Il disco rigido è costituito da uno o più piatti, fatti di vetro o alluminio, rivestiti di materiale ferromagnetico, ogni piatto ha due testine che leggono e scrivono i dati scritti volando a pochi nanometri dalla superfice. Le testine non hanno nessun contatto con i piatti, rimangono sollevate grazie al cuscino d’aria che si forma con la rotazione del disco, ad hard disk spento le testine vengono posizionate sulla landing zone, un’area dedicata adibita a tale scopo, in alcuni dischi vi è un apposito supporto in plastica per parcheggiare le testine fuori dal piatto.  Come E' Fatto Un Hard Disk > I dischi sono chiusi in contenitori sotto vuoto, o in ogni caso non a contatto con l'aria esterna, in quanto hanno bisogno di un ambiente pulito, cioè senza particelle di polvere o altre resistenze superflue. Le testine di lettura e scrittura si trovano sopra e sotto ogni disco, come già visto, e ad una distanza ridottissima dai piatti, non toccando mai i dischi stessi, ma galleggiando su un cuscino d'aria sfiorando la superficie. la superficie dei dischi deve essere priva di impurità per evitare il contatto con le testine, che significherebbe procurare danni irreparabili (head crash). Se le testine entrano in contatto con il piatto di un disco la parte toccata si rovina, le testine si danneggiano, ed in più tutte le parti adiacenti, dove arrivano microscopici frammenti di superficie rotta (dal contatto), vengono come smerigliate. Le parti rovinate in questo modo non sono riparabili e c’è anche il rischio di perdere l’intero contenuto.
__________________
Aomei in Prog. & Utility - Lic OEM - Q di Merc Ott '22 - W10 Spot Images Seasons from '20 to Summer 2022 - DailyPic dalle Eccezioni alle Unique Images + Rec > DailyPic Unique Images Novembre 2022 Ultima modifica di tallines : 28-09-2017 alle 14:49. |
|
|
|
|
28-09-2017, 14:37
|
#45 | |
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
Quote:
Le colonne Current(Attuale) Worst(peggiore) Threshold(soglia) sono i valori Normalizzati (in base ad una scala propria e diversa da costruttore a costruttore e a volte anche da modello a modello) e significano "in linea di principio": Current = valore attuale del parametro (normalizzato dal valore RAW ovvero grezzo) Worst = valore di current più basso mai registrato durante la vita del disco Threshold = valore SOTTO il quale un diagnostico deve fornire un avviso di probabile fail Ho detto "in line di principio" perchè questo non vale in modo universale: cioè per TUTTI i valori smart allo STESSO modo e per TUTTI i produttori. Ci sono infatti parametri in cui: - a volte (produttore/modello) la scala è invertita (per esempio in tempo di avvio , Spin_up_time) - la soglia è 0 ma questo non significa nulla (temperatura) - la soglia è 0 ed assieme al "valore grezzo" è la sola cosa che conta. Magari un 4 (in decimale) nel valore grezzo è importante anche se "Attuale" e "Peggiore" non sono mai cambiati (vedi il tuo "settori scrittura pendente") - il valore grezzo di per se NON conta nulla ma è ad "Attuale" e "Peggiore" che bisogna fare riferimento rispetto al valore soglia (ed il tuo "errori lettura",in inlgese raw_read_error_rate, è uno di questi) Ora: il raw_read_error_rate ("errori lettura") è uno di quei paramteri che: 1 - preso da solo non ha NESSUNA valenza di criticità. 2 - è calcolato in modo molto diverso tra i vari produttori.Senza sapere come è stato implementato non è significativo, tanto che uno degli strumenti più affidabili di monitoraggio "Smartmoon Tools", nelle faq in proposito dice che : If no documentation is available, the RAW value of attribute 1 is typically useless. https://www.smartmontools.org/wiki/F...wreaderrorrate Spieghiamo i punti 1 e 2 con un esempio su un disco Seagate:  Quindi questo disco ha in raw_read_error_rate: attuale=76 peggiore=64 soglia=44 e dati grezzi = "number of hardware read errors" = 40136350 Come mai funziona ancora e la diagnostica non da errori ? Semplice perchè: Seagate usa quel valore per conteggiare GLI ERRORI E ANCHE i tentativi di lettura. Inoltre lo fa con un formato dati grezzi proprietario: QUESTO valore grezzo SMART sugli hd Seagate è di tipo words a 48-bit da convertire in esadecimale, poi Dell'esadecimale ottenuto i 16 bits alti rappresentano il numero di errori, i restanti 32 bits sono i tentativi di lettura totali (espressi sempre in esadecimale). Perciò 40136350 = 2646E9E in Esadecimale. Completiamo il formato in words a 48-bit che è 00002646E9E. I 16 bits alti sono 0000, gli ultimi 32 bits sono 2646E9E. Perciò ho 0 errori e 40136350 sono gli accessi in lettura. Qualche domanda: il software diagnostico seganala tutto Ok infatti ho zero errori Ma come mai il valore Peggiore è stato 64 mentre attuale è 76 ? Come mai nell'uso di quel disco le cose in lettura sono prima peggiorate e poi migliorate riguardo al raw_read_error_rate ma il dato grezzo è sempre rimasto 0 errori ? Prima di rispondere chiariamo un punto: Gli HD funzionano perchè sono fault tolerant. Ci sono SEMPRE tanti errori in lettura in un HD. A migliaia e in tutti gli HD. Solo che il firmware fa in modo (tramite algoritmi di correzione dell'errore, ECC) che questo non sia un problema. Banalizzando: se durante la vita del disco in alcuni settori si sono presentate troppo spesso (in base agli algoritmi ECC) anomalie in lettura allora essi vengono sostituiti "al volo" con una parte di disco di riserva non esposta al sistema operativo. Questo avviene in modo silente e non tocca il "reallocated_sector_count" perchè quei settori vengono giudicati sospetti dal firmware PRIMA che risultino magneticamente instabili. Ora la risposta: ci sono dei contatori nel firmware che tengono conto di queste "magie" e a lungo andare la cosa divenata sempre più problematica da gestire: quindi quel disco Seagate ha registrato in raw_read_error_rate ben 40136350 letture totali andate a buon fine (con errori poi risolti dal firmware) e zero errori diciamo "definitivi" cioè che evidenziano settori danneggiati sulla superficie