





|
|||||||


|



|
|
 |
|
|
Strumenti |
 19-02-2014, 11:12
19-02-2014, 11:12
|
#41 |
|
Senior Member
Iscritto dal: Mar 2000
Città: Napoli (Pozzuoli)
Messaggi: 1528
|
50w contro 150w..
quanto sono i consumi differenti.. 0.86 centesimi per 3 ore al giorno in un mese intero.. Almeno su recensioni in spagna.. quindi tutta sta fuffa per risparmiare 1 euro al mese, avere meno mantle, meno prestazioni, meno open cl.. ma almeno quando mi scatta il gioco potrei dire.. guarda che efficienza ejeje non facciamoci fregare dal marcheting, non parliamo di 50-500watt e poi ste schede sono quasi sempre in idle nei pc.. ho sempre la senzione che quando una scheda é una cagata sparano consumi, temperature ecc.ecc. ma quel che serve a una scheda gaming é che sia veloce ed abbia il miglior rapporto prezzo/prestazioni |

|

|
|
19-02-2014, 11:58
|
#42 | |
|
Senior Member
Iscritto dal: Oct 2008
Messaggi: 6948
|
Quote:
Comunque concordo, le prestazioni per queste potenze sono decisamente interessanti, imho una novità molto più interessante sia delle R7 che della GTX Titan Black, anche se magari ciò non si traduce in un best buy (che dipende più dalle esigenze). Alla fine comunque vorrei far notare che con il prezzo al kWh in Italia con 30W di differenza si recuperano relativamente in fretta in 20 (circa 1000 ore)
__________________
|
|
|
|
|

 = h ν
= h ν|
19-02-2014, 12:03
|
#43 | ||
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4187
|
Quote:
Se poi i tuoi riferimenti sono SiSandra, be', sì, AMD ha un vantaggio infinito. Per quanto riguarda i core ARM, anche a te è sfuggito un piccolo particolare: nvidia non è AMD. nvidia non aspetta che terze parti sviluppino soluzioni per lei. nvidia sviluppa quasi tutto in casa, il che vuol dire che se mette dei core ARM dentro le sue GPU ha anche il piano di sviluppo SW per supportarli. Le librerie CUDA saranno sicuramentre aggiornate per sfruttarli. Ora io non so cosa possono fare questi core ARM né come verranno sfruttati, ma non è detto che non possano aiutare a dare un boost anche in campo puramente di accelerazione 3D sgravando la CPU e diminuendo di brutto le latenze, quindi "basterebbe" aggiornare anche i driver DirectX. 'sto miracoloso (quanto fantomatico) HSA ha veramente mandato in corto circuito i neuroni di molti, mi sa. Quote:
1) E' una scheda low end come ce ne sono sempre state. Come tutte le schede low end fa cagare se raffrontata alle mattonelle da mezzo Km quadro e 300W di consumi. Ma, per quanto tu le trovi schifosissime, le schede low end vendono come il pane e quindi vedere che con le stesse prestazioni sono passati a dimezzare i consumi senza cambiare il PP significa che non si parla di fuffa per nulla. 2) Ti sfugge il corollario dell'aumento di efficienza, sia in termini di consumi che di spazio/transistor: le GPU più grandi, che sono limitate dai consumi, a 300W potranno generare una potenza di calcolo nettamente maggiore perché potranno integrare più risorse. Oppure, a parità di performance con quelle odierne possono consumare molto meno. O (in teoria, il mercato è altra cosa) costare di meno perché realizzate con meno silicio. Se non arrivi a comprendere queste implicazioni, non è colpa del marketing "fuffa" che tanto accusi. La necessità del rapporto prezzo/prestazioni per una scheda gaming è un problema ricorrente che si pone solo una parte dell'utenza: quella che non arriva all'uva e si accontenta dei lamponi che crescono più in basso. |
||
|
|
|
|
19-02-2014, 12:20
|
#44 | |
|
Senior Member
Iscritto dal: Jul 2003
