





|
|||||||


|



|
|
 |
|
|
Strumenti |
 28-07-2009, 15:08
28-07-2009, 15:08
|
#11301 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|

|

|

|
28-07-2009, 15:24
|
#11302 | |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24171
|
Quote:
 bjt2 santo subito! bjt2 santo subito! Trasferirò il tuo post in prima pagina! Comunque sia alla faccia del cambiamento! Due core che si dividono cache L1 e L2 e in grado di funzionare congiuntamente o separatamente! Una domanda: Non ho ancora capito se AMD utilizzerà comunque le istruzione SSE5 oppure lasci spazio solamente alle istruzioni AVX...
__________________
AMD Ryzen 9600x|Thermalright Peerless Assassin 120 Mini W|MSI MAG B850M MORTAR WIFI|2x16GB ORICO Raceline Champion 6000MHz CL30|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Lexar EQ790 2TB (Games)|1 M.2 NVMe Silicon Power A60 2TB (Varie)|PowerColor【RX 9060 XT Hellhound Spectral White】16GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case Antec CX700|Fans By Noctua e Thermalright |
|
|
|
|
|
28-07-2009, 15:39
|
#11303 | |
|
Member
Iscritto dal: Aug 2002
Messaggi: 245
|
Quote:
Si dice che il punto debole dell'hyperthreading sia la bassa efficienza energetica (Watt/Gflop) (perrò non ho capito perché), questo approccio che sembra per molti versi opposto dici che promette, aldilà degli altri benefici, una migliore efficienza? alesc |
|
|
|
|
|
28-07-2009, 16:13
|
#11304 |
|
Senior Member
Iscritto dal: May 2009
Messaggi: 1330
|
Uhm...molto interessante l'architettura bulldozer...davvero innovativa anche!
Credo che questa architettura segnerà la ribalta per AMD...o almeno lo spero |
|
|
|
|
28-07-2009, 17:11
|
#11305 |
|
Senior Member
Iscritto dal: Jun 2009
Messaggi: 451
|
avrei una domanda ma questo bulldozer è lo stesso presentato da Ruiz o è uno diverso?Grazie.
__________________
I case e l'estetica fu vera gloria? L'unione fa la forza La vertigine non è paura di cadere, ma voglia di volare.Jovanotti 
Ultima modifica di Pentajet : 28-07-2009 alle 17:13. |
|
|
|
|
28-07-2009, 18:16
|
#11306 | |
|
Senior Member
Iscritto dal: Sep 2006
Messaggi: 1539
|
Quote:
Da un confronto fra un pentium 4(3.0ghz circa) contro un atom 330. Si è rivelato che mentre nella maggior parte dei test atom batteva il pentium 4 grazie al core supplementare durante la navigazione internet, uso di windows( file manager, documenti word etc) atom mostrava segni di debolezza mentre il pentium 4 filava liscio (lasciamo perdere i consumi). Certamente avere un doppio core aiuta quando devi fare decompressioni, enconding etc etc, ma nei programmi di tutti i giorni raramente uso più di un core solo. Neppure usare due programmi contemporaneamente la cosa si sente visto che di solito solo il programma che usi in quel momento consuma cicli cpu in quantità degna di nota. |
|
|
|
|
|
28-07-2009, 18:18
|
#11307 |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Il progetto bulldozer doveva essere presentato diverni anni fa, ma ha accumulato ritardi su ritardi.