del disco. Il firmware ha abbassato il valore fino a 64 perchè di "magie" ne stava iniziando a fare tante poi lo ha riportato su a76 perchè la situazione è migliorata. Ma gli errori sempre 0 sono rimasti. Per seagate in quel parametro va considerato Attuale VS Soglia e non il dato grezzo. Ed è un esempio notevole perchè quel tipo di disco può arrivare ad essere da buttare se il valore "Attuale" di raw_read_error_rate si avvicina troppo a 44 PUR RIMANENDO ANCORA A ZERO il valore grezzo degli errori hardware. Significherebbe che il firmware non può più correggere la valanga di errorri in lettura che tutti i dischi normalmente sperimentano. Smette di funzionare pur avendo la superficie magnetica "esposta" in perfetta forma mentre la parte "di riserva" sta finendo pericolosamente. Abbiamo quindi dimostrato, almeno per Seagate, che nel parametro raw_read_error_rate 1- il dato grezzo va interpretato in base al produttore 2- la parte di dato grezzo che identifica gli errori hardware può restare sempre inalterata = 0 mentre il firmware del produttore fa variare il parametro "Attuale" nel tempo spostandolo rispetto al valore soglia. Nel disco esaminato il valore si è abbassato a 64 pur rimanendo sempre 0 errori. Dimostriamo che ora anche per WD le cose vanno interpretate. Per WD sui modelli RED in questo parametro il massimo della scala è 200 e la soglia 51 Questo è lo smart report di un mio WD red 2tb in funzione h24 7 su 7 da 2 anni e mezzo: (usato come disco dati su una workstation che macina calcoli h24)  Come vedi in raw_read_error_rate ho 200 200 51 0 Mentre tu hai 200 200 51 489(in decimale) Io ho 0 errori, tu 489 ma come mai Attuale e Peggiore sono per entrambi 200 ? Il tuo peggiore dovrebbe essere più basso del mio. Invece per come è il firmware dei WD RED 489 errori in quel parametro non rendono quel disco prossimo al fail. Anzi non hanno abbassato nemmeno di 1 il current value e non lo hanno fatto mai nemmeno in passato tanto che anche Peggiore è 200.Ecco perchè la tua utily di diagnostica non lo segnala. Come prima per Seagate, così ora per WD il raw_read_error_rate è uno di quei parameteri che: preso da solo non ha NESSUNA valenza di criticità. Perchè il raw_read_error_rate ("errori lettura") è implementato in modo diverso da diversi produttori e NON significa automaticamente (per tutti i produttori/modelli) che dei settori della superficie del disco sono in deterioramento. Ecco quindi perchè quasi (cercando si trova sempre qualcuno che sbaglia) tutte le guide di riferimento non tengono conto di quel parametro e spesso succede che i software diagnostici non danno nessun avviso ma gli utenti si preocupano egualmente del dato grezzo. Partendo da wikipedia https://en.wikipedia.org/wiki/S.M.A.R.T. fino ad arrivare a citare proprio i report di backblaze (visto che per alcuni sono la bibbia): https://www.computerworld.com/articl...e-failure.html Backblaze's analysis of nearly 40,000 drives showed five SMART metrics that correlate strongly with impending disk drive failure: SMART 5 - Reallocated_Sector_Count. SMART 187 - Reported_Uncorrectable_Errors. SMART 188 - Command_Timeout. SMART 197 - Current_Pending_Sector_Count. SMART 198 - Offline_Uncorrectable raw_read_error_rate non è tra questi ovviamente. Ecco svelato il mistero. Quindi il disco ha dei problemi e lo sostituirei ma certo non per "errori lettura". I parametri lasciali gestire al software di diagnostica che è meglio. Infatti per i valori "settori riallocati" e "scrittura pendente" il diagnostico seganala il problema correttamente senza guardare i valori "attuale","peggiore","soglia" e considerando il dato grezzo anche se numericamente basso. Per errori lettura ignora il dato grezzo anche se è 489 e tiene conto delle colonne "attuale","peggiore","soglia". Non è magia: gli sviluppatori di questi software sanno quel che devono (non tutto: i produttori non dicono mai tutto del loro firmware) e come tarare la diagnostica in base ai vari parametri. Ovviamente quando escono nuovi modelli i firmware potrebbero avere comportamenti che per ai diagnostici generici sembrano anomali. Ecco perchè conviene usra il diagnostico del produttore ed a volte bisogna aspettare l'aggiornamento o del software diagnostico o del firmware.
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 28-09-2017 alle 15:43. |
|
|
|
|
|
28-09-2017, 15:11
|
#46 | ||
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
Quote:
Oggi sicuramente no. Oggi un hard disk (non ne parliamo un SSD) è quasi un computer a se anche se in miniatura. Vedi il mio post precedente : quel tipo di disco Seagate può arrivare ad essere da buttare se il valore "Attuale" di raw_read_error_rate si avvicina troppo a 44 PUR RIMANENDO ANCORA A ZERO il valore grezzo degli errori hardware. Significherebbe che il firmware non può più correggere la valanga di errorri in lettura che tutti i dischi normalmente sperimentano. Smette di funzionare pur avendo la superficie magnetica "esposta" in perfetta forma mentre la parte "di riserva" sta finendo pericolosamente. Quindi non è semplice come dici tu, ed ecco perchè quanto dici sotto (Mi spiace ma è proprio l'opposto) : Quote:
è smentito anche qui: https://www.computerworld.com/articl...e-failure.html come vedi .... ed è anche Backblaze che vi piace tanto. PS: La serie Purple di WD da alcuni tanto osannata è nata per fare videoriprese 24hsu24 e 7su7. Da varie parti si legge che questa serie avrebbe un firmware votato alle performance a discapito proprio della correzione degli errori: se salta un frame in un video la riproduzione resta possibile mentre un arresto del disco perchè dei settori stanno saltando e va avviata la diagnostica non è tollerabile perchè interrompe il servizio di videosorveglianza. Ovviamente vanno trovate conferme che per ora non sono riuscito a trovare (nella documentazione ufficiale ancora non ho trovato riscontri) ma allo stato attuale ,non avendo certezze in merito, io non salverei mai i miei dati su un disco per videosorveglianza Wd purple.
