





|
|||||||


|



|
|
 |
|
|
Strumenti |
 26-06-2025, 15:20
26-06-2025, 15:20
|
#23321 |
|
Senior Member
Iscritto dal: Mar 2008
Messaggi: 3113
|
Hai clonato il sistema? Perché l'unico modo che hai per sapere se dipende dall'ssd (a parte verificare se i parametri smart dicono qualcosa di utile) è staccare tutte le periferiche esterne, resettare il bios e installare win da 0. Se così hai problemi con il nuovo e non con il vecchio allora potrebbe dipendere dall'ssd
__________________
MB Asus Rog Maximus Z690 Apex - CPU Intel Core i9 12900k @ pcore 5.1ghz ecore 4.1ghz - RAM G.Skill Trident Z5 rgb 6600mhz 32gb - GPU RTX 5090 Phantom @ 3.1ghz - AUDIO Creative Sound BlasterX AE-5 - Creative GigaWorks S750 - SSD Western Digital Black SN8100 2tb - HD Seagate Exsos X18 16tb - Seagate IronWolf 10tb - PSU Seasonic Prime TX-1600 Noctua Edition - CASE LianLi PC-O11 Dynamic Evo rgb - MONITOR Lg 27GP950 |

|

|
|
26-06-2025, 19:26
|
#23322 |
|
Senior Member
Iscritto dal: Nov 2021
Città: Milano
Messaggi: 1376
|
Alla fine ci avevo azzeccato sull'NQ780: controller DRAM-less ma usato con HMB, cioè senza DRAM. Il controller in questione è l'inaffidabile IG5236 e come NAND flash sono usate le vecchie (e scarse al giorno d'oggi) Intel N28A QLC da 144L. C'ha una cache SLC enorme (quasi 1TB sul taglio da 4TB) ma ovviamente è necessaria per coprire le pessime performance delle NAND flash che fanno 400 MB/s.
Direi che questo NQ780 può finire nella lista degli SSD da evitare. |
|
|
|
|
26-06-2025, 20:02
|
#23323 |
|
Senior Member
Iscritto dal: Mar 2008
Messaggi: 3113
|
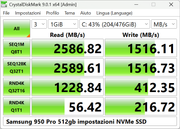
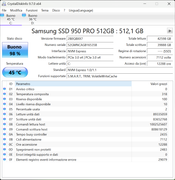
Ecco gli screen del mio 950 pro
__________________
MB Asus Rog Maximus Z690 Apex - CPU Intel Core i9 12900k @ pcore 5.1ghz ecore 4.1ghz - RAM G.Skill Trident Z5 rgb 6600mhz 32gb - GPU RTX 5090 Phantom @ 3.1ghz - AUDIO Creative Sound BlasterX AE-5 - Creative GigaWorks S750 - SSD Western Digital Black SN8100 2tb - HD Seagate Exsos X18 16tb - Seagate IronWolf 10tb - PSU Seasonic Prime TX-1600 Noctua Edition - CASE LianLi PC-O11 Dynamic Evo rgb - MONITOR Lg 27GP950 |
|
|
|
|
26-06-2025, 20:24
|
#23324 | |
|
Senior Member
Iscritto dal: Nov 2021
Città: Milano
Messaggi: 1376
|
Quote:
|
|
|
|
|

|
26-06-2025, 22:03
|
#23325 |
|
Senior Member
Iscritto dal: Mar 2008
Messaggi: 3113
|
Già!
__________________
MB Asus Rog Maximus Z690 Apex - CPU Intel Core i9 12900k @ pcore 5.1ghz ecore 4.1ghz - RAM G.Skill Trident Z5 rgb 6600mhz 32gb - GPU RTX 5090 Phantom @ 3.1ghz - AUDIO Creative Sound BlasterX AE-5 - Creative GigaWorks S750 - SSD Western Digital Black SN8100 2tb - HD Seagate Exsos X18 16tb - Seagate IronWolf 10tb - PSU Seasonic Prime TX-1600 Noctua Edition - CASE LianLi PC-O11 Dynamic Evo rgb - MONITOR Lg 27GP950 |
|
|
|
|
26-06-2025, 22:33
|
#23326 | |||
|
Senior Member
Iscritto dal: Nov 2021
Città: Milano
Messaggi: 1376
|
@Liupen è appena uscita la recensione di TweakTown sul Micron 2600, un E29T (prima volta che vediamo questo controller) con le N69R (G9), cioè 276L QLC. Trovo questo SSD più interessante da un punto di vista accademico che delle performance.