Messaggi: 26791
|
Quote:
p.s. 3 ore per 365 giorni fa 22 euro all'anno. L'eventuale differenza di prezzo te la ripaghi tutta e dopo ci guadagni pure. Inoltre meno consumi significa anche meno calore, più durata e più silenziosità. |
|
|
|
|
|
19-02-2014, 12:44
|
#45 | ||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4382
|
Quote:
1) l'architettura maxwell ha una complessità maggiore di quella kepler. il guadagno reale delle prestazioni per transistor è pari al 13%..nulla di incredibile, siamo ai livelli del passaggio da vliw-5 a vliw4 per intenderci. 2) nvidia è riuscita ad infilare la bellezza di 12,6 Mtransistor/mmq contro gli 11,2/mmq. siamo a +12%. 3) quindi le prestazioni per mmq sono salite di un fattore non trascurabile, +27% 4) allo stesso tempo il consumo per transistor si è ridotto drasticamente: -40% sono sicuro al 99% che è cambiato il PP... Quote:
Ora è vero che gk106 ha il 35% più risorse(transistor) di un gm107, ma le prestazioni non sono esattamente le stesse (+23%) come dicevo poco sopra...il miglioramento c'è stato ma non è incredibile se non guardiamo i consumi. Ultima modifica di tuttodigitale : 19-02-2014 alle 14:28. Motivo: sintetizzo |
||
|
|
|
|
19-02-2014, 13:15
|
#46 | |
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4187
|
Quote:
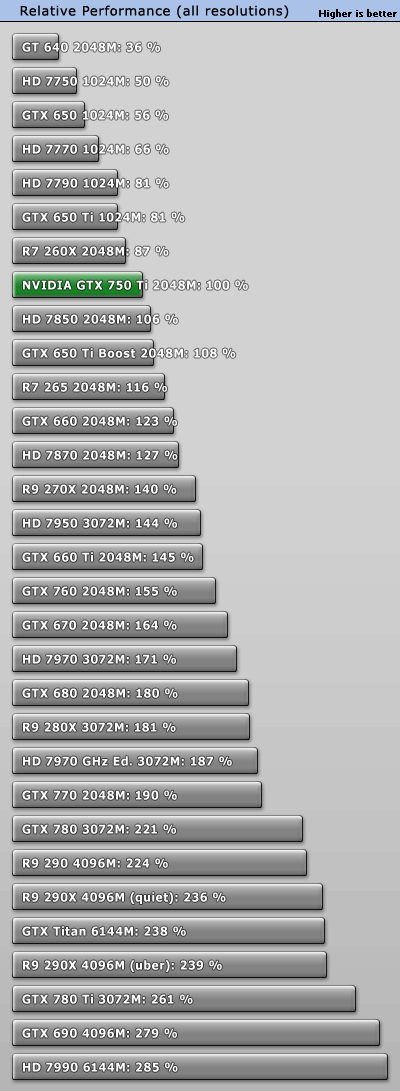
Se fai una statistica sulle prestazioni pure, che un chip sia castrato o meno poco conta: fai i conti di quante risorse uno ha e quante ne ha l'altro e fai il rapporto. Se fai un'analisi di consumi hai ragione sul fatto che il GK106 in considerazione è castrato e quindi non è il massimo della comparazione. Ma le 650Ti/Ti Boost consumano comunque meno delle 660 con Gk106 completo e il 23% di performance in più è ottenuto con oltre il doppio del TDP e il 50% in più di silicio. Se guardo ai risultati concreti, oggi ho le stesse prestazioni di una 650 Ti Boost con quasi metà consumi e il risparmio del 50% di area. Se faccio un paragone con il 660 completo ed estrapolo per le mattonelle più grandi (cosa che non dico sia vera, ma comunque è un'operazione più che lecita e fattibile) posso prevedere una mattonella da 550mm^2 (grande quindi come il GK110, GF110, GF110 e il G200) che contiene più di 3000 shader in 24 SMM (non più 15), una capacità di calcolo più che tripla (vedere i test GPGPU di questa 750Ti) e con un consumo di circa 150W. Il tutto usando i 28nm (che siano una nuova versione o meno poco conta). A me sembra un miglioramento notevole, certamente migliore di quello che è stato proposto con Hawaii che non ha modificato nulla in termini di efficienza ma è stato solo una nuova mattonella con tanti shader (e Watt) in più. Se i prossimi mesi saranno davvero caratterizzati dal mantenimento del processo produttivo a 28nm, mi sa che "questo non incredibile vantaggio" come lo hai definito tu porterà grandissimi grattacapi a AMD. A meno che questa non abbia in serbo qualcosa d'altro che per ora ha tenuto super segretissimo o che nvidia non voglia fare i più grandi chip Maxwell a 28nm per evitare costi aggiuntivi. Solo il futuro ce lo dirà, ma non neghiamo che questi "insignificanti vantaggi" aprono diversi scenari che non si sospettavano prima della presentazione di questo GM107. Ultima modifica di CrapaDiLegno : 19-02-2014 alle 13:23. Motivo: Modificato il numero di shader: usato il rapporto di guadagno sui nuovi SMX invece che di superficie. |
|
|
|
|
|
19-02-2014, 13:36
|
#47 |
|
Senior Member
Iscritto dal: Feb 2003
Città: 134340 Pluto - [VL]
Messaggi: 8520
|
Domandina ina ina...