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 28-09-2017 alle 15:45. |
||
|
|
|
|
28-09-2017, 15:15
|
#47 |
|
Senior Member
Iscritto dal: Feb 2009
Messaggi: 50674
|
@ maurilio968
I Seagate sono una cosa > post n. 8 e post n.12 > http://www.hwupgrade.it/forum/showthread.php?t=2696733 Gli altri hd dove ci sono Errori lettura, la cosa è da prendere seriamente, non alla leggera, soprattutto se i valori grezzi continuano ad aumentare . Visto cosa è successo all' utente del link sopra, al post n. 26 ? Eppure aveva un super WD........stato di salute (Prestazioni e Salute) addirittura Eccellente........Questo disco è Perfetto, dice nella Descrizione sullo stato di salute del WD, HD Sentinel Durata stimata: Oltre 1000 giorni..............infatti......... Molti utenti, qui nel forum, dopo aver avuto errori alla voce Errori lettura, anche senza che il parametro Attuale scendesse solo di un numero.....poi hanno dovuto cambiare l' hd, in quanto è andato in tilt . Scommetto, che se B747 fa un test con il tool della casa madre, del suo hd, il test non lo passa, poi.....
__________________
Aomei in Prog. & Utility - Lic OEM - Q di Merc Ott '22 - W10 Spot Images Seasons from '20 to Summer 2022 - DailyPic dalle Eccezioni alle Unique Images + Rec > DailyPic Unique Images Novembre 2022 Ultima modifica di tallines : 28-09-2017 alle 15:20. |
|
|
|
|
28-09-2017, 16:04
|
#48 | |
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
Quote:
Per i casi che hai quotato: Intanto un disco può cedere per tanti motivi senza che lo SMART abbia avuto il tempo di avvisarti. Ci sono casistiche per tutte le marche di dischi morti con smart perfetto o con tutte le combinazioni possibili che possono venirti in mente. Qui stiamo facendo discorsi statistici basati su decine di migliaia di casi. Lo smart è uno strumento statistico: è statisticamente probabile che un disco con certi valori smart possa rompersi prima di altri. Possa, non debba. Infatti ci sono tanti casi in cui dischi con smart pessimo hanno continuato a funzionare (come dischi muletto son durati altri anni) mentre altri con smart ottimo sono morti improvvisamente. La domanda quindi è: quali sono i parametri smart statisticamente rilevanti da tenere sotto controllo? Detto questo per il resto getto la spugna. Ne sai di più te dei produttori, di chi fa software di diagnostica e di chi ha analizzato le rotture di decine di migliaia di dischi. Non è questione di Segate che è a parte come vorresti tu. Perchè nel mio WD red ho 200 200 51 0 e lui nel suo WD red ha 200 200 51 489 ? Perchè Worst non è cambiato ? E' un WD non un seagate. Come vedi anche WD gestice quel parametro in modo per te inconcepibile. "Errori in lettura" da solo non va mai considerato se il diagnostico non riporta allarmi. E questo non succede particamente mai. statisticamente un disco schianta prima per uno dei seguenti errori SMART 5 - Reallocated_Sector_Count. SMART 187 - Reported_Uncorrectable_Errors. SMART 188 - Command_Timeout. SMART 197 - Current_Pending_Sector_Count. SMART 198 - Offline_Uncorrectable E non lo dico io, lo dicono tutti. Ma invece no, dobbiamo ascoltare te che però ammetti di non saper interpretare in modo coerente i dati che hai davanti. Basta quotarti http://www.hwupgrade.it/forum/showpo...9&postcount=43 E' tutto un bho e faccine perplesse. Ma anzichè ammettere che hai sbagliato ed accettare una spiegazione che è perfettamente coerente anche con il comportamento dei software di diagnostica, preferisci pensare di aver ragione anche dovendo concludere che la tua interpretazione è intrinsecamente contraddittoria e che sostenendola i software di diagnostica divengono per te un mistero. In nome dell'onestà intellettuale dovresti smetterla di dare consigli agli utenti in questa materia. Non ne sai nulla.
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 28-09-2017 alle 17:00. |
|
|
|
|
|
28-09-2017, 21:16
|
#49 | ||||||
|
Senior Member
Iscritto dal: Feb 2009
Messaggi: 50674
|
Quote:
Se B747 vuol tenere l' hd da 3 Tb, se lo può tenere cosi com'è........io gli ho solo dato un suggerimento . L' utente può prenderlo in considerazione, come anche no, non è obbligatorio prendere in considerazione un suggerimento . Quote:
Quote:
Quote:
Perchè ho detto che la voce Errori lettura ha una sua importanza, perchè ho detto che le testine sono il cuore dell' hd ? Quote:
Quote:
Dato che le case che producono gli hd, non lo valutano come una cosa grave, allora quello che è riportato da wikipedia non importa.........leggere o scrivere dei dati non è importante............il ticchettio che magari qualche utente sente, non è importante................ Per me invece è da prendere in considerazione, se per te quanto detto da wikipedia non vale, per me si: Indica il numero delle volte in cui è capitato un errore di lettura hardware avvenuto leggendo un dato dalla superficie del disco. Un valore diverso da zero indica un problema della superficie del disco o delle testine di lettura/scrittura. Io do solo dei suggerimenti, se l' utente li vuole prendere in considerazione, li prende in considerazione, altrimenti, non li prende in considerazione, in quanto non è obbligato a farlo . Se ci saranno utenti che avranno errori alla voce errori lettura, io gli continuerò a dire di stare attenti che non aumentino e di allarmarsi . Gli errori lettura sono un problema meccanico, molto più grave dei settori riallocati o pendenti.......... Il fatto che tu venga a dirmi che io non devo......io continuerò a dare consigli, come ho sempre fatto . Se tu vuoi dare i tuoi consigli, dalli, nessuno te lo vieta e sicuramente io non vado in giro a dire ai vari utenti....se sbagliano di dare qualche consiglio, perchè avendo detto che gli Errori lettura sono da prendere in considerazione, ho sbagliato, secondo me no : "In nome dell'onestà intellettuale dovresti smetterla di dare consigli agli utenti in questa materia. Non ne sai nulla" anche perchè non è educato e decoroso, porsi in questa maniera . Se tu ne sai più di me, dai i tuoi consigli, nessuno te lo vieta, men che meno io . Sarà poi l' utente a valutare quali consigli prendere in considerazione . Praticamente ti sei arrabbiato, perchè abbiamo punti di vista diversi sugli errori, tu dai i tuoi consigli all' utente, oltre ai consigli che vengono dati da altri utenti, all' utente che ha chiesto un consiglio, un suggerimento . Come già detto, poi sarà l' utente che valuterà quale prendere in considerazione e quale no . Non sei tu che decidi....chi deve dare i consigli e chi no................ Io non mi sono mai permesso di dire a nessun utente, tu non devi dare consigli...............e non lo farò mai.......darò il mio consiglio e poi sarà l' utente a valutare .
