





|
|||||||


|



|
|
 |
|
|
Strumenti |
 13-01-2026, 21:12
13-01-2026, 21:12
|
#301 | |
|
Moderatore
Iscritto dal: Mar 2007
Messaggi: 22741
|
Quote:
Ti faccio un esempio. Se creassimo zen5 con 12 core e 48mb l3, saremmo a circa 100mm2, quindi in un 70mm2, ti servirebbe una densità del 40% in più ma, c'è un ma, buona parte dei transistor verrà speso pure per IPC. Zen5 per aumentare l'IPC ha speso quasi il 30% di transistor, di conseguenza, applicando una quota di transistor per IPC equivalente su zen6, avremmo circa un 70% tra core e cache, e tutti quei transistor dovranno stare su un 70-80mm2 (più verso la prima). Già tra i 7nm ed i primi 5nm di zen4 a celle mod, abbiamo visto quasi il 60% in più a pari core.
__________________
Ryzen 5800x3D - Msi B450TH - Corsair 32gb 3600 lpx - Red Devil RX 9070XT - samsung 860 pro 1tb - 4tb storage - Acer g-sync xb270hu - AOC CU34G2XPD - MSI MPG A850G atx3.0 - FTTH tim 2,5 gbps. |
|

|

|

|
13-01-2026, 22:16
|
#302 | |||
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32077
|
Quote:
Quote:
Se il chiplet è X8 = L3 chiplet 32MB (4MB/core * 8 core) ed L3 3D (8MB/core * 8 core) = 64MB, per avere 96MB (12MB/core * 8 core) Se il chiplet è X12, = L3 on die 48MB + 96MB impilata = 144MB Se il chiplet è X16 = L3 on die 64MB + 128MB impilata = 192MB totale. Quote:
Ma questo inquadrando il limite di uno stack (o come si chiama). Ma era stato detto che nel tempo si potevano avere fino a 3 layer aggiuntivi. Ora... se lo si applicasse ad un Zen5, vorrebbe dire 64MB x 3 = 192MB al posto di 64MB. Ed è questo il punto... anzichè realizzare un chiplet con X12 + L3 48MB, allora tantovarrebbe realizzare un chiplet senza L3 e demandare l'intera L3 impilata... ed utilizzare l'area del chiplet che altrimenti sarebbe destinata alla L3, sostituendola con dei core. Cioè, brevemente, se l'area del chiplet fosse 3/4 per i core e 1/4 per la L3 (mettendo valori a caso), impilando totalmente TUTTA la L3, si potrebbe, a pari area/costo, aumentare di 1/4 il core-count ed impilare con 1 stack la L3 che altrimenti sarebbe sul die (4MB/core) e, con 3 stack, si impilerebbero gli altri 8MB/core che sarebbe l'equivalente della L3 3D attuale. Un 2 anni fa, forse 3, quando si parlò di impilazione, si disse che al momento era prevista per la L3 ed a 1 livello, ma che sarebbe stato possibile implementare questa tecnologia non solamente per la L3 ma anche per CCX e quant'altro, e che si poteva arrivare a 3 livelli. Considerando che la L3 impilata è su un PP più economico e che il costo dell'N2P a wafer è alto, spostare tutta la L3 con l'impoilazione liberando così il chiplet e aumentare il core-count (facendo così anche scendere il costo a core), non sarebbe un vantaggio da poco.