Se montassi la GTX 750ti 2GB su di un E8400 con 8Gb di ram con monitor da 1680x1050, dite che sarebbe cpu limited oppure potrebbe essere un upgrade sensato? Nel caso che VGA proponete voi che non sia cpu limited con spesa massimo di 150? Ciao e Grazie |
|
|
|
|
19-02-2014, 13:43
|
#48 | |
|
Senior Member
Iscritto dal: Jun 2004
Messaggi: 1379
|
Quote:
nel treddo dell'ungine heaven un tizio ha benchmarcato una 650 ti ottenendo 461 (mi pare). Con le stesse opzioni facevo 379 con la gtx 460 da un giga. Inoltre un po' di tempo fa ho montato un pc ad un amico e gli ho messo la 650ti. Sebbene con un Pentium dual core (ivy bridge) la sensazione era che la sua scheda andasse un poco meglio della mia. A spanne non credo ci siano più del 30% di prestazioni fra 750ti e 460gtx da un giga. in più e sempre a spanne penso che quel 30% non siano tanto nella potenza "bruta" quanto nel supporto per le puttanate nuove (leggasi che a spanne i giochi non nuovissimi probabilmente avranno una differenza ancora inferiore). Probabilmente va un poco peggio di una 560ti. Per cui se dovessi cambiare gpu (e volessi restare con nvidia) terrei d'occhio il mercatino per vedere se qualcuno vende una 660ti o una 760 a buon prezzo. il tutto sempre secondo me Ultima modifica di homoinformatico : 19-02-2014 alle 13:46. |
|
|
|
|
|
19-02-2014, 13:44
|
#49 | ||||||||||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4382
|
Quote:
Quote:
Quote:
Quote:
Quote:
[ Quote:
Quote:
Certe uscite Quote:
Quote:
E' assurda perchè nonostante kaveri abbia di fatto annullato la disparià di trattamento tra cpu e gpu, le latenze delle dx11 rimangono.... Quote:
PS parlare in quel modo di hUMA, quando è la tecnologia più innovativa in campo informatico degli ultimi 15 anni..... |
||||||||||
|
|
|
|
19-02-2014, 14:08
|
#50 | ||||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4382
|
Quote:
e sulle prestazioni per mmq ho detto questo Quote:
Quote:
Tu parli di core, ma ometti il fatto che maxwell necessiti di un +32% di transistor in più a parità di forza bruta. Ti ho già detto che con il passaggio da kepler a maxwell le prestazioni a parità di risorse (transistor) a parità di clock sono aumentate del 13%. Punto. Quote:
Quello che voglio dirti è se il singolo transistor consuma la metà mi riesce difficile pensare che sia merito dell'architettura... Non è mai successo. IMHO, il PP è cambiato anche se il nanometraggio è rimasto invariato. |
||||
|
|
|
|
19-02-2014, 14:11
|
#51 |
|
Senior Member
Iscritto dal: Feb 2004
Messaggi: 497
|
La cosa più divertente di tutto questo è che queste nuove schede di fascia bassa permettono OGGI di raggiungere la grafica delle console nex gen(qui si paral di xbox ma la PS4 non farebbe certo meglio):
http://www.gamespot.com/articles/149.../1100-6417813/ -_- La grafica dei giochi resterà zavorrata a grafica "non al passo coi tempi" ancora per anni e anni. |
|
|
|
|
19-02-2014, 14:38
|
#52 | |
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4187
|
Quote:
I core ARM sono ARM. Che vuol dire che se non li progetta nvidia non li può sfruttare? A parte il fatto che non sai se sono core standard o rifatti da nvidia per essere più efficienti in questo o quel campo (consumi/area/prestazioni) o integrano estensioni particolari per fare lavori particolari (ARM supporta nativamente unità di calcolo esterne di diversa natura, lo sapevi?). Detto questo, ancora non ho capito cosa non ti è chiaro che se ci sono potranno essere sfruttati da nvidia direttamente e non lasciate a carico del programmatore tramite accesso diretto. Cioè, è possibile che siano messe a disposizione anche esternamente alla GPU, ma non è un dogma, e come per quasi tutto quello che c'è nella GPU potrebbero benissimo essere delle unità che si occupano di fare compiti in maniera