__________________
Aomei in Prog. & Utility - Lic OEM - Q di Merc Ott '22 - W10 Spot Images Seasons from '20 to Summer 2022 - DailyPic dalle Eccezioni alle Unique Images + Rec > DailyPic Unique Images Novembre 2022 Ultima modifica di tallines : 29-09-2017 alle 11:41. |
||||||
|
|
|
|
28-09-2017, 21:23
|
#50 | |
|
Senior Member
Iscritto dal: Oct 2009
Messaggi: 25109
|
Quote:
e se in dec scrivi 1E9 cosa viene fuori? ed ero veramente distratto dato che in dec non poteva essere a due cifre colpa mia senz'altro, ma da qui a farmi passare per uno che "aggiusta la realtà" a proprio comodo anche no, grazie tra il privato prima e qui in pubblico sembra quasi che ti ho ammazzato il gatto per sbaglio se poi ci vuoi vedere per forza malafede chettedevodì  ciao ciao P.S. potresti creare un thread nuovo dedicato ai valori smart sulla base di quello che hai scritto qui, credo tornerebbe utile a tutti 
__________________
Pc - [LianLi Pc70]-[Corsair Ax860]-[Asrock z-170 extreme 6]-[Intel i7 6700k]-[16gb ddr4 Kingston HyperX Fury]-[Ssd 870evo 4Tb + 860evo 1Tb + 14Tb Toshiba MG + 16Tb Seagate Exos + 18Tb Seagate Exos]-[Lg 34gn850b]-[Razer D-Back Plasma Red]-[Windows 11 Pro 64bit 25H2 ]
|
|
|
|
|
|
03-10-2017, 18:28
|
#51 |
|
Senior Member
Iscritto dal: Apr 2007
Città: Roma
Messaggi: 755
|
grazie a tutti per i vostri pareri!
però a questo punto vado in confusione Infatti mi ritrovo con il report dei due HDD del pc dal quale scrivo, ovvero disco di sistema  disco dati  Per entrambi il parametro errori di lettura è pari a zero (e ne hanno di anni...) Però come la mettiamo con il Seagate appena acquistato per il NAS in sostituzione del WD?  Chi ha ragione? Va rimarcato che è un Seagate, ma cmq penso l'abbia detta giusta Maurillo968 ;-) Grazie ancora! Ultima modifica di B747 : 03-10-2017 alle 18:34. |
|
|
|
|
04-10-2017, 00:46
|
#52 |
|
Senior Member
Iscritto dal: Sep 2011
Messaggi: 6094
|
Premessa:
non ho intenzione di entrare nel merito della vicenda e né di immischiarmi nella questione che si è creata. Anche perché non ho le necessarie conoscenze in questo argomento. Quantomeno non di livello avanzato. E quindi non posso pronunciarmi più di tanto. Ma se può interessare, appena ho letto questo topic, lho trovato subito molto interessante e come dicevo, non avendo un livello avanzato per quanto riguarda la lettura e linterpretazione dello stato smart, mi sono appassionato a leggerlo per cercare di capire e approfondire meglio i dati smart. Cmq siccome largomento minteressa e ormai avevo la curiosità di capire la situazione reale e scoprire la verità, mi è venuto in mente che ho un amico ingegnere informatico e che praticamente questo argomento è il suo pane quotidiano, visto che lavora allestero proprio in questo settore, o meglio nello specifico risk consulting. E quindi ne ho approfittato per fargli leggere questo 3d Cmq per farla breve, ha dato ragione in toto a Maurilio968,.peraltro gli ha fatto anche i complimenti e ha detto che il ragazzo è in gamba e ha dato una bella spiegazione Non vi dico poi, cosa mi ha detto sullaffidarsi IN MODO SERIO E SCIENTIFICO su wikipedia non ne parliamo proprio E giusto a titolo informativo, se proprio vogliamo dare un po di considerazione a wikipedia, mi ha riferito che su wiki inglese la voce errori lettura non la dà come critico. Ed infatti controllando, è vero, ha ragione. Detto questo, invece, per quanto riguarda la questione di Aled, si vedeva che era in buona fede e poi quel calcolo non poteva mai uscire era chiaro che si fosse trattato di un errore di impostazione. Poi chi lo conosce sa che è una persona seria. E sia chiaro, cosi come Tallines, su questo ci mancherebbe altro... Diciamo che personalmente credo che su questo aspetto Maurilio968, poteva essere meno duro. Per concludere, sia chiaro che chi ha intenzione di rispondere al mio post, per piacere però non tiratemi in ballo e soprattutto in argomenti troppi avanzati di cui non fanno parte del mio settore. E quindi ripeto, in questo caso non potrei rispondervi in modo affidabile. Posso solo garantire che di questo amico mi fido molto e so che è uno di spessore @B747 Cmq per me quel Seagate dellultimo screen è a posto. Inoltre Click |
|
|
|
|
05-10-2017, 16:26
|
#53 |
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
ho messo le mani su diversi file di WD destinati ad uso interno.