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 14-01-2026 alle 03:43. |
|||
|
|
|
|
14-01-2026, 03:51
|
#303 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32077
|
@Mikael84
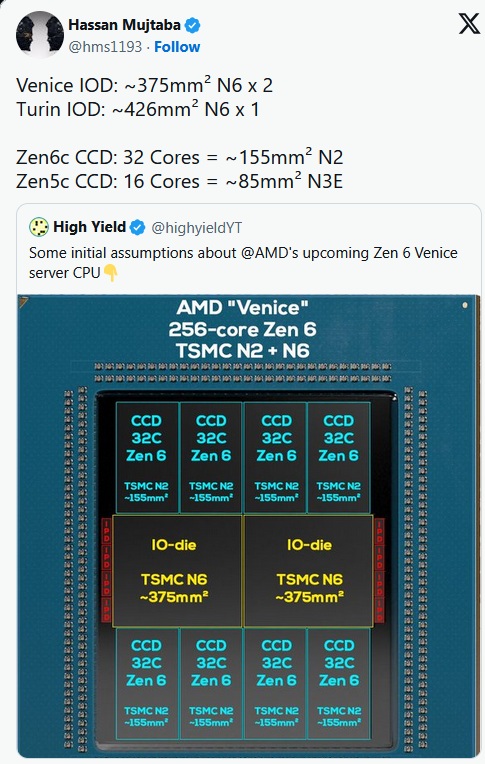 https://wccftech.com/amd-epyc-venice...-dual-io-dies/ CCD Zen5C X16 N3E 85mm2 --> CCD Zen6C X32 N2 (N2P risulterebbe da altre fonti) 155mm2 Allora, allacciandomi al post precedente: CCD Zen6C X32 = 155mm2 Considerando che la versione C è del 40% più densa del "liscio", un CCD Zen6 X32 sarebbe CCD Zen6C X32 = 155 mm² → versione normale Zen6 ≈258 mm² CCD Zen6 normale X16 e X12 (lineare per core+cache) X16 = 16/32 × 258 ≈ 129 mm² X12 = 12/32 × 258 ≈ 97 mm² Considerando il rapporto L3 vs Core come con Zen5 (22,4% del die, come hai postato te nel TH Zen5) Zen6 X33 258mm2, area L3 = 57,8 mm² CCD Zen6 X32 senza L3 = 200,2 mm² CCD Zen6 X16 senza L3 = 100,1 mm² CCD Zen6 X12 senza L3 = 75,0 mm² Diciamo che AMD se volesse far stare tra 70 e 80mm2 un CCD X6, dovrebbe essere X12 ma senza L3, cioè 76mm2 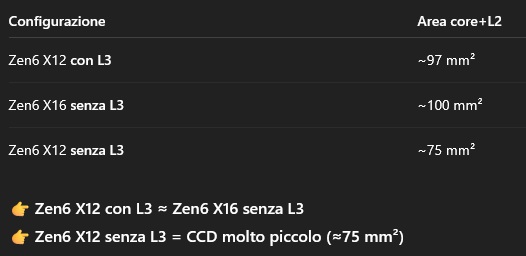 Poi c'è un altro punto... la resa attuale dell'N2P Zen6C è la versione densa di Zen6, si presume con lo stesso rapporto (-40%) dei precedenti Zen4C vs Zen4 e Zen5C vs Zen5. Quindi un chiplet X32 Zen6C di 155mm2 in realtà corrisponderebbe a un chiplet di 258mm2 (per numero di transistor) se fosse Zen6 (tra l'altro è un calcolo pessimistico, perchè Zen6C ha meno L3 di Zen6, e casisticamente, il transistor difettoso è più "facile" nelle parti logiche rispetto alla L3). Ora... per un chiplet del genere, la resa dell'N2P dovrebbe essere almeno dell'81% per essere commerciabile, non stiamo parlando di un PP acerbo, ma di un PP ma di un PP già in produzione stabile, con difetti/cm² compatibili con chiplet ad alta densità. Ed è questo il punto... considerando il chiplet Zen6 X12 desktop/Threadripper/Epyc, con le opportune proporzioni di area (97mm2 un chiplet Zen6 X12 con 48MB di L3), la resa aumenterebbe al 91% (< transisator a die, > resa). Visto che AMD parla di sistemi AI basati su Epyc X256 Zen6C entro il 1° semestre 2026 (entro 5 mesi), è ovvio arrivare alla conclusione che un chiplet Zen6 X12, sempre sull'N2P, possa avere una resa accettabile anche ora. E poi c'è un altro dubbio... Intel, ad esempio con il 18A, per aumentare la resa parte con la produzione in volumi di Panther, un die relativamente piccolo, aspettando un aumento della resa (più infornate = > resa) per poi passare a Nova e successivamente a Xeon. A confronto, AMD, per l'N2P, starebbe partendo da Xeon (per giunta pure la versione densa), il peggio per la resa. A che pro?
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 15-01-2026 alle 20:43. |
|
|
|
|
14-01-2026, 13:37
|
#304 | |
|
Moderatore
Iscritto dal: Mar 2007
Messaggi: 22741
|
Per fare una stima più accurata, servirebbero i transistor di zen6 C, non solo il die, perchè quei core, sono molto più densi di transistor.