Prima di tutto, parlando dell'SSD, usa controller e NAND flash superrecenti. L'E29T sembra essere un'evoluzione dell'eccellente E27T competitor del MAP1602: penso che abbia 3 core ARM Cortex-R5 di cui due di essi CoXProcessor, ha 4 canali da 3.600 MT/s ciascuno con 16 CE totali ed è costruito su un nodo da 12 nm di TSMC. Fin qui tutto uguale all'E27T, l'unica differenza che mi sembra di vedere è un miglioramento dal punto di vista dell'affidabilità grazie all'ECC LDPC e RAID di settima generazione di Phison quando l'E27T usa un motore di quinta generazione. Parlando delle NAND flash, invece, come già detto sono delle N69R. Nel sample di TT da 2TB si ha soltanto un chip NAND flash visto che ci sono all'interno 8 die da 2Tb ciascuno, e infatti 256GB (ottenuto facendo 2.048 / 8) * 8 = 2.048GB. Abbiamo di fronte, quindi, il primo chip NAND flash con die da 2Tb. La velocità dell'I/O di queste NAND flash è di 3.600 MT/s. Vedendo la foto di TT si ottiene il codice FBGA, ossia NY376. Mettendolo nel decoder di Micron otteniamo che il S/N è MT29F16T08GQLBHL5-24QA:B. Da qui si possono scoprire tante belle informazioni tramite lo spreadsheet cinese: - "16T" = 16.384Gb, 2TB di package; - "Q" = 8 die, 4 nCE, 4 RnB e 4 I/O; - "24" = 2.400 MT/s. Strano che lo spreadsheet dica 2.400 MT/s se queste NAND flash sono listate per 3.600 MT/s, vero? In realtà ha senso come cosa: 7,2 / 0,85 = 8,47; 8,47 / 4 = 2.100 MT/s, ciò vuol dire che per raggiungere 7,2 GB/s con 4 canali ("0,85" è l'overhead) servono delle NAND flash da almeno 2.100 MT/s, non 3.600 MT/s. Oltrepassato ciò, parliamo del perché dico che questo SSD è "più interessante da un punto di vista accademico che delle performance". Micron sulla propria pagina parla di una nuova tecnologia che riguarda il 2600: adaptive write technology (AWT). Dice che Quote:
Quote:
Micron scrive: Quote:
Infine, per spiegare l'intero processo di AWT c'è la Figura 3: 1. vengono scritti i dati nella cache SLC finché non viene riempita; 2. dopo aver riempito la cache SLC si scrivono i dati nella cache TLC finché anch'essa non viene riempita; 3. una volta riempite entrambe le cache l'SSD migra i dati dalle due cache alle NAND flash QLC. Questo è il processo di folding e viene eseguito quando l'SSD si trova in uno stato di idle, anche per poco tempo; 4. completamente del folding; 5. tutti i dati delle cache sono stati trasferiti nelle NAND flash QLC e ora ci sono entrambe le cache libere. Da qui si possono riscriverle e riempirle, ovviamente con capacità ridotta dal momento che si parla di cache dinamica. Anche quest'immagine-riassunto è molto utile. Apparentemente il Micron 2600 è l'unico attuale SSD con AWT. Mi chiedo se questa tecnologia verrà installata anche su futuri SSD TLC ma penso che prima bisogni vedere come si comporta, se è effettivamente vantaggiosa o meno. Il mio parere personale è che sembra una tecnologia stupida, penso che sia molto meglio un'intera cache SLC piuttosto che metà pSLC e metà pTLC. Con metà pTLC hai letteralmente un degrado delle performance dalla pSLC e se puoi evitare questo degrado impostando la cache interamente in pSLC, che senso ha condividere metà di questa porzione in pTLC? Boh, chi lo sa, se sono arrivati ciò è perché magari è vantaggioso in termini di costi/performance. Penso che questa modalità avrebbe senso per i primi SSD da 16TB (raggiungibili grazie a questi die da 2Tb): se per qualche motivo non riesci a fare una gigantesca cache SLC per questi dispositivi allora allunghi il brodo con una cache pTLC, ma il Micron 2600 non ha capacità neanche da 8TB, figurati 16TB. Magari AWT esiste per questo e ora come ora la stanno soltanto introducendo dandoci un assaggio... In ogni caso, dobbiamo attendere recensioni più complete come quelle di Tom's Hardware per sentire la loro su AWT e vedere come si comporta questa cache pSLC e pTLC. Se pTLC è un allungamento della pSLC è vincente come tecnica, se è un taglio è soltanto un peggioramento secondo me. P.S.: mi chiedo anche perché pTLC e non pMLC. Se usciranno/troverò brevetti in futuro li leggerò e condividerò. Ultima modifica di Black (Wooden Law) : 26-06-2025 alle 22:52. |
|||
|
|
|
|
27-06-2025, 01:09
|
#23327 |
|
Senior Member
Iscritto dal: Nov 2021
Città: Milano
Messaggi: 1376
|
So che questo thread parla di SSD ma questa notizia può essere rilevante ai chip DRAM installati negli SSD: attualmente i chip DRAM DDR4 costano quanto (se non di più) quelli DDR5. Il motivo dietro a questo fenomeno è la riduzione di produzione da parte dei produttori come Micron che ha annunciato che entro fine anno vuole terminare completamente la produzione di questo tipo di memoria.