Sto eleaborando il tutto Intanto vi annuncio che (ci vogliate credere o meno): Le modalità di funzionamento dei WD sono uguali a quelle dei seagate, solo che via firmware WD non espone il funzionamento interno degli algoritmi ecc quindi "errori lettura" non incrementa come per i seagte per non creare confusione negli utenti. SE quel valore incrementa in un WD bisogna guardare le colonne Attuale Peggiore Soglia e non il dato grezzo. Ecco una delle pagine in cui si spiegano alcuni aspetti dell'ecc dei WD:  tutti i WD classe consumer (blue,red,black,purple) sono di fatto lo stesso disco (attuatori,testine,qualità dei piatti, etc) ma differiscono per il firmware. Hanno poi tutti lo stesso AFR (annualized failure rate) che per WD è 0.88%. Questo dato non è pubblico e sui datasheet non c'è. tutti i wd classe enterprise (red pro, gold, raid edition) sono di fatto lo stesso disco (attuatori,testine,qualità dei piatti, etc) ma differiscono per il firmware. Hanno poi tutti lo stesso AFR (annualized failure rate) che per WD è 0.44% fino a 6 Tb e 0.35 oltre 6tb. Questo dato è pubblico e lo trovate per esempio sui datasheet dei gold. Curiosità: nei documenti interni i gold sono sempre con sigle che contengono RE e la dicitura Gold non compare mai. Se poi uno guarda il model number, per esempio wd4002fyyz, vede che nei documenti è associato alla dicitura WDxxxx_REx mentre nei datasheet pubblici semplicemente WD GOLD. Ovviamente i dischi enterprise sono costruttivamente diversi dai consumer: piatti migliori, attuatori diversi etc. Per esempio ho approfondito l'argomento unrecoverable read error (URE): la voce che nei vari datasheet riporta in genere <1*10^14 nei dischi consumer (per esempio wd red o purple) mentre è <1*10^15 per dischi di classe enterprise. Sembra un valore molto alto che non deve preoccuparci. Invece con le capienze di oggi ha molto senso guardarlo. Esempio: se avessi un disco da 10 TB e lo riempissi tutto che probabilità avrei che copiando tutti i dati su un altro disco da 10 TB si verifichi almeno un errore in lettura "unrecoverable" (cioè che il disco stesso non è in grado di correggere) e quindi i dati in arrivo contengono almeno un errore ? Ve lo dico io: in un disco consumer il 55% in un disco enterprise il 6%. E questo ogni volta che eventualmente copiate tutti i dati. Inoltre la cosa è molto più urgente se fate dei raid la cui capacità si spige oltre i 10 TB: l'integrity check dei sistemi raid è sul file system del raid, non sull'attendiiblità del dato che è compromessa da un URE ed al cresere delle dimensioni gli URE si verificheranno. Se faccio un raid da 90 TB e leggo tutti i 90Tb , anche usando dischi enterprise nel raid la probabilità di avere almeno un URE torna al 50%. Per ovviare agli URE serve ANCHE un file system in grado si eseguire un Data Integrity Checking sull'attività di letture e scrittura dei dischi. E questo,per ora,c'è solo nel file system ZFS. In ambito windows c'è ReFS e in linux si fa strada Btrfs ma non hanno ancora implementato quanto riesce a fare ZFS. Sono in ritardo perchè fino a poco fa 10Tb sembravano un enormità e la tecnologia degli HDD e dei file system è rimasta indietro rispetto al problema del crescere delle dimensioni degli archivi. Solo la defunta SUN (mai troppo da ringraziare per tutte le innovazioni che ha introdotto) ha sviluppato ZFS che però ora Oracle (sulla quqle preferisco non fare commenti) ha abbandonato. Non so se ho voglia di stilare una guida su come fare questi e altri calcoli e sugli stralci interessanti dalla documentazione che ho trovato. Il materiale è tanto e magari sarebbe da sottoporre ad un mod o direttamente a Corsini per farne uno o più articoli. Dico che non so se ho voglia perchè ormai io so come stanno le cose e di spendere tempo per dare tutti i dettagli (visto che nessuno mi paga) per poi dover perdere altro tempo a rispondere a tutti i "secondo me" che ne seguirebbero non ne ho voglia.Se ci fate caso in 11 anni di vita in questo forum ho postato solo 1600 volte. PS: A proposito delle differenze firmware che destinano i dischi ad usi diversi (imponendo carichi di lavoro diversi fondamentalmente allo stesso hardware): non sono differenze da poco per esempio per aled1974 Mi dispiace ma i purple NON vanno usati per l'archiviazione dati. Il firmware dei purple, come ho avuto modo di leggere, è finalizzato allo streaming dai dati attraverso un set di comandi ata abilitati su questo disco e non sugli altri WD.In sostanza il trasfert rate non deve mai abbassarsi quindi è accettabile perdere dei bit durante il processo di lettura/scrittura. Comunque basterebbe anche quello che dice un moderatore del forum WD in proposito: come puoi vedere qui:  Tanto è vero che i purple sono garantiti per 300.000 cicli mentre i red per 600.000 cicli: sai perchè? perchè la gestione del parcheggio testine nel firmware dei purple è diversa e ovviamente deve parcheggiarle molto meno (sempre per motivi di comandi ata che il firmware deve eseguire senza tempi morti). Questo sembrerebbe un vantaggio. All'epocainfatti tutti erano terrorizzati dai cicli cresenti nei WD green: hanno messo mano al firmware ed aumentato o disabilitato l'intervallo di parcheggio delle testine. E poi si lamentavano perchè il dischi green gli morivano improvvisamente quando li avevano forzati a lavorare fuori specifica. Infatti ad ogni parcheggio testine viene,tra le altre cose, anche movimentato il lubrificante negli attuatori che per questo degrada di meno. Infatti gli attuali Gold fanno un tipico ticchettio che spaventa gli utenti (che ne scrivono in vari forum) ma che è necessario proprio alla consistenza di funzionamento degli attuatori. Fortunatamente per i gold non si può mettere mano al firmware come con i vecchi green. Se lasci un HDD per anni in un cassetto senza accenderlo mai è facile che appena ricominci ad usarlo avrà dei problemi: UNO di questi è proprio per il lubrificante.
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 05-10-2017 alle 17:41. |
|
|
|
|
05-10-2017, 16:37
|
#54 | |
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
Quote:
Attualmente mi guadagno da vivere sviluppando database web-based per le PMI. Ovviamente l'integrità dei dati è fondamentale in qualsiasi ambito perciò mi preoccupo di dove e come salvare in modo consistente i dati delle aziende che si rivolgono a me. Spesso sono brusco se devo rispondere più volte alle stesse obiezioni perchè in merito ai forum (ed internet in generale) la penso come il compianto Umberto Eco. E poi guardando la mia firma si capisce subito che sono cattivo.
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 05-10-2017 alle 17:52. |
|
|
|
|
|
07-10-2017, 08:58
|
#55 |
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
Fonte: research paper di google fatto su più di 100.000 dischi nei suoi datacenter
https://research.google.com/archive/disk_failures.pdf Leggete il report per i dettagli. Lo studio suggerisce di dare una importanza relativa al monitoraggio smart e di usare sempre un backup per i propri dati. Però è interessante notare che in base a questi dati le seguenti due affermazioni ,contrariamente a quanto si legge in giro, sono smentite: 1- Più è bassa la temperatura di funzionamento e meno rotture avrò Invece, escludendo il range di temperature troppo alte  In the lower and middle temperature ranges, higher temperatures are not associated with higher failure rates. This is a fairly surprising result, which could indicate that datacenter or server designers have more freedom than previously thought when setting operating temperatures for equipment that contains disk drives. We can conclude that at moderate temperature ranges it is likely that there are other effects which affect failure. 2 - Se uso poco un hd mi durerà di più. Per esempio se ogni tanto ci copio sopra dei dati e tra una scrittura e l'altra lo tengo in un cassetto per mesi, alla fine durerà dieci anni o più invece livelli di utilizzo: Low 25 % , Medium 50-75 % , High 75%  dal terzo anno di vita vi è un inversione della tendenza: si guastano di più i dischi meno utilizzati. L'andamento suggerisce che: è bene stressare tanto il disco nei primi mesi di vita, se resiste durerà a lungo, se invece lo si usa poco all'inizio ed è un disco che si deve rompere perchè nato male, allora lo farà egualmente.