Ad oggi non conosciamo neppure quelli di zen5C ma, potremmo provare a calcolarli. Zen5 ha il 27% di transistor in più rispetto a zen4, quindi se proviamo ad applicare lo stesso quantitativo, vengono fuori 11,5mtransistor circa, e torniamo vicini al 40% tra liscio e base. 11500mt, su un 85mm2, sono appena 135mt x mm2, ma come abbiamo visto pure per intel, questi 3nm sono pessimi lato densità. Come detto nel post precedente, avendo i dati di zen5, possiamo stimare che zen5 con 12 core e 48mb sarebbe da 100mm2, no l3 verrebbe circa 85, a questo però bisogna sapere quanti saranno i transistor per IPC e clock e. Ipotizzando il 70% tra IPC (30%) e core count/cache dovremmo toccare il 70% di transistor, quindi circa 14200. Ecco, se avessimo avuto i transistor insieme al die di zen6c (questo fa tutta la differenza), potevamo capire la densità dei 2nP applicati al circuito, e da li, calcolarci realmente i possibili die, che per limiti d packaging non possono certo essere >100mm2. Quote:
La CPU più economica, una X8 (x6 non penso lo facciano, salvo più avanti, sarebbe un x4 attuale), avrebbe costi ben più alti di un 9800x3d, tra l'altro vincolato sempre alla tensione della 3dcache, e latenze un pò più alte di base, oltre che al clock.
__________________
Ryzen 5800x3D - Msi B450TH - Corsair 32gb 3600 lpx - Red Devil RX 9070XT - samsung 860 pro 1tb - 4tb storage - Acer g-sync xb270hu - AOC CU34G2XPD - MSI MPG A850G atx3.0 - FTTH tim 2,5 gbps. Ultima modifica di mikael84 : 14-01-2026 alle 13:47. |
|
|
|
|
|
16-01-2026, 01:25
|
#305 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32077
|
After Stacked L3, AMD Is Now Exploring Ways To Stack Even The L2 Cache On Its Future Chips With Better Latency Than Traditional Designs
Da latenza 14 su 2D, si passa a 12 su 3D 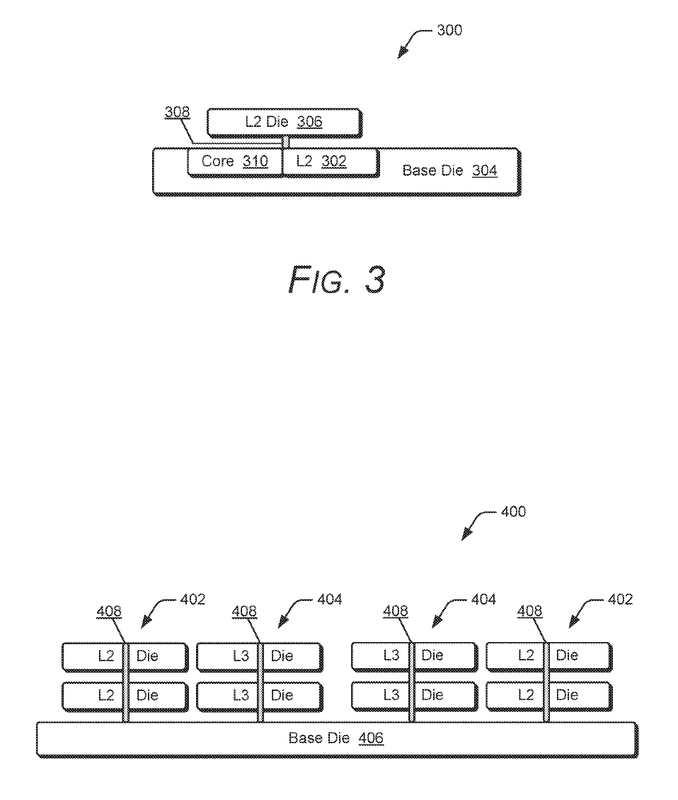 Image Source: AMD Patent Qui il link al brevetto  https://patents.google.com/patent/US...S20260003794A1
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 16-01-2026 alle 01:33. |
|
|
|
|
16-01-2026, 11:13
|
#306 |
|
Member
Iscritto dal: Oct 2025
Messaggi: 139
|
Mi domando come faranno queste CPU a prendere il volo visto il ramageddon.
|
|
|
|
|
16-01-2026, 11:29
|
#307 | |
|
Senior Member
Iscritto dal: Sep 2003
Città: Torino
Messaggi: 21681
|
Quote:
|
|
|
|
|
|
16-01-2026, 15:28
|
#308 | |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32077
|
Perchè?