totalmente autonoma a cui il programmatore non può avere accesso diretto (forse il programmatore ha accesso all'unità che fa lo scheduler dei thread all'interno della GPU?). HSA è una cosa, integrare delle unità di calcolo seriale in un dispositivo che per natura è solo parallelo è un'altra cosa. Ritorno a dire quindi che non sapendo come sono integrati e cosa facciano di preciso è un po' dura inventarsi che solo tramite HSA su PCI siano sfruttabili. O che siano né più ne meno HSA su PCI. HSA qui non c'entra un bel niente. Certamente non saranno unità messe lì completamente staccate dal resto della GPU, come appunto fossero dei coprocessori montati su un'altra scheda PCI. Quali vantaggi darebbero? Poi fai confusione tra HSA e hUMA. Sono 2 cose distinte. HSA è fuffa di un'azienda che non ha altro da offrire per tentare di recuperare il gap che si è creato tra lei e la concorrenza. E' un modo di dire, noi abbiamo questa possiblità, non valutando il fatto che ha utilità quasi pari a zero. Se la mattina bevi latte e marketing, allora ti ingrassi bene di queste cose. Se invece la mattina insieme al latte studi un po' di informatica (generalmente parlando) sai che HSA applicata alla sola GPU copre una quantità di soluzioni pari a quelle delle tue dita di una mano. E sono pressoché inutili sui PC consumer. Qui si parla di usare le capacità di calcolo seriale di uno (o più componenti, non so quanti siano questi core che saranno integrati né che potenza/capacità avranno) per aiutare un altro componente che esegue istruzioni in maniera efficiente solo parallelamente. Far fare un salto o prendere una decisione di flusso ad una GPU è un trauma. Non c'è hUMA (che non è un'invenzione AMD e quindi non è la più grande innovazione degli ultimi 15 anni, al massimo è un ritorno al passato dimenticato dal marketing di Intel e di AMD stessa che in tutto questo tempo si sono concentrate a fare architetture monolitiche general purpose per risolvere tutto il pensabile in maniera estremamente inefficente) o HSA (pure questa una nuova etichetta appiccicata a qualcosa che esiste da tempo immemore) che tenga in questo caso. Le GPU fino a ieri erano fatte così e quei problemi hanno. Rivedere le capacità intrinseche delle architetture estremamente (ed esclusivamente) parallele è un passo in avanti da quando si è deciso di usare le unità grafiche per fare calcoli (che avveniva ben prima di R600, G80, CUDA, o OpenCL in maniera estremamente inefficiente). Quali siano i reali vantaggi che porterà questa innovazione ancora non lo sappiamo, ma ripeto, non è questione di usare i core ARM (o qualsiasi altra risorsa aggiunta) tramite esplicito codice HSA ma di fare in modo che queste unità diano automaticamente una mano agli SMM quando questi hanno evidenti problemi ad eseguire parti di codice (o di un algoritmo) in maniera efficiente. Il fatto che tutti parlano di HSA come fosse la panacea di tutti i mali e invece declassino queste innovazioni come una (inutile) parte di HSA mi sembra un'assurdità. O non si è capito nulla, o si sta cercando di includere queste innvazioni nell'inutilità di HSA per come è stata presentata fino ad oggi. Ebbene, non credo che nvidia abbia lavorato tutti questi anni sul progetto Denver per aggiungere dei core ARM semplicemente collegati ad un bus PCI per dire: eccoli a voi, fatene quello che volete, trovate voi il modo di sfruttarli con le altre unità di calcolo. Non ci avrebbe messo così tanto tempo e non lo avrebbe sicuramente fatto se non fosse stata sicura che questa aggiunta porta davvero ad aumentare l'efficienza della sua architettura. I benchmark che portano Kepler ad avere il migliore rapporto prestazini/Watt sono quelli usati sui server HPC che sono tutt'altra cosa rispetto a quelli fatti in OpenCL e dove le GPU sono usate per ben altra cosa che fare coin mining. Per quello ho parlato di confronto anche con la Xeon Phi. Ma vabbè, torna pure ad aspettare che HSA faccia qualcosa di utile mentre il resto dell'umanità nel frattempo gode dei risultati delle ricerche fatte con qualcosa che funziona per davvero. |