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 07-10-2017 alle 09:26. |
|
|
|
|
09-10-2017, 11:54
|
#56 |
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 1659
|
Trattiamo le ore di funzionamento e l'affidabilità (sul carico dati, cioè l numero di terabyte anno forse tornerò in post successivi ma fidatevi, è la solita solfa).
Fonte per la statistica completa su 5 anni e i modelli matematici Carnegie Mellon University: https://www.usenix.org/legacy/events.../schroeder.pdf Riporto la formula che lega AFR e MTBF: H = ore di funzionamento al giorno AFR = annualized failure rate in % da convertire in centesimi cioè se sul datasheet è scritto AFR=0.35% allora inserire 0.35/100 = 0.0035 MTBF = mean time between failure in ore (365*H)/AFR=MTBF Tutti i produttori, per tutte le classi di dischi, usano questa relazione. Per loro è solo matematica. Gli AFR che dichiarano sono solo virtuali e non derivano da test interni sull'affidabilità del particolare modello in questione. Nei test sul campo gli AFR reali riscontrati sono due tre volte quelli dichiarati nel primo anno di vita, per poi cresere sempre più fino a casi osservati di 10 volte quello che ci si aspetterebbe rispetto a quanto dichiarato nel quinto anno di vita. I dati parziali (sul "parziale" ci torno tra breve) di backblaze confermano in larga parte il trend generale dei dati completi: solo alcuni modelli (soprattutto HGST) hanno un AFR pari a quello dischiarato. Tolti pochi modelli, in generale vale la media, ora guardate nella tabella backblaz]e sotto, per esempio TUTTI i modelli 4 Tb nel complesso AFR=2%. Come leggerete su quel pdf, o tra poco qui se continuate, le statistiche si aspettano una media proprio del 2-4%. Nessun trucco, nessuna magia: è che gli HD "son tutti uguali" nel senso che sarà più chiaro in seguito. Quindi in realtà quello che conta è il dato MBTF, tanto l'AFR ve lo calcolate con la formuletta vista prima. Quindi se sue dischi hanno lo stesso MBTF e sono dati per funzionare h24 7 giorni su 7 avranno entrambi lo stesso AFR. Se l'afr è diverso e lo conoscete usatelo come dato nella formula di prima per calcolare H, cioè per quante ore al giorno in realtà il disco può funzionare. Nello studio statistico linkato all'inizio il modello matematico è più complesso di quello usato da backblaze e i dati sono consistenti per 5 anni: infatti backblaze fa uscire dalle statistiche i modelli che man mano dismette per rimpiazzarli con capacità maggiori. Perciò di alcuni modelli non sapremo il valore AFR al quinto anno perchè pur senza rompersi molti esemplari sono stati dismessi.Dico "sapremo" perchè backblaze parte dal 2013 quindi per imodelli continuativamente presenti i valori al 5 anno si avranno ad aprile 2018 (vedere la tabella riportata più avanti). Ora uno potrebbe supporre che per dischi molto più costosi e destinati ai data center le cose vadano diversamente. Infatti tutti i produttori vendono i dischi enterprise di classe SAS e/o fiberchannel FC come molto più affidabili dei dischi SATA. Purtroppo anche questo è falso. Dalla conferenza (che riporta poi lo studio della Carnegie Mellon) 5th USENIX Conference on File and Storage Technologies cito: we present and analyze field-gathered disk replacement data from a number of large production systems, including high-performance computing sites and internet services sites. About 100,000 disks are covered by this data, some for an entire lifetime of five years. The data include drives with SCSI and FC, as well as SATA interfaces. The mean time to failure (MTTF) of those drives, as specified in their datasheets, ranges from 1,000,000 to 1,500,000 hours, suggesting a nominal annual failure rate of at most 0.88%. We find that in the field, annual disk replacement rates typically exceed 1%, with 2-4% common and up to 13% observed on some systems. This suggests that field replacement is a fairly different process than one might predict based on datasheet MTTF. we observe little difference in replacement rates between SCSI, FC and SATA drives, potentially an indication that disk-independent factors, such as operating conditions, affect replacement rates more than component specific factors Cito un altra fonte sulla questione: https://permabit.wordpress.com/2008/...more-reliable/ A seguito di analisi come questa e quella di google linkata nei miei post precedenti,è nata la proposta, finora non accolta, di modificare il MBTF (indicato nell'articolo con sigla equivalente MTTF cioè mean time to failure) : Per esempio qui https://www.pcworld.com/article/1295...le.html?page=2 leggiamo While a general reputation for increased reliability (as well as higher performance) is one of the reasons FC drives cost as much as four times more per gigabyte than SATA, "We had no evidence that SATA drives are less reliable than the SCSI or Fibre Channel drives," said Gibson. "I am not suggesting the drive vendors misrepresented anything," he said, adding that other variables such as workloads or environmental conditions might account for the similar reliability finding. Ashish Nadkarni, a principal consultant at GlassHouse Technologies, a storage services provider in Framingham, Mass.,..Vendors do perform higher levels of testing on FC than on SATA drives, he said, but according to the study that extra testing hasn't produced "a measurable difference" in reliability..... urged customers to begin tracking disk drive records "and to make a big noise with the vendor" to force them to review their testing processes. E la proposta della Carnegie Mellon è: The common concern, that MTTFs do not capture infant mortality, has lead the International Disk driveEquipment and Materials Association (IDEMA) to propose a new standard for specifying disk drive reliability, The new standard requests that vendors provide four different MTTF estimates, one for the first 1-3 months of operation, one for months 4-6, one for months 7-12, and one for months 13-60. Prima di arrivare alle conclusioni abbiamo dei punti fermi: 1- se il disco ha un certo AFR dichiarato, con la formuletta calcolate le ore al giorno di utilizzo, viceversa se non c'è l'afr mettere H=24 e calcolatevi l'AFR. 2- nella realtà il tasso di guasto sarà almeno 2 volte l'AFR del punto 1 nel primo anno di vita, a salire negli anni successivi. 