





WhatsApp, Facebook e Instagram down per oltre 6 ore! Cosa è successo e qual è stata la causa?

Quello registrato dai servizi di Facebook nelle ultime ore è un down totale e globale che ha pochi precedenti. Oltre 6 ore di blocco che hanno messo in ginocchio tutti i servizi di Menlo Park. Ma a cosa è successo e cosa ha causato il down? Ecco la spiegazione ufficiale.
di Bruno Mucciarelli pubblicata il 05 Ottobre 2021, alle 10:48 nel canale WebFacebookInstagramWhatsApp
È stata un fine giornata decisamente difficile quella appena passata che ha messo in ginocchio tutti i social network di Mark Zuckerberg. Parliamo di Facebook, Instagram ma anche WhatsApp che per oltre 6 ore non hanno funzionato del tutto, creando chiaramente grossi problemi a tutti gli utenti che erano soliti utilizzarli quotidianamente. I primi malfunzionamenti erano iniziati nella giornata di ieri pomeriggio quando Facebook, nel giro di qualche minuto è letteralmente "sparito da internet" e solo dopo 6 ore ossia nella nottata italiana le cose sono tornate lentamente alla normalità.
Facebook, Instagram e WhatsApp down: cosa è successo?
Intanto sappiate che non c'è stato alcun tipo di attacco hacker sui sistemi di Facebook, WhatsApp e Instagram. Nessuno ha attaccato i social di Menlo Park ma, come detto dagli esperti esterni, il problema è stato di natura tecnica e decisamente complesso. In questo caso un blocco così importante e soprattutto così duraturo non era mai capitato e chiaramente ha creato un grande caos nel mondo visto che ad oggi oltre 3.5 miliardi di persone utilizzano quotidianamente i tre social di Menlo Park e che questo permette a tutti di lavorare, di intrattenersi o anche di comunicare con altre persone. Non solo perché sappiamo bene che a Facebook, come anche agli altri servizi, gli utenti spesso hanno legato le loro attività e il problema di ieri chiaramente ha causato situazioni anomale anche da questo punto di vista.