Il motivo dietro al taglio di produzione delle DDR4 è la Cina, particolarmente CXMT, un nuovo produttore che è entrato nel mercato delle DRAM a maggio 2024. Da quando è entrato nel mercato ha incominciato a vedere banchi a prezzo inferiore rispetto alla concorrenza per "rubare" del market share e gli altri produttori (SK hynix, Samsung e Micron) per impedire che succedesse ciò hanno seguito questo trend di abbassamento dei prezzi. Mentre i produttori abbassavano i prezzi delle DDR4 ne abbassavano anche la produzione visto che non facevano un gran profitto... questo tutti i produttori tranne CXMT, che ha continuato ad abbassare i prezzi aumentando sempre di più l'offerta. In quel momento (ossia fino a dicembre 2024) CXMT era l'azienda dominante nell'offerta di moduli DDR4. A dicembre 2024 succede che CXMT ha deciso di spostare il focus della produzione sulle DDR5 producendo e offrendo meno DDR4 di quanto avesse fatto prima, aumentando così i prezzi. Dal momento che per far avvenire questa transizione ci vuole un trimestre¹ i prezzi delle DDR4 hanno incominciato ad aumentare da marzo 2025, esattamente 3-4 mesi dopo dicembre. The Memory Guy (vedere nota a piè di pagina) dice che tutto questo è successo perché visto l'obbiettivo della Cina di diventare autoindipendente nel settore dei semiconduttori (Made In China 2025) ad essa non poteva mancare una fetta del mercato delle DRAM, quindi ha deciso di introdursi tramite una società sotto proprietà del governo (proprio come YMTC) che non è costretta a fare profitto ma appunto ad introdursi in questo mercato. Non a caso hanno fatto la transizione DDR4-DDR5 dopo poco che sono entranti nel mercato, se CXMT fosse stata un'azienda che avesse puntato sul profitto l'avrebbe fatto più in avanti visto che è un'operazione costosa. Concludendo, vista questa situazione direi che è probabile vedere in futuro chip DRAM DDR5 negli SSD, specialmente chip CXMT negli SSD cinesi. ¹: https://thememoryguy.com/some-clarit...4-price-surge/. |
|
|
|
|
27-06-2025, 16:58
|
#23328 | |
|
Senior Member
Iscritto dal: Jan 2018
Città: Torino
Messaggi: 535
|
Ho letto i paper e quello che mi hai scritto Black, devo dire che sul ‘On Pitch Select Gate’ l’avevamo inquadrato già bene cosa fa e che vantaggi porta alle BiCS 8.