3- le statistiche complete su 5 anni (quella di google o quella qui linkata o alre analoghe che trovate in giro) ci dicono che in media l'afr atteso tende se vabene almeno il primo anno al 2% indipendentemente dal modello/produttore disco. 5- le statistiche parziali tipo backclaze (ricordo che hanno dati parziali) se vedete confermano il trend generale atteso del 2-4% delle statistiche complete su 5 anni. Andate per esempio a guardare il totale su tutto che al 2017 è, guarda un po' 1.97% 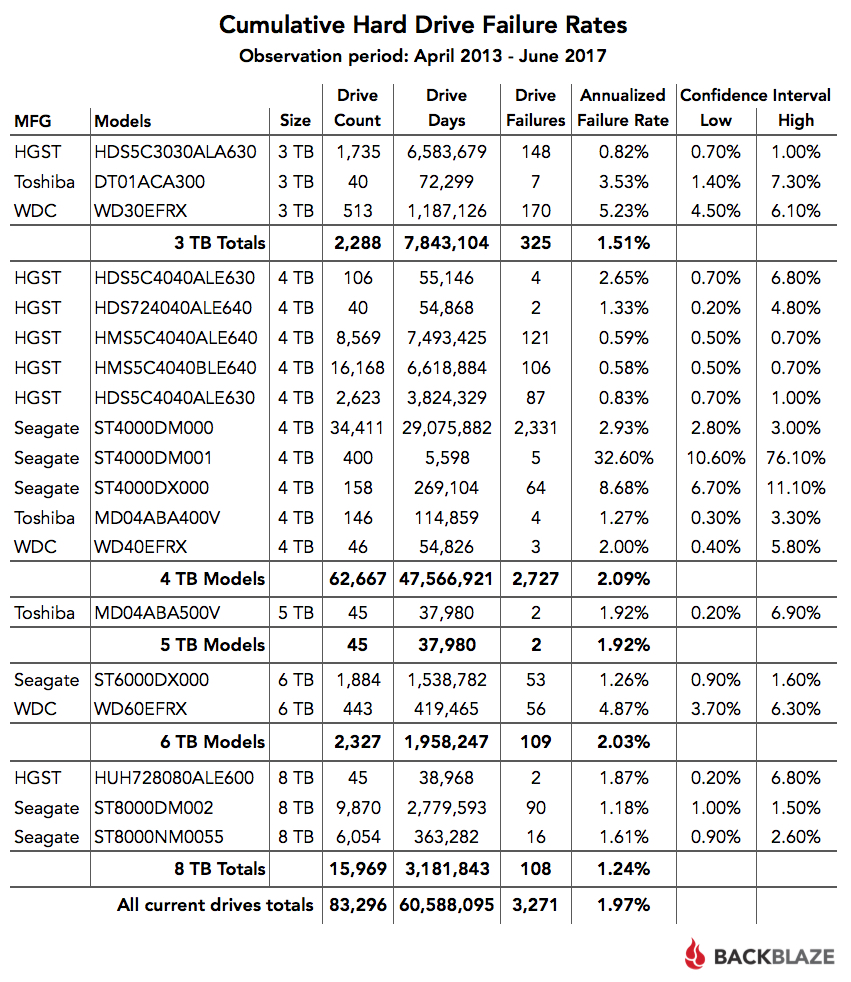 E cito ancora backblaze https://www.backblaze.com/blog/hard-...stats-q2-2017/ There are some insights we can gain from the current data. The enterprise drives have 363,282 drives days and an annualized failure rate of 1.61%. If we look back at our data, we find that as of Q3 2016, the 8 TB consumer drives had 422,263 drive days with an annualized failure rate of 1.60%. That means that when both drive models had a similar number of drive days, they had nearly the same annualized failure rate. Lo dicono anche loro: si aspettano che due dischi anche di diverse categorie e anche se di marche e modelli diversi (both drive models:enterprise drives e consumer drives) avranno lo stesso AFR di circa 1.61 quando saranno usati con lo stesso tipo di carico (similar number of drive days). Guardate nei datasheet e calcolatevi o leggete l'AFR per la maggior parte di quei dischi. Vale 0.88%. Quanto fa 0.88 * 2 ? Fa 1.66 %. Praticamente quello che backblaze misura e quello che l'articolo linkato all'inizo dice. Ovvero il punto fermo 2 poco sopra: nella realtà il tasso di guasto sarà almeno 2 volte l'AFR del punto 1 nel primo anno di vita, a salire negli anni successivi. Ma allora è uguale consumer o enterprise ? No, per esempio gli enterprise hanno un URE 10 volte migliore. di conseguenza ---> mia conclusione (ciascuno tragga le sue): Ovviamente comprate il disco con il valore MTBF più alto possibile il numero di anni di garanzia più alto possibille ed il dato URE più alto possibile compatibilmente con il vostro budget. Però pensate sempre che qualunque sia il produttore e qualunque cosa dichiari quel disco avrà in realtà un AFR del doppio di quanto dichiarato il primo anno, a salire nei successivi. Aspettatevi comunque un AFR di circa 2%-4%. Comprate un disco con il firmware adatto al tipo di utilizzo (per esempio non usare un videosorveglianza per storage saltuario) controllate periodicamente lo SMART tramite l'utility del produttore del disco e non fatevi altre seghe mentali basate sui "secondo me" o secondo l'esperienza di questo o quel utente che si è sempre trovato bene con x o male con y o su quello che vi vuole spiegare lui perchè l'utility del produttore x SBAGLIA a non segnalare errore sul tale parametro. A parte pochi casi di modelli particolarmente riusciti o particolarmente sfortunati i dischi consumer sono tutti uguali tra loro e quelli enterpsise tutti uguali tra loro (a patto di usarli propriamente ciascuno per ogni tipologia di utilizzo prevista). Il confronto va fatto, se proprio volete, tra consumer (con URE 10 volte più basso e MBTF più basso) VS entreprise (che hanno un URE sempre migliore e un MBTF spesso migliore) e non tra n-mila modelli consumer vs consumer. Sulla questione URE, ancora una volta è molto importante con dischi grossi e/o se fate raid, altra lettura: http://www.techrepublic.com/blog/the...d-errors-ures/ Come abbiamo visto la classe "super enterprise" come dischi sas e FC lasciatela perdere. Risparmiate i soldi. Perciò se in un certo momento trovate un WD Gold a meno rispetto ad un Seagate Enterprise con lo stesso datasheet, prendete il Wd. Se trovate a meno il Seagate prendete il Seagate. Non state a rincorrere quel particolare modello tanto nelle statistiche COMPLETE i punti fermii sono quelli qui discussi per tutti. A questo punto andare in giro a dire cose tipo: un WD BLU è peggio/meglio di un WD RED ; la differenza tra un RED ed un RED PRO è solo la velocità e qualche dettaglio sul firmware non vale la pena, TUTTI gli HGST sono meglio di un qualsiasi SEAGATE è totalmente privo di senso. Anche se so che ci sarà ancora sempre quello che salta fuori per dire "ma sei pazzo, i seagate (TUTTI) fanno schifo, ne ho rotti ben 3 invece WD mai rotto uno" e quello che dirà il contrario. E anche quello che dirà che ho scritto una valaga di cazzate (assieme a tutte le fonti che ho citato) e non è vero che (salvo assai rare eccezioni sia in positivo che in negativo, per questa loro rarità subito note anche agli utenti meno esperti) a pari MBTF, URE ed anni di garanzia i dischi sono tutti uguali (come affidabilità che tenderà al valore AFR=2-4%) e vanno usati in base al firmware (che non è un dettaglio).