L'ultima volta in cui Facebook, Instagram e WhatsApp erano ''caduti'' completamente risale al 2019 ma di fatto è capitato più volte che ci fossero stati dei problemi in modo random durante gli anni ma mai così duraturi e così invalicabili come quello di ierisera. E proprio Facebook, dopo circa 4 ore dall'inizio del down dei servizi, ha deciso di pubblicare direttamente sul proprio blog un comunicato in cui ha spiegato l'avvenuto agli utenti. Ecco cosa si legge nel comunicato:
A tutte le persone e le aziende in tutto il mondo che dipendono da noi, ci scusiamo per l'inconveniente causato dall'interruzione odierna delle nostre piattaforme. Abbiamo lavorato duramente per ripristinare l'accesso e ora i nostri sistemi sono di nuovo operativi. La causa alla base di questa interruzione ha avuto un impatto anche su molti degli strumenti e dei sistemi interni che utilizziamo nelle nostre operazioni quotidiane, complicando i nostri tentativi di diagnosticare e risolvere rapidamente il problema.
I nostri team di ingegneri hanno appreso che le modifiche alla configurazione sui router dorsali che coordinano il traffico di rete tra i nostri data center hanno causato problemi interrompendo questa comunicazione. Questa interruzione del traffico di rete ha avuto un effetto a cascata sul modo in cui comunicano i nostri data center, interrompendo i nostri servizi.
I nostri servizi sono ora di nuovo online e stiamo lavorando attivamente per riportarli completamente alle normali operazioni. Vogliamo chiarire in questo momento che riteniamo che la causa principale di questa interruzione sia stata una modifica alla configurazione errata. Inoltre, non abbiamo prove che i dati degli utenti siano stati compromessi a causa di questo tempo di inattività.
Persone e aziende in tutto il mondo si affidano a noi ogni giorno per rimanere in contatto. Comprendiamo l'impatto che interruzioni come queste hanno sulla vita delle persone e la nostra responsabilità di tenere le persone informate sulle interruzioni dei nostri servizi. Ci scusiamo con tutte le persone colpite e stiamo lavorando per capire di più su ciò che è successo oggi in modo da poter continuare a rendere la nostra infrastruttura più resiliente.
Come detto direttamente da Facebook, non solo ci sono stati problemi per i social e quindi per gli utenti ma addirittura molti degli impiegati e degli addetti ai lavori di Facebook a Menlo Park e in giro per il mondo hanno avuto seri problemi nel poter accedere alle postazioni di lavoro visto che il sistema di ingresso tramite badge è collegato direttamente al ''sistema Facebook'' e dunque inaccessibile in quelle ore. Impossibile per gli impiegati anche comunicare tra di loro e addirittura i tecnici inviati nei data center per la risoluzione del problema hanno incontrato blocchi negli ingressi agli edifici, che risultano anche questi automatici e connessi con il sistema Facebook.
Qual è stata la causa del down di Facebook e degli altri social?
Secondo gli esperti il problema accorso a Facebook nella serata di ieri riguarda sostanzialmente i protocolli BGP ossia i cosiddetti Border Gateway Protocol. Questi, in breve e in modo semplificato, sono sotanzialmente le mappe che indicano il percorso che i dati di un utente devono fare per raggiungere Facebook, e viceversa, nel modo più rapido ed efficace possibile. In questo caso alle ore 15:39 UTC qualche addetto ai lavori ha eseguito un aggiornamento agli indirizzi del BGP di Facebook e qualcosa è andato storto con Facebook che è praticamente sparito dal web. Effettivamente durante il blocco se si cercava Facebook sul web non si veniva indirizzati da nessuna parte perché i servizi di Facebook erano scomparsi da internet.
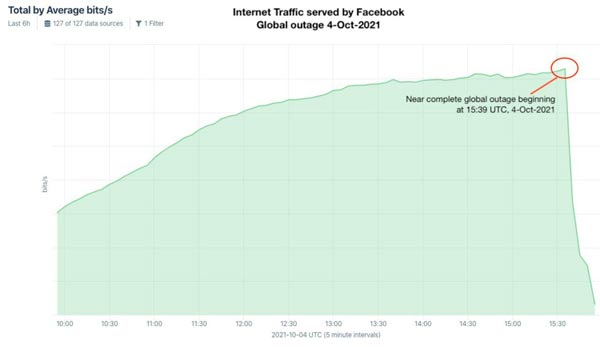
Chiaramente tutto questo ha portato poi a danni a cascata. Innanzitutto quei siti che integrano il codice di Facebook sono stati rallentati nella loro fruizione e di conseguenza anche i server DNS completamente intasati dagli utenti che si chiedevano cosa era successo e che tentavano di riaccedere al social network. I DNS, che sono sostanzialmente i sistemi che permettono di dare identità ai siti web ossia che permettono di dare un contenuto al nome del sito, sono andati in crash o comunque hanno avuto grossi problemi di rallentamento ovunque sul internet.
Il problema di tutto dunque sembra essere partito da un errore dell'aggiornamento della mappa di routing di Facebook. Di fatto però quello che colpisce è il tempo necessario a ripristinare l'intera piattaforma e tutto quello che è collegato ad essa. In questo caso, infatti, tutti i lavoratori di Facebook utilizzano Facebook per accedere alle loro postazioni e dunque per risolvere il problema non dovevano fare altro che accedere a Facebook che però non funzionava. Un paradosso che potrebbe però capitare a molte altre aziende oggi online. Si sapeva come risolvere il problema ma non si aveva accesso per risolverlo. Chi era in remoto non poteva dare seguito ai dipendenti presenti fisicamente al Data Center della California (sembra che tutto sia partito da lì) e chi era fisicamente in California non poteva accedere al Data Center fisicamente per impossibilità di utilizzare badge o altro. E non solo perché anche se avessero avuto accesso, senza possibilità di comunicare con gli altri addetti non avrebbero potuto risolvere in solitaria.

Insomma un problema importante per Facebook che ha causato una perdita di miliardi di dollari in borsa e che è stata effettivamente risolta dopo ben 6 ore. Risoluzione che, secondo le ultime indiscrezioni, sembra sia addirittura arrivata grazie al viaggio di chi sapeva dove mettere le mani nel data center.