Resta comunque dvvero impressionante come si riesca a fare delle cose…dei miglioramenti, che funzionino a livello industriale, che sono grandi pochi nanometri se non micron… Incredibile e nello stesso tempo entusiasmante per gli ingegneri che l’hanno affrontato… e risolto. Per quanto riguarda “NAND flash innovation in the AI Era”, trovo veramente una graaaande forzatura voler inserire la parola “AI” con Nand Flash. Insomma il fatto che le nand siano più dense e un poco più veloci, nulla aggiunge alle necessità dello storage cluod necessario alle AI per funzionare o alle forme di memoria HBM che sono su un pianeta diverso. Nell’AI, come detto nel paper, c’è una parte di addestramento (la banca dati, quella che può essere svolta anche offline) e la inferenza, ossia l’interfaccia, la comunicazione da e verso l’utente dell’assistente virtuale, o bot, agente (in termini un po più propri). Nell’uno e nel secondo caso, è logico che si cerchi lo storage che a parità di capienza si più perfomente e a bassa latenza; quindi la soluzione non può che ricadere su ssd con protocollo nvme. Se creare grandi ssd è una condizione in progressione (il paper dice che la densità cresce del 30% circa all’anno da quando si ha memoria delle Nand flash) allora è una forzatura dire che ci sono delle nand flash dedicate all’AI. A parte questa cosa, sembra che il modo con cui hanno realizzato un Micron G9 die più denso non aggiungendo layer più di tanto è proprio la loro versione di On Pitch Select Gate … annamo bene! (detto proprio come faceva Sora Lella). Qui si scopiazzano le soluzioni… ed ho una mezza idea che il primo sia stato comunque YMTC (che ne pensi Black?). “G9 è anche il primo nodo a introdurre la metallizzazione WL al molibdeno per una maggiore resistenza WL” Questa cosa è forse più interessante. “È stata effettuata un'attenta selezione del passo dei livelli e del rapporto ossido-nitruro per una riduzione ottimale dei costi senza compromettere affidabilità e prestazioni”. Quindi se ben afferro il concetto, sostituisce un materiale con un altro al fine di abbassare i costi di produzione. Il discorso (del paper) su scalabilità, miglioramento della latenza airgap e lettura, devo ammettere che sono difficili da capire a fondo. Si, sembra che le B68S siano a 2 decks. Riguardo FUTURE SCALING PATH, come mi dicevi, vedo anch’io uso delle tecnologie YMTC di wafer-to-wafer bonding, ma quando dice: “The wafer bonding approach (DWB = Dual Wafer Bond – one array and one CMOS wafer) decouples the array thermal processing from CMOS and is logical next step to enable I/O speeds beyond 3.6GT/s” mi sembra molto il metodo di disaccoppiamento di Kioxia (CBA). L’impressione generale che ho avuto, avevdo ora visto da vicino le BiCS 8 e le G9, è che Kioxia sia più avanti di Micron. Quote:
AWT non ne avevo ancora sentito parlare. Dalla scheda del 2600 viene definita: "soluzione di caching dinamico multilivello". Il fatto che ce ne fosse bisogno, indica che in generale gli ssd QLC sono inadatti alle grandi scritture e si deve correre ai ripari. Si..ok. Ma se l'ssd è pieno, qualsiasi cache è ininfluente. Quindi sono d'accordo con te. Mi sembra più l'ennesima forzatura di marketing per farci digerire i QLC che orma (nelle nuove 3xxL nand)) stanno soppiantando i TLC.
__________________
La verità sola, fu figliola del tempo
LEONARDO DA VINCI Ultima modifica di @Liupen : 27-06-2025 alle 17:01. |
|
|
|
|
|
27-06-2025, 19:19
|
#23329 |
|
Senior Member
Iscritto dal: Nov 2000
Città: Loud
Messaggi: 5302
|
Tra Crucial BX500, Patriot P220, PNY CS900, Silicon Power A55 in versione 1TB, quale?
__________________
On-Line by: Acer Aspire 4920+Lumia550 RN5A TIMIronX - Le mie: Trattative - Il mio: DeviantArt Freeware/Opensource - Masterizzare?: Alternative a Nero - ImgBurn Thread Ufficiale |
|
|
|
|
28-06-2025, 10:33
|
#23330 |
|
Senior Member
Iscritto dal: Jan 2005
Città: ichnusa
Messaggi: 18016
|
Io tra quelli consigliati vedo solo il silicon Power, crucial bx500 vade retro, e gli altri non li conosco proprio
Inviato dal mio 23127PN0CG utilizzando Tapatalk |
|
|
|
|
28-06-2025, 14:31
|
#23331 | |
|
Senior Member
Iscritto dal: Nov 2020
Messaggi: 1721
|
Quote:
interessante , resettare il BIOS, ma a cosa serve e ... come si fa ? |
|
|
|
|
|
28-06-2025, 15:22
|
#23332 |
|
Senior Member
Iscritto dal: Dec 2004
Città: Zena - Pegli
Messaggi: 1756
|
Con "reset del bios" penso si intenda entrare nel bios e caricare i valori di default.