__________________
ogni minuto muore un imbecille e ne nascono due. Ultima modifica di maurilio968 : 09-10-2017 alle 14:03. |
|
|
|
|
01-11-2017, 17:47
|
#57 |
|
Senior Member
Iscritto dal: Aug 2008
Città: Lat.: 45° 42′ 15′′ N Long.: 9° 35′ 15′′ E
Messaggi: 1531
|
Salve, ho dato una lettura al thread trovandolo molto interessante, grazie soprattutto al contributo dell'utente maurilio968: ciò anche se ha in sostanza frantumato la sensazione di essere abbastanza a posto per quanto riguarda la conservazione dei miei dati personali.
Mi affido ad un raid 1 con due dischi WD Green da 1 TB, quindi con URE scrauso <1*10^14  Il raid è gestito da una schedina pci con chip Silicon Image, inserita in un desktop pc obsoleto. Il sistema operativo è NAS4Free, il file system UFS. NAS4Free ad ogni accensione mi invia una email con il report smart relativo ai due dischi. Non adotto una tecnica particolare di backup. Semplicemente con rsync mantengo sul nas la copia aggiornata delle cartelle documenti e foto dei miei pc. Ho letto l'articolo http://www.techrepublic.com/blog/the...d-errors-ures/ ed ho compreso che la ricostruzione del volume raid in caso di guasti agli hdd può rivelarsi un incubo, in quanto la percentuale di errore è elevata. Però l'articolo si riferisce a volumi raid composti da parecchi hdd di grande formato. Nel mio piccolo, con hardware economico e hdd da 1TB il rischio di un errore durante la ricostruzione del raid è allora cosa praticamente certa? Se la risposta fosse si, tanto varrebbe dismettere il raid 1 e usare un banale disco esterno usb? Grazie per l'eventuale risposta.
__________________
Ultrabook: Lenovo ThinkPad X220, 8GB ddr3+zram, Intel i5-2520M, ssd S3+ 240GB, OS MX-Linux 23.6 Xfce SysV Tablet PC: Samsung XE700T1A, 4GB ddr3+zram, Intel i5-2467M, msata ssd 128GB, OS Artix Linux Plasma OpenRC NAS: Foxconn R30-A1 - Barebone SFF - AMD E-350, 4GB ddr3, hdd 4TB WD40EFRX, OS XigmaNAS 11.4.04 x64-embedded |
|
|
|
|
14-12-2017, 09:21
|
#58 | |
|
Senior Member
Iscritto dal: Jul 2000
Messaggi: 21363
|
Quote:
ovviamente saltato pure il quarto WD Red da 4Tb dopo 4 mesi dal termine della garanzia
__________________
[ ]_MacBook Pro (14", 2021)_macOS 26.3 | Studio Display_17| iPhone 13 mini_iOS 26.3| iPad mini (A17 Pro)_iPadOS 26.3 | WATCH S11 Ti _watchOS 26.3| tv 4K (2022)_tvOS 26.3 | AirPods Pro 3_8B34 |2x HomePod (2023)_26.3 Theater mode [ UniFi ] UDR7_5.0.13 UDB_6.5.87 UPS Tower_1.4.23 UniFi Network_10.1.85| Doorbell Lite, G6 Instant_5.1.240 Smart Chime_1.7.20 UniFi Protect_6.2.88|UNAS 2_5.0.12 UniFi Drive_4.0.12 |
|
|
|
|
|
14-12-2017, 16:06
|
#59 | |
|
Senior Member
Iscritto dal: Feb 2009
Messaggi: 50674
|
Quote:
Io non uso più WD da un bel pò e non li uso più . Mi trovo molto meglio con Hitachi, Toshiba e Seagate, non mi hanno mai dato problemi .
__________________
Aomei in Prog. & Utility - Lic OEM - Q di Merc Ott '22 - W10 Spot Images Seasons from '20 to Summer 2022 - DailyPic dalle Eccezioni alle Unique Images + Rec > DailyPic Unique Images Novembre 2022 |
|
|
|
|
|
14-12-2017, 22:05
|
#60 |
|
Senior Member
Iscritto dal: Jul 2000
Messaggi: 21363
|
Solo dischi con 5 anni di garanzia..almeno spalmo l'investimento anche si rompono dopo 5 anni ed una settimana
__________________
[ ]_MacBook Pro (14", 2021)_macOS 26.3 | Studio Display_17| iPhone 13 mini_iOS 26.3| iPad mini (A17 Pro)_iPadOS 26.3 | WATCH S11 Ti _watchOS 26.3| tv 4K (2022)_tvOS 26.3 | AirPods Pro 3_8B34 |2x HomePod (2023)_26.3 Theater mode [ UniFi ] UDR7_5.0.13 UDB_6.5.87 UPS Tower_1.4.23 UniFi Network_10.1.85| Doorbell Lite, G6 Instant_5.1.240 Smart Chime_1.7.20 UniFi Protect_6.2.88|UNAS 2_5.0.12 UniFi Drive_4.0.12 |
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 14:50.















