





|
|||||||


|



|
|
 |
|
|
Strumenti |
 10-07-2016, 19:16
10-07-2016, 19:16
|
#4201 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
Quasi da denuncia...(si fa per dire) cmq 3ghz di clock su design Custom 16FF+ (per ora di più nin zo Manca solo il qualcomm Hydra con il Kryo pompato. Ultima modifica di Ren : 10-07-2016 alle 19:23. |
|

|

|
10-07-2016, 19:22
|
#4202 | |||||||||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Quote:
Quote:
Quanto alle dimensioni, dovrebbe essere possibile ricavare l'area di un modulo XV e quella di un core Zen e fare le dovute proporzioni. In genere lo fanno siti come Chip Architect. Quote:
Quote:
Quote:
Preciso che, però, non so come Intel abbia implementato il tutto nei suoi processori. Quote:
Quote:
Detto in altri termini, è difficile impegnare tutte e 4 le porte FP a 128 bit allo stesso momento. Quote:
Quote:
Quote:
Quote:
La realtà è che le porte vengono selezionate dinamicamente in base al codice eseguito, e se una porta è impegnata per un'operazione, non si ferma tutta la macchina: se ne possono sfruttare altre nel frattempo. Quando sarà libera, verrà utilizzata dall'istruzione in attesa. E così via. Potenza dell'esecuzione OoO.
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
|||||||||||
|
|
|
10-07-2016, 19:26
|
#4203 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
Quote:
|
|
|
|
|
10-07-2016, 19:29
|
#4204 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
Quote:
Poi stiamo parlando dei partner di coloro che avevano detto fino al +50% di clock a parità di TDP, per i 32nm... |
|
|
|
|
10-07-2016, 19:36
|
#4205 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
Voglio vedere cammello, non numerini e buone intenzioni Su carta il TSMC16 era peggio del 14LPE. 
Ultima modifica di Ren : 10-07-2016 alle 19:41. |
|
|
|
|
10-07-2016, 19:52
|
#4206 | |||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
Quote:
Quote:
Vi presento ZEN: 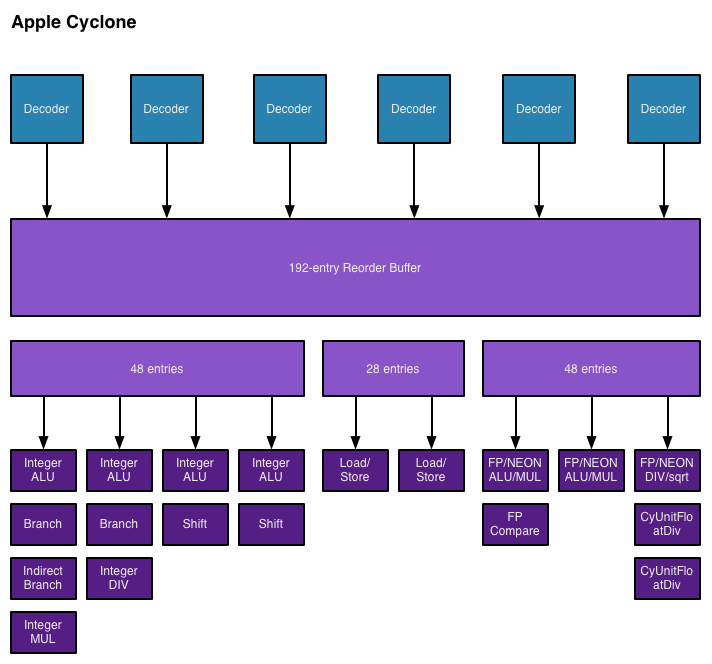 scherzo. Quote:
Ultima modifica di tuttodigitale : 10-07-2016 alle 19:56. |
|||
|
|
|
10-07-2016, 19:59
|
#4207 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
Cyclone la clonazione. Ultima modifica di Ren : 10-07-2016 alle 20:03. |
|
|
|
|
10-07-2016, 20:39
|
#4208 | ||||||||||
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Quote:
Quote:
Quote:
ALU+AGU+MEM (!!!) Infatti molte istruzioni, anche reg+mem/reg sono implementate con una MOP e sono fastpath single... I decoder AMD sono di una VIULEEEENZA impressionante... Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
||||||||||
|
|
|
10-07-2016, 20:42
|
#4209 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:

__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
10-07-2016, 21:01
|
#4210 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
Quote:
Poi che le ALU siano 4 e le AGU siano 2 lo dice la patch non dresdenboy. |
|
|
|
|
10-07-2016, 21:04
|
#4211 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:

__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
10-07-2016, 21:18
|
#4212 |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
riguardo il checkpoint. questa unità, è presente anche nelle CPU IBM: In sostanza questa unità determina se si sono verificati errori. L'unità genera ECC Quando questo si verifica, la matrice del checkpoint viene utilizzato per riavviare l'esecuzione, che quindi è in grado di risolvere problemi transitori, fino al cambio, credo inevitabile di CPU. In sostanza è un meccanismo di ridondanza orientata al mercato data-center.
|
|
|
|
11-07-2016, 10:10
|
#4213 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32182
|
Ma il 14nm FinFet Intel supporta sino a 1,35V, perché il 14nm FinFet GF dovrebbe fermarsi a 1,1V? Chiaro che non parlo di efficienza ma di OC. Se con un FO4 più basso e potrebbe arrivare >3,5GHz con, 1,1V, anche se il 14nm GF supportasse un Vcore inferiore rispetto a quello Intel, non vorrebbe dire comunque frequenze inferiori, anche perché il turbo di BD sul 28nmBulk è 4,3GHz che di fatto è +100MHz rispetto al max di Intel sul 14nm (4,2GHz 6700k)
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 |
|
|
|
12-07-2016, 00:38
|
#4214 |
|
Senior Member
Iscritto dal: Oct 2003
Città: Milano
Messaggi: 4080
|
Ultima modifica di digieffe : 12-07-2016 alle 00:51. |
|
|
|
12-07-2016, 06:02
|
#4215 | |||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Quote:
Quote:
Comunque il meccanismo delle MOP -> più uop è simile a quello che c'è nelle CPU Intel. Quote:
Tested: Why the iPad Pro really isn't as fast a laptop Quote:
Ovviamente tutto dipende molto dalla tipologia di codice eseguito. Nel caso di codice che sfrutta molto le unità FP, c'è da dire che è abbastanza lineare per cui si possono sfruttare abbastanza bene tali unità, sebbene ci siano degli ostacoli con le SSE. Il punto è che queste istruzioni usano per lo più istruzioni 2 operandi con la destinazione usata anche come sorgente (si parla di operazioni distruttive). Questo costringe a fare uso frequente di istruzioni FMOV, che dunque vanno eseguite assieme a FADD,FSUB,FMUL, ecc.. Aggiungiamoci il fatto che servono anche delle operazioni "intere" per gestire indici e/o puntatori, nonché loop, e vedi tu stesso impiegare stabilmente 4 unità FP a 128 bit sia tutt'altro che semplice. Con AVX, che supportano 3 operandi (non distruttivi) le cose si semplificano notevolmente, e col vantaggio che sono pure a 256 bit. Se passiamo al codice non FP, allora cominciano i guai, perché non è più così semplice e lineare, e diverse volte sei pure costretto a ripopolare la pipeline. Qui anche la latenza troppo elevata di certe istruzioni crea non pochi problemi, perché impegna per troppo tempo le unità d'esecuzione, e l'unità di retire è lì che aspetta bloccando risorse che devono essere liberate per altre istruzioni. Quote:
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
|||||
|
|
|
12-07-2016, 06:12
|
#4216 | |||||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Quote:
 Quote:
Quote:
Quote:
A parte questo, poi bisogna anche vedere il throughput e la latenza. Ad esempio, se vai a vedere la singola MOP di AMD per il caso ISTRUZIONE Mem,Reg oppure Mem,Imm, hai una latenza molto elevata e un throughput che si riduce a 1 (da 0.5). Esempio: 4 e 1 per la MOV, e ben 7 e 1 per la ADD. Quote:
Quote:
Quote:
Inoltre con AVX2 c'è il vantaggio che anche in single core/thread puoi spremere per benino le unità FP, lasciando pure un po' spazio all'esecuzione di istruzioni intere.
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
|||||||
|
|
|
12-07-2016, 06:42
|
#4217 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Il grafico in quel post fa ben sperare... Sempre se il FO4 di Zen non è troppo alto...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