 BOOX Note Air4 C è uno spettacolo: il tablet E Ink con Android per lettura e scrittura
BOOX Note Air4 C è uno spettacolo: il tablet E Ink con Android per lettura e scrittura Recensione Sony Xperia 1 VII: lo smartphone per gli appassionati di fotografia
Recensione Sony Xperia 1 VII: lo smartphone per gli appassionati di fotografia Attenti a Poco F7: può essere il best buy del 2025. Recensione
Attenti a Poco F7: può essere il best buy del 2025. Recensione DJI OSMO Mobile SE a 69: il gimbal compatto che trasforma i video dello smartphone in riprese da pro
DJI OSMO Mobile SE a 69: il gimbal compatto che trasforma i video dello smartphone in riprese da pro Scope elettriche da record su Amazon: due modelli potentissimi sotto i 120, ecco perché piacciono così tanto
Scope elettriche da record su Amazon: due modelli potentissimi sotto i 120, ecco perché piacciono così tanto GTA 6 a 80 euro? Take-Two frena sul prezzo e punta tutto sul valore percepito
GTA 6 a 80 euro? Take-Two frena sul prezzo e punta tutto sul valore percepito I 3 portatili più convenienti su Amazon: sono 2 tuttofare Lenovo e un HP Victus gaming con RTX 5060
I 3 portatili più convenienti su Amazon: sono 2 tuttofare Lenovo e un HP Victus gaming con RTX 5060 AirPods Pro 2 a soli 199: su Amazon anche AirPods 4 in sconto, ecco le differenze che contano
AirPods Pro 2 a soli 199: su Amazon anche AirPods 4 in sconto, ecco le differenze che contano 2 Smart TV 4K Hisense con doppio sconto su Amazon: sono OLED e QLED, 55" e 75", fateci un bel pensierino
2 Smart TV 4K Hisense con doppio sconto su Amazon: sono OLED e QLED, 55" e 75", fateci un bel pensierino Portatili Apple ai minimi: MacBook Pro con chip M4 a 1.648 e Macbook Air 13 16GB7256GB, sempre M4, a 998
Portatili Apple ai minimi: MacBook Pro con chip M4 a 1.648 e Macbook Air 13 16GB7256GB, sempre M4, a 998 Come mantenere Windows 10 sicuro dopo il 2025: tutto sul programma ESU
Come mantenere Windows 10 sicuro dopo il 2025: tutto sul programma ESU Finalmente è tornato su Amazon l'iPhone 16 128GB a 749, in tutti i colori, ma ci sono anche i 16e e 16 Pro in offerta
Finalmente è tornato su Amazon l'iPhone 16 128GB a 749, in tutti i colori, ma ci sono anche i 16e e 16 Pro in offerta Auto nuove? Per il 65% degli italiani sono troppo care, non dovrebbero costare oltre i 20.000 euro
Auto nuove? Per il 65% degli italiani sono troppo care, non dovrebbero costare oltre i 20.000 euro Droni solari Airbus volano nella stratosfera grazie alle nuove batterie al silicio: test riusciti a oltre 20 km di quota
Droni solari Airbus volano nella stratosfera grazie alle nuove batterie al silicio: test riusciti a oltre 20 km di quota Colpo da 15 milioni di dollari: chi ha rubato un carico di prodotti AMD e Apple?
Colpo da 15 milioni di dollari: chi ha rubato un carico di prodotti AMD e Apple? Elon Musk lancia l'allarme su GPT-5: 'OpenAI divorerà Microsoft'. Ma Nadella lo sfida con un sorriso
Elon Musk lancia l'allarme su GPT-5: 'OpenAI divorerà Microsoft'. Ma Nadella lo sfida con un sorriso iPhone 17 Pro sarà più costoso, ma anche più conveniente
iPhone 17 Pro sarà più costoso, ma anche più conveniente



























26 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoMi stupisce piuttosto che la cosa sia stata gestita come un single point of failure... Non e' tanto un discorso di ridondanza dei dispositivi, quando l'idea di voler aggiornare tutto di botto, senza farlo ad incrementi sulle varie macchine, in maniera tale che se qualcosa va storto nell'aggiornamento comunque ci sono le altre che comunque funzionano...
Ma e' anche vero che di queste cose io sono nel picco del diagramma di Dunning-Kruger, quindi ci sara' una barcata di roba che non conosco a riguardo... Certo che non deve essere stata una bella esperienza per chi ha pigiato il bottone...
Hai presente Fantozzi ? Ecco Zucckonbergo gli avrà fatto fare la stessa fine...
Link ad immagine (click per visualizzarla)
...peccato che sia stato "solo" questo il problema. Sarebbe stato meraviglioso se invece avessero tritato tutti i dati - whatsapp, facebook, tutto...tabula rasa...backup compresi !
Tanta gente si sarebbe risvegliata e sarebbe tornata ad interagire con il prossimo in maniera degna. Ma ormai non si torna indietro. Spero che certi individui però si rendano conto che spipettare nei social mentre si è alla guida può portare loro e il prossimo al camposanto.
Anche per loro c'è il direttore giusto da Fantozzi....VISCONTE COBRAM !!!
Quello che gli facevano pena e schifo gli impiegati che usciti dal lavoro tornavano a casa invece di farsi una bella sgambata fuori città !
...A PINEROLO !!!
Ancora ?!? Son senza pietà, la pandemia non gli è bastata ?!?
Le modifiche di questo tipo si fanno solo in produzione, non esiste e non può esistere un ambiente di test, e sono puntuali, quindi quando la fai interessa tutto il traffico, non ci sono alternative.
Quello però che trovo assurdo è che abbiano legato qualsiasi operatività ai sistemi di Facebook, così se per caso vanno a ramengo non puoi collegarti ai server per sistemare le cose.
In teoria dovrebbe essere previsto un sistema alternativo e slegato per l' accesso proprio nel caso in cui il sistema principale sia down, ma metterlo dietro a una porta che richiede che il sistema sia funzionante non è esattamente una idea brillante.
Credo che una porta costi molto meno di 5 minuti di down per Facebook
Link ad immagine (click per visualizzarla)
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".