|
|
|
|
|
19-02-2014, 15:00
|
#53 | |
|
Senior Member
Iscritto dal: Feb 2000
Messaggi: 11166
|
Quote:
__________________
PC 1 : |NZXT 510i|MSI PRO Z690 A|I5 [email protected] Ghz (Pcore) 4.5 Ghz (Ecore)|AIO ENDORFY NAVI F280|32 GB BALLISTIX 3600 cl 14 g1|GIGABYTE 4070 SUPER AERO OC|RM850X|850 EVO 250|860 EVO 1TB|NVMe XPG-1TB||LG OLED C1 - 55 | PC 2 : |Itek Vertibra Q210|MSI PRO B660M-A|I5 12500|32 GB KINGSTON RENEGADE 3600|ARC A770 LE 16 Gb|MWE 750w| ARC 770 LE 16 Gb Vs RTX 3070 - CLICCA QUI |
|
|
|
|
|
19-02-2014, 15:03
|
#54 | |
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4187
|
Quote:
ll tuo 13% è puramente teorico (proprio tu che parli di cose teoriche vs quelle reali). Io vedo una GPU che monta il 20% in più di shader, il 50% in più di ROP, il 60% in più di TMU e ha un bus il 50% più grande per una banda complessiva superiore del 70% che riesce a malapena stare sopra il GM107. (non faccio confronti tra le dimensioni perché come hai ben detto uno è un chip castrato, mentre l'altro no). Lascio a te il compito a casa di fare il confronto con il GK106 completo e il suo 23% in più di performace. Alcuni bench GPGPU mostrano che la nuova GPU va almeno il doppio rispetto al 660 completo. E consuma la metà. Di cosa stiamo parlando? Del 13% sulla carta con il calcolo transistor/spazio o del fatto che tutta la nuova architettura a parità di prestazioni fa risparmiare il 33% del silicio e dimezza i consumi? Prendi un GK110, applicaci la stessa equazione che ti porta dal GK107 al GM107 e vedi cosa ottieni. Che poi fai il finto tonto e dici, si ma vabbè, nulla di che... cosa ha guadagnato AMD 2 mesi fa passando da GCN1 a GCN2 (Tahiti vs Hawaii)? Nulla, solo più unità di calcolo in più spazio per più consumi, tutto proprozionalmente. Qui si dice che se va male si hanno il 50% in più di prestazioni sulla stessa area con consumi quasi dimezzati usando lo stesso PP.. cioè più di quanto AMD abbia fatto tra VLIW e GCN con l'aiuto di uno shrinking e si viene a dire: ma no, non è poi così una grande cosa, tutto nella normalità. Ebbena, come detto, a meno che AMD non abbia in serbo qualcosa di nascosto e di analogo, questo "piccolo" aumento di efficienza diventerà un grande problema per lei. Tutti che elogiano Mantle che porterà presunti vantaggi in uno o due titoli di punta e si gira la testa quando si vede questo tipo di performace che andranno a influire su tutti i titoli non necessariamente basati su un singolo motore ottimizzato per una particolare architettura. E non abbiamo ancora visto cosa ci riservano le future GPU con i core ARM integrati, ma per correttezza, probabilmente quelli li vedremo tra molto tempo, al pari di quando vedremo queta benedetta API MAntle maturare per rendere reale almeno in parte quello che è stato promesso. |
|
|
|
|
|
19-02-2014, 16:53
|
#55 | |
|
Senior Member
Iscritto dal: Sep 2009
Messaggi: 5582
|
Quote:
http://www.anandtech.com/show/7764/t...review-maxwell "What is that fundamental shift? As we found out back at NVIDIAs CES 2014 press conference, Maxwell is the first NVIDIA GPU that started out as a mobile first design, marking a significant change in NVIDIAs product design philosophy. " come vedi non sono io a dirlo, ma nvidia stessa, che sta facendo convergere tegra k1 a maxwell, e quindi avere un tutto uno. che nvidia abbia fatto bene lo so, ma mi chiedo se i pressi siano dovuti alle dimensioni del cip o se piuttosto ai costi di proggetazione, perché comunque li vendono più cari.