Tornando al tema principale, pare che gli stadi della pipeline aumenteranno, come già vi ha accennato bjt2. Si parla per l'appunto di almeno due/tre stadi dovuti alla trace cache ed un nuovo stage posto prima dello scheduler che dovrebbe chiamarsi "MAP". L'attuale pipeline dei K8/10 è composta da 12-stage, invece quella dei core2/i7 da 14stage. Ovviamente mi riferisco alla pipeline per i numeri interi. Vedremo come verranno migliorate le unità di branching che purtroppo sono sempre state il tallone di achille di AMD, soprattutto dal punto di vista dello spazio occupato in relazione all'efficienza. Ultima modifica di Ren : 28-07-2009 alle 19:15. |
|
|
|
|
28-07-2009, 18:31
|
#11308 |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Vi allego una vecchia immagine del presunto bulldozer.
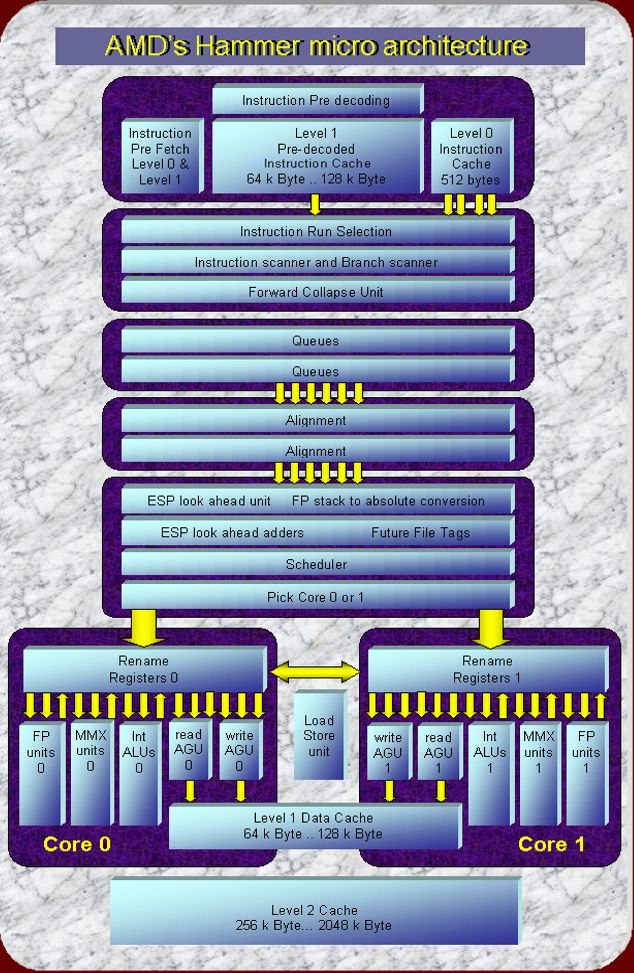 Segnalo un altro processore che utilizza un approccio simile al clustered-core. Si tratta di un prototipo quasi definitivo della Sun che purtroppo non vedrà luce. Si chiama con il nome in codice "Rock" Eccovi il link wikipedia ed un PDF. http://en.wikipedia.org/wiki/Rock_processor http://www.opensparc.net/pubs/preszo...ckHotChips.pdf |
|
|
|
|
28-07-2009, 19:12
|
#11309 |
|
Senior Member
Iscritto dal: Mar 2007
Messaggi: 985
|
Ciao a tutti, volevo chiedervi una cosa riguardo la AsRock A780GXE/128M, nel sito infatti c'è scritto AM3 CPU ready,cosa vuol dire?? Nella AsRock A780GXH/128M invece c'è scritto Support for AM3 processor.
Differenza tra AM3 ready e AM3 support
__________________
Programmare è come fare sesso, un errore e devi fornire supporto per tutta la vita |
|
|
|
|
28-07-2009, 19:12
|
#11310 | |
|
Bannato
Iscritto dal: Jun 2006
Messaggi: 1797
|
Quote:
Ultima modifica di navarre63 : 28-07-2009 alle 19:15. |
|
|
|
|
|
28-07-2009, 19:30
|
#11311 | |
|
Senior Member
Iscritto dal: Feb 2006
Città: Casale Monferrato,San Lucido,Gignod
Messaggi: 10932
|
Quote:
non dovrebbe essere un esacore?
__________________
ASRock 939 Dual-SATA2 + AM2 Board + Athlon X2 5000+ @3000, ATI 5770, PSU SilentMaxx 400W |
|
|
|
|
|
28-07-2009, 19:37
|
#11312 | ||||
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24171
|
Quote:
A quanto pare AMD ha cancellato o meglio ha evoluto il progetto Bulldozer del 2007: Da un Quad core a 45nm con SSE5 a un Octa core a 32nm con AVX... Inoltre Bulldozer sarà anche FUSION con il core Llano... Quote:
Quote:
Quote:
Supporto alle CPU AM3...
__________________
AMD Ryzen 9600x|Thermalright Peerless Assassin 120 Mini W|MSI MAG B850M MORTAR WIFI|2x16GB ORICO Raceline Champion 6000MHz CL30|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Lexar EQ790 2TB (Games)|1 M.2 NVMe Silicon Power A60 2TB (Varie)|PowerColor【RX 9060 XT Hellhound Spectral White】16GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case Antec CX700|Fans By Noctua e Thermalright |
||||
|
|
|
|
28-07-2009, 19:45
|
#11313 | |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24171
|
Quote:
La domanda più succosa è: Questi due core con L1 e L2 condivisi viene contata come due core oppure come se fosse uno? mi spiego: Un quad core Bulldozer potrebbe avere 8 core distinti?