12-07-2016, 06:55
|
#4218 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Per quanto riguarda le uops "issuabili": a quanto ho capito in AMD le AGU sono attaccate alle unità di L/S, quindi una MOP viene al più splittata in 2 pezzi: ALU e AGU+MEM. Ovviamente se il dato deve essere letto da memoria, l'operazione non può partire subito, viceversa se il dato deve essere scritto, l'operazione ALU può partire e viene ritirata quando il dato è stato calcolato e scritto... E una uop mem può anche essere Read/Modify/Write... Comunque l'alta latenza non è poi tanto disastrosa. Quello che conta è il numero di decoder occupati, perchè spesso si è limitati da questo... AMD da tempo fa il fetch di 32 bytes alla volta e INTEL fino a qualche generazioni fa era a 16. ora hanno recuperato... Quindi il collo di bottiglia era il decoding. Per INTEL non era tanto grave, perchè tanto con codice non ottimizzato, spesso non si raggiungeva il limite teorico delle 4-1-1-1 uop in decodifica, quindi i 16 bytes/ciclo non erano quasi mai un problema, ma con la uop fusion e altri miglioramenti, immagino che quella iniziava a essere una limitazione pesante... Ad ogni modo AMD con le sue MOP molto potenti, può spesso decodificare 4 istruzioni per ciclo... O anche 2, vista la genialata delle fastpath double... Invece, almeno fino a qualche generazione fa, INTEL appena incontrava una istruzione con più di 1 uop, doveva passare al microcodice, scendendo a una istruzione/ciclo in decodifica, contro le 2 di AMD...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
12-07-2016, 20:56
|
#4219 | ||||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26110
|
Quote:
Quote:
Quindi è simile ad Intel (1 fused-uop = 2 uop). Quote:
Quote:
E' soltanto AMD che ha avuto il bisogno di eseguire il fetch di 32 byte/ciclo, divisi in 16 byte/ciclo per ogni thread hardware. Quote:
fastpath double per altre istruzioni penso ci saranno anche, ma non ho nessuna tabella che le riporta, purtroppo. La stragrande maggioranza è rappresentata da quelle fastpath single, usate anche nel caso di istruzioni RMW. E' in quest'ultimo caso che c'è un vantaggio rispetto ai processori Intel, perché questi ultimi richiedono 2 fused-uop (e quindi generano 2+2 uop; mentre AMD soltanto 2), ma al prezzo di una maggiore latenza (almeno 1 ciclo di clock). Quote:
Forse ti riferivi al Pentium 4, che poteva decodificare al massimo un'istruzione per ciclo di clock, ma generava comunque da 1 a 4 uop per la maggior parte delle istruzioni, mentre quelle più complicate richiedevano più di un ciclo di clock per essere decodificate.
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
||||||
|
|
|
12-07-2016, 21:34
|
#4220 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
il fastpath double è necessario per le istruzioni splittate (128 bit su bobcat e 256 su BD/jaguar), ma è sfruttato anche per altre istruzioni più semplici, con il vantaggio di non fermare il decoder in modalità single istruction per ciclo solo per una istruzione un attimo più complessa... Anche se le fastpath single sono molto di più di quelle INTEL. E mi pare che solo di recente INTEL ha risolto il problema di uop con non più di 3 operandi (da cui il FMA3 a favore dell'FMA4 spinto da AMD che era supportato a basso livello), o forse no... Per quanto riguarda il bursti INTEL 4-1-1-1, mi ricordo che Agner Fog ha fatto delle analisi in proposito: non appena si esce fuori dallo schema 4-1-1-1, e cioè se dopo l'istruzione microcodificata con 4 uops non ci sono 3 istruzioni semplici, il sistema si "inceppa" e si procede ad al più una istruzione per ciclo (sempre se inferiori o uguali a 4 uop), fin quando non si ri-incontra di nuovo un bundle del genere, o al più un 4-1 o 4-1-1... Ovviamente sono supportati anche 3-1-1-1, 2-1-1-1 e 1-1-1-1... Per inceppato, intendo che un 4-1-4-1 è fatto in 2 cicli e non 1... Ossia i 4 decoder non sono complessi...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 22:32.