Ogni bios è un po' diverso ma la possibilità c'è in tutti. Potresti anche provare ad attivare il registro di avvio, trovi la voce se apri msconfig e vai nel tab opzioni di avvio. Magari si capisce dove perde tanto tempo in fase di boot.
__________________
Intel Core i5 12500 Msi Pro Z690-P 32Gb Corsair Dominator Platinum GTX1660Super Sk Hynix P41 1Tb Crucial P5+ 1Tb Netac NV5000 2Tb AC Baydream LG 29WK500 Beelink Mini S12Pro N100 16Gb Ssd 512Gb Samsung Galaxy Tab A7 Realme XT |
|
|
|
|
28-06-2025, 16:14
|
#23333 | |
|
Senior Member
Iscritto dal: Nov 2020
Messaggi: 1721
|
Quote:
fatto ma li NON mi da nulla e dice di aprire gestione attivita ' , da li vedo i processi in avvio ma non vedo per attivare il registro di avvio .... 
|
|
|
|
|
|
28-06-2025, 16:51
|
#23334 | |
|
Senior Member
Iscritto dal: Mar 2008
Messaggi: 20537
|
Quote:
|
|
|
|
|
|
28-06-2025, 19:53
|
#23335 | |||||||
|
Senior Member
Iscritto dal: Nov 2021
Città: Milano
Messaggi: 1376
|
Quote:
Quote:
Non son sicuro che YMTC usi OPS. Purtroppo di paper in stile ISSCC/IEEE su NAND flash YMTC non ce ne sono, ci sono soltanto i datasheet a cui non ho l’accesso né per questioni economiche né per questioni di disponibilità, ma potrebbe essere che anche loro adottino OPS da un po’ di tempo sulle loro NAND flash. Quote:
 Penso che siano gli unici ad utilizzare questa WL al molibdeno. Qui leggo tanti studi interessanti sull’uso di questo materiale nelle NAND flash, devo leggermeli. Quote:
Un miglioramento nella latenza in lettura è stato ottenuto dall’utilizzo di airgap tra le BL. In realtà questi airgap non sono per nulla una nuova tecnica, vengono utilizzati dalla produzione delle NAND flash, quindi anche quelle 2D. Anzi, specialmente in quelle 2D dove il passo delle BL veniva ridotto generazione in generazione e l’interferenza delle celle aumentava sempre di più. Ho visto spesso questo “airgap” farsi chiamare “shallow trench isolation (SHI)” ma dovrebbero esser la stessa cosa cioè due componenti che prevengono un’eccessiva interferenza tra transistor creando appunto una differenza, un gap. Micron nel paper dice che la capacitanza delle BL è molto importante e che il rapporto tra BL-cap (capacità parassita delle BL) e Isense (corrente che scorre nelle BL durante una lettura) rappresenta il tempo che ci mette la BL ad assumere del potenziale. Quindi BL-cap / Isense = ritardo RC, ossia il ritardo resistenza-capacità, quanto tempo ci vuole per la BL a caricare o scaricare una tensione. A quanto pare si vuole avere sia BL-cap che Isense bassi e per ottenere ciò sono necessari degli airgap tra le BL (abbassano la capacità parassita) e aumentare il numero di WL/layer che diminuisce Isense. Altro modo per migliorare la latenza di lettura è stata letteralmente di tagliare in due le WL e farle comandare ciascuna da un set di “driver di stringhe”. Per mitigare questo dimezzamento della WL hanno aumentato il numero di sottoblocchi per ogni blocco aumentando allo stesso tempo il numero di driver di stringhe. Per ridurre ulteriormente la latenza è stata l’introduzione di scale “bidirezionali”. Dall’immagine mi sembra che le scale vengano condivise tra le mezze WL, poi non so, sono molto vaghi nella spiegazione. Comunque le scale sono le connessioni tra i CG bassi e alti ma penso che questo tu lo sappia. Con “scalabilità”, invece, cosa intendi? tutto il discorso su tecnologie future come “confined-SN”, “FeNAND”, ecc.? Quote:
Quote:
L’ho letto tutto ma è di un’incredibile noia, mi sembra che dicano le stesse cose 1.000 volte. I punti salienti, infatti, sono: - AWT può funzionare in qualsiasi modalità di NAND flash esistente: pSLC, pMLC, pTLC, pQLC e addirittura pPLC; - la cache viene determinata in base alla frequenza di accesso ai blocchi (per esempio i blocchi a cui viene effettuato l’accesso meno raramente vengono programmati in pSLC mentre l’opposto per i blocchi pPLC) che può essere il tempo che ci passa tra due operazioni consecutive, la durata di tempo tra un’operazione di scrittura e una di lettura, ecc. Per determinare la frequenza di accesso di un blocco si tiene traccia delle letture effettuate in quel blocco. Si può anche tener conto del tasso di errore delle WL e una soglia di capacità usata dall’utente dell’SSD, per esempio con una capacità di dati memorizzati minore del 25% si scrive in pSLC, tra 25% e 50% pSLC e pMLC, tra 50% e 75% pSLC, pMLC e pTLC, ecc. Può essere un mix in realtà: se per esempio l’SSD è pieno al 30% (pSLC e pMLC) ma una WL ha un determinato tasso di errore anziché programma sia in pSLC che pMLC programma solo in pMLC. C’è però da dire che la frequenza d’accesso prevale sulla capacità dei dati: non importa se l’SSD sia occupato per più del 75% e dovrebbe scrivere nelle NAND flash QLC, se l’accesso ai blocchi è nel range di pSLC i blocchi verranno scritti in pSLC. In questo caso, quindi, la soglia della capacità occupata dei dati nell’SSD attiva soltanto una modalità in più, non obbliga a far scrivere tutti i dati in entrata lì dentro; - AWT può rendere una cella pSLC in pMLC (per esempio) aggiungendole soltanto un bit anche non inerente all’altro bit mantenendo quest’ultimo intatto. Se ho quindi una cella in pSLC già programmata, le aggiungo un altro bit e diventa pMLC; - scrivendo prima in pSLC hai una migliore affidabilità grazie ad un uso ridotto dell’ECC (ci sono meno errori avendo gli stati di tensione di soglia più ampi tra di loro) e soprattutto puoi prevenire meglio la perdita dei dati. Micron, infatti, ci dice che se perdi corrente durante un’operazione di scrittura in MLC (esempio) i dati non sono persi essendo già scritti in pSLC. È un bel wall of text ma volevo essere il più chiaro possibile. Forse per la prima volta posso essere io a dire “se hai dubbi chiedi”.  Quote:
Ultima modifica di Black (Wooden Law) : 30-06-2025 alle 10:12. |
|||||||
|
|
|
|
28-06-2025, 20:41
|
#23336 | ||
|
Senior Member
Iscritto dal: Feb 2009
Città: Manchester, UK
Messaggi: 14669
|
Quote:
  Pensavo di sostituirlo con calma anche con un 7100 per rimanere sul dramless ma gli concedo di lavorare ancora un po Quote:

__________________
corsair rm1000x ☯ lancool 3 rgb ║ b650 aorus elite ax v2 ✌ 7800 icstriddi ✪ thermalright mjolnir black ♒ 48gb Vengeance 6000 ║ giga rx 9070 xt gaming oc⚡nvme 5.0 - Crucial T705 1Tb⚡4.0 - fanxiang s880 4tb ✪ wd_black SN770 2Tb sata wd sn510 4tb + sn510 2tb ⏩ yulong DaArt Aurora + hifiman ananda stealth v3 🎵 audeze maxwell ║ cooler master gp27q ☣ endorfy thock 75% + endgame xm2w 4k |
||
|
|
|
|
28-06-2025, 21:13
|
#23337 | |
|
Senior Member
Iscritto dal: Nov 2000
Città: Loud
Messaggi: 5302
|
Quote:
__________________
On-Line by: Acer Aspire 4920+Lumia550 RN5A TIMIronX - Le mie: Trattative - Il mio: DeviantArt Freeware/Opensource - Masterizzare?: Alternative a Nero - ImgBurn Thread Ufficiale |
|
|
|
|
|
28-06-2025, 21:21
|
#23338 | |||
|
Senior Member
Iscritto dal: Nov 2021
Città: Milano
Messaggi: 1376
|
Quote:
P.S.: l’SN7100 è un ottimo SSD ma penso che sia peggiori dei rivali cinesi, soprattutto dal punto di vista del prezzo. Quote:
Quote:
|
|||
|
|
|
|
30-06-2025, 16:41
|
#23339 | ||
|
Senior Member
Iscritto dal: Jan 2018
Città: Torino
Messaggi: 535
|
Quote:
Si parla di Area scaling to enable plane parallelism. Scalibilità = riduzione dell'area a parità di capacità Da cosa capisco, la G9 dice, è a 6 deck come la precedente gen, che l'architettura del buffer di pagina (PB) ha dovuto essere adattata a un passo di 6 bitline. Il concetto di BL ok, ma quì introducono un PB. Dice: è stata ottenuta una riduzione del 50% dell'area del buffer di pagina rispetto a G8. e continua dicendo: Ciò è stato possibile introducendo un processo di raddoppio del passo del metallo per il livello di interconnessione, nonché un'attenta ottimizzazione del dispositivo CMOS per mantenere le specifiche di corrente di standby nonostante la significativa riduzione del transistor del buffer di pagina sia in lunghezza che in larghezza. Nella figura poi dice di 16 BL il che mi spiazza... 16 non è divisibile per 6 quindi non ho idea del perchè e cosa siano questi numeri. Sull'airgap meno male tu hai capito, io tra testo e immagini proprio pensavo fosse altro, tipo un diverso modo di inserire le bitline. In Read latency improvement : Word-Line RC and loading, WL-RC: si riferisce all'effetto combinato della resistenza e della capacità della linea di parola, che può influire significativamente sulla velocità e sull'affidabilità delle operazioni di memoria. Il testo dice: Per un incremento più rapido del potenziale della WL durante l'operazione di lettura, la riduzione della WL-RC di metà della WL è stata comunemente applicata nei prodotti più recenti, ma nella maggior parte dei casi è accompagnata dalla duplicazione di un set di driver di stringa per pilotare ogni metà della WL in un piano. Quindi è condizione normale che nelle 3D nand le WL siano divise in due in modo da massimizzare velocità e affidabilità di lettura... e fin quì, ok. Pare anche ovvio che le linee nel CMOS (chiamiamolo genericamente) duplichino anche loro.. anche quì, ok. Poi dice: Come mitigazione, è stata applicata una maggiore condivisione dei driver aumentando il numero di sottoblocchi per blocco per ridurre il numero totale di driver per piano, ma con un aumento del carico dell'array e della corrente di funzionamento. Mitigazione...de che? Mettiamo che si riferisca alla parte CMOS più oberata di prima. Comunque per mitigare è stata applicata una maggiore condivisione, aumentando sottoblocchi dei blocchi... ma che razza di spiegazione è?! Il funzionamento è imperscrutabile (ma si parla delle parte CMOS o gestionale della Nand) e con l'effetto di aumentare del carico dell'array e della corrente di funzionamento (che sinceramente non mi sembra una miglioria o un traguardo desiderabile) boh! Continuando con l'ultimo pezzo: La scala bidirezionale (SC) ha risolto il compromesso tra latenza di lettura, energia di lettura per bit ed efficienza dell'array, mostrato in Figura 8. Ok, quindi la soluzione per ovviare a quanto detto (aumentare del carico dell'array e della corrente di funzionamento) è quello di usare per le nand una struttura SC... che non è mai stata usata da nessun altro!! MMMh...no... la usano tutti i costruttori di nand 3D da 3 generazioni di 3D nand https://semiwiki.com/events/8116-tec...18-nand-flash/ Ma allora direi che Read latency improvement : Word-Line RC and loading è tutta una panzana o per lo meno non rappresenta una novità delle G9 Quote:
__________________
La verità sola, fu figliola del tempo
LEONARDO DA VINCI |
||
|
|
|
|
30-06-2025, 19:26
|
#23340 | ||||||
|
Senior Member
Iscritto dal: Nov 2021
Città: Milano
Messaggi: 1376
|
Quote:
Quote:
Questo, quindi, penso che sia un problema da mitigare e l'hanno risolto "collegando" i due blocchi di WL tagliati tramite delle scale bidirezionali e usando soltanto un driver di stringhe per entrambi i blocchi. Quote:
Quote:
Quote:
Dalla recensione del 2600 di The SSD Review: Quote:
EDIT: anche la WL di molibdeno al posto di tungsteno non è nulla di nuovo: https://www.kioxia.com/en-jp/rd/tech...topics-71.html. Ultima modifica di Black (Wooden Law) : 01-07-2025 alle 11:08. |
||||||
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 04:19.