__________________
AMD Ryzen 9600x|Thermalright Peerless Assassin 120 Mini W|MSI MAG B850M MORTAR WIFI|2x16GB ORICO Raceline Champion 6000MHz CL30|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Lexar EQ790 2TB (Games)|1 M.2 NVMe Silicon Power A60 2TB (Varie)|PowerColor【RX 9060 XT Hellhound Spectral White】16GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case Antec CX700|Fans By Noctua e Thermalright |
|
|
|
|
|
28-07-2009, 19:48
|
#11314 | |
|
Senior Member
Iscritto dal: Feb 2006
Città: Casale Monferrato,San Lucido,Gignod
Messaggi: 10932
|
Quote:
__________________
ASRock 939 Dual-SATA2 + AM2 Board + Athlon X2 5000+ @3000, ATI 5770, PSU SilentMaxx 400W |
|
|
|
|
|
28-07-2009, 19:59
|
#11315 | |
|
Senior Member
Iscritto dal: Dec 2000
Città: Parma
Messaggi: 3121
|
Quote:
L'innovazione è portare una (probabilmente piccola) cache L1 dati all'interno delle singole unità di esecuzione (che già ora sono 2 intere + una fp se non erro). L'impressione è che alla fine le 2 unità potranno lavorare su thread diversi realizzando sostanzialmente un HT e alla bisogna l'unità fp potrà usare entrambe le L1. Probabilmente le perplessità di bjt2 circa la scarsa capacità di alimentare le unità di esecuzione dei phenom sono vere. |
|
|
|
|
|
28-07-2009, 20:04
|
#11316 | ||
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24171
|
Quote:
Quote:
__________________
AMD Ryzen 9600x|Thermalright Peerless Assassin 120 Mini W|MSI MAG B850M MORTAR WIFI|2x16GB ORICO Raceline Champion 6000MHz CL30|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Lexar EQ790 2TB (Games)|1 M.2 NVMe Silicon Power A60 2TB (Varie)|PowerColor【RX 9060 XT Hellhound Spectral White】16GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case Antec CX700|Fans By Noctua e Thermalright |
||
|
|
|
|
28-07-2009, 20:18
|
#11317 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
L'immagine che ho postato proviene da un prototipo amd di vecchia data. (mi pare provenga da un brevetto).
Quote:
Il concetto dovrebbe essere l'inverso del SMT, cioè da un thread ne derivi due più semplici da gestire all'interno dallo scheduler/register renaming. Ultima modifica di Ren : 28-07-2009 alle 20:21. |
|
|
|
|
|
28-07-2009, 20:22
|
#11318 | |
|
Senior Member
Iscritto dal: Oct 2001
Messaggi: 14739
|
Quote:
O sbaglio? |
|
|
|
|
|
28-07-2009, 22:12
|
#11319 | |
|
Senior Member
Iscritto dal: Dec 2000
Città: Parma
Messaggi: 3121
|
Quote:
Per quanto riguarda il reverse hypertreading non credo che sia possibile o realizzabile: un compito seriale è seriale e non parallelizzabile. Più che altro si vede che l'unità fp accede ad entrambe le cache e quindi avrà una banda doppia e la possibilità di lavorare su insiemi di dati più grandi senza un cache miss. Ultima modifica di greeneye : 28-07-2009 alle 22:17. |
|
|
|
|
|
28-07-2009, 22:21
|
#11320 | |
|
Senior Member
Iscritto dal: Dec 2000
Città: Parma
Messaggi: 3121
|
Quote:
L'impressione che il phenom renda poco, o meglio molto meno, di quanto dovrebbe io la ho da tempo. La stessa intel all'uscita era sorpresa di quanto andasse il k10. Probabilmente le unità di esecuzione passano gran parte del loro tempo a girarsi i pollici. |
|
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 19:44.