__________________
zen = multi in one |
|
|
|
|
|
19-02-2014, 17:48
|
#56 | |||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4382
|
Quote:
Non ti è venuto in mente che per avere maggiori prestazioni per core in maxwell, nvidia è dovuta rincorrere ad un numero maggiore di transistor a shader: +32% vedi gk107 vs gm107. Tutti i numeri che hai sparato sopra dicono solo che la nuova architettura usa maggiormente le risorse a disposizione, punto. Ho fatto un calcolo veloce ed è venuto fuori che a parità di transistor maxwell è più veloce del 13% nel gaming. Non è tanto, ma è pur sempre un miglioramento tangibile. Quote:
Ma è divertente il fatto che continui ad omettere la superiorià di gcn anche nei confronti di maxwell Quote:
quello che mi lascia interdetto è proprio il dimezzamento o quasi del consumo...come ha fatto nvidia a fare consumare ogni singolo transistor la metà... Tu continui a sottolineare che sta usando i 28nm HP, ma più fonti parlano di 28nm HPm...quel che è certo è che nvidia non ha smentito. Ultima modifica di tuttodigitale : 19-02-2014 alle 17:52. |
|||
|
|
|
|
19-02-2014, 17:49
|
#57 | |||||||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4382
|
Quote:
Quote:
Ho semplicemente ironizzato sul fatto, che tu sei convinto che nvidia voglia sfruttare cpu più di quanto voglia AMD la cpu l'ha progettato proprio tenendo in mente l'APU. Quote:
Quote:
E comunque HSA non serve per integrare delle unità di calcolo seriale (per quanto un sistema sulle pipeline possa essere definito tale), ma di far dialogare Compute Core di natura diversa senza nessun livello gerarchico stabilito a priori. Quote:
Anzi dagli schemi a blocchi che ho visto fino a oggi, sembrerebbe che persino xbox one abbia una gestione della memoria ereditata da Richland/kabini... Quote:
Quote:
PS mi scuso in anticipo il pessimo italiano Ultima modifica di tuttodigitale : 19-02-2014 alle 18:26. |
|||||||
|
|
|
|
19-02-2014, 18:36
|
#58 | ||||
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4187
|
Quasi ci rinuncio, tanto poco cambia tra quello che ci diciamo.
Quote:
Quote:
Infatti quello che intendevo è che non è detto che nella soluzione nvidia non vi dsia una gerarchia prestabilita per accedere ai core ARM (sempre che si possa fare "da fuori" liberamente o nvidia te lo permetta tramite i suoi driver). Quote:
Ora scopriamo che AMD è pure "inventrice" della memoria condivisa... AMD come Apple? Quote:
Per tutto il resto a cui non ho risposto alzo bandiera bianca. Ciao, e buon HSA. |
||||
|
|
|
|
19-02-2014, 18:58
|
#59 |
|
Bannato
Iscritto dal: May 2005
Città: Se ho fatto qualcosa di male... rivolgersi a FroZen!!!
Messaggi: 20102
|
spero la 265 tragga vantaggio da mantle
questa 750ti è ottima, poco rumore, poco consumo e poco calore la differenza di frames non mi fa pensare ad una differenza rilevante, dove non giochi con una - o dove giochi male -, non giochi con nemmeno con l'altra |
|
|
|
|
19-02-2014, 19:12
|
#60 | |
|
Senior Member
Iscritto dal: Jul 2003
Messaggi: 26791
|
Quote:
L'acquisto mi pare sensato, anche se personalmente risparmierei i soldi per un bel monitor 1080p e una ipotetica 860 da farsi questa estate così da essere a posto per anni pure con tutti i vari porting da xbox one e ps4 |
|
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 09:05.