Non è un concetto per diminuire il core-count, ma per ottimizzare il PP più spinto (e costoso) per sfruttare al massimo il limite attuale del silicio a 360°. Una CPU attuale vede in primis un limite di progetto (area, costi, PPT) verso il core-count ed ancor più se vista come APU (la dimensione iGPU). Realizzare un X16/32TH + una iGPU da 40CU sull'N4P ha dell'incredibile... ma se la stessa fosse realizzata eliminando la L2 ed L3 dall'area silicio die impilandola, si avrebbe un plus di area compresa una diminuzione dei costi... quindi un aumento dell'IPC da progetto (considerando il limite IPC (aumento delle ALU) un limite rapportato all'area/core-count)), un aumento del core-count o un aumento dei CU lato iGPU, o ambedue, oltre al fatto che aumentare la dimensione delle cache è l'unico mezzo oggi possibile per ovviare alle latenze/banda/costi della DDR5. Facendo un esempio... un X16/32TH + iGPU su N4P vedrebbe un aumento architetturale con il passaggio sull'N2P (IPC, core-count, iGPU). Mettiamo dei numeri a caso..., se il passaggio dall'N4P all'N2P comporta un aumento del 30% della densità transistor e l'impilazione L2/L3 un aumento del numero dei transistor del 50%, concettualmente sarebbe possibile anche pareggiare l'aumento d'efficienza del nodo più spinto aumentando il core-count. Esempio... X16 N4P = stessa efficienza di un X12 N2P (prestazione MT = frequenza core * n core... X12 N2P = frequenze più alte per pareggiare prestazionalmente un X16 N4P, > efficienza N2P vs N4P persa). AMD, secondo me, non sta finalizzando per ottenere prestazioni maggiori, ma per ottenere un target di prestazione con il minor costo produzione possibile. Se da un X16/32TH + 40CU sull'N4P si potrebbe avere un X16/32TH + 60CU sull'N2P ed un X16/32TH + 80CU sul 16A, riuscire ad offrire un X16/32TH + 60CU sull'N4P e/o un X16/32TH + 80CU sull'N2P al posto del 16A, rappresenterebbe un vantaggio enorme, semplicemente perchè abbatterebbe i costi, e di qui un listino con ampio margine vs concorrenza che risica. https://www.neowin.net/news/amds-new...ul-and-faster/ Il nuovo brevetto di AMD suggerisce che le CPU V-cache Ryzen 3D potrebbero diventare molto più potenti e veloci Quote:
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 16-01-2026 alle 15:43. |
|
|
|
|
|
16-01-2026, 19:15
|
#309 |
|
Senior Member
Iscritto dal: Jul 2001
Città: Napoli-Hellas
Messaggi: 606
|
Il brevetto US20260003794A1 di Advanced Micro Devices Inc descrive unarchitettura di stacked cache progettata per eliminare laumento di latenza tipico delle cache di grandi dimensioni. Lidea chiave è posizionare la logica di controllo e i tag al centro del sistema, con connessioni verticali (TSV o BPV) anchesse centrate. In questo modo le distanze fisiche verso tutte le porzioni della cache risultano simmetriche, garantendo latenze bilanciate. A differenza delle cache planari tradizionali, non sono necessari stadi di pipeline aggiuntivi per raggiungere le aree più lontane. Il risultato è che una cache più grande può offrire la stessa o addirittura una minore latenza rispetto a una più piccola. Il brevetto si applica non solo alla L3, ma esplicitamente anche alla L2, oltre che a SRAM o DRAM impilate. Un aspetto rilevante è che il tag lookup avviene prima dellaccesso verticale, riducendo consumi e tempi di attivazione. In prospettiva, questa soluzione apre la strada a L2 stackate per core senza penalità di latenza, con benefici evidenti in termini di performance per watt e scalabilità futura.
__________________
MacBook Air M1 - MacMini M4 |
|
|
|
|
17-01-2026, 01:11
|
#310 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32077
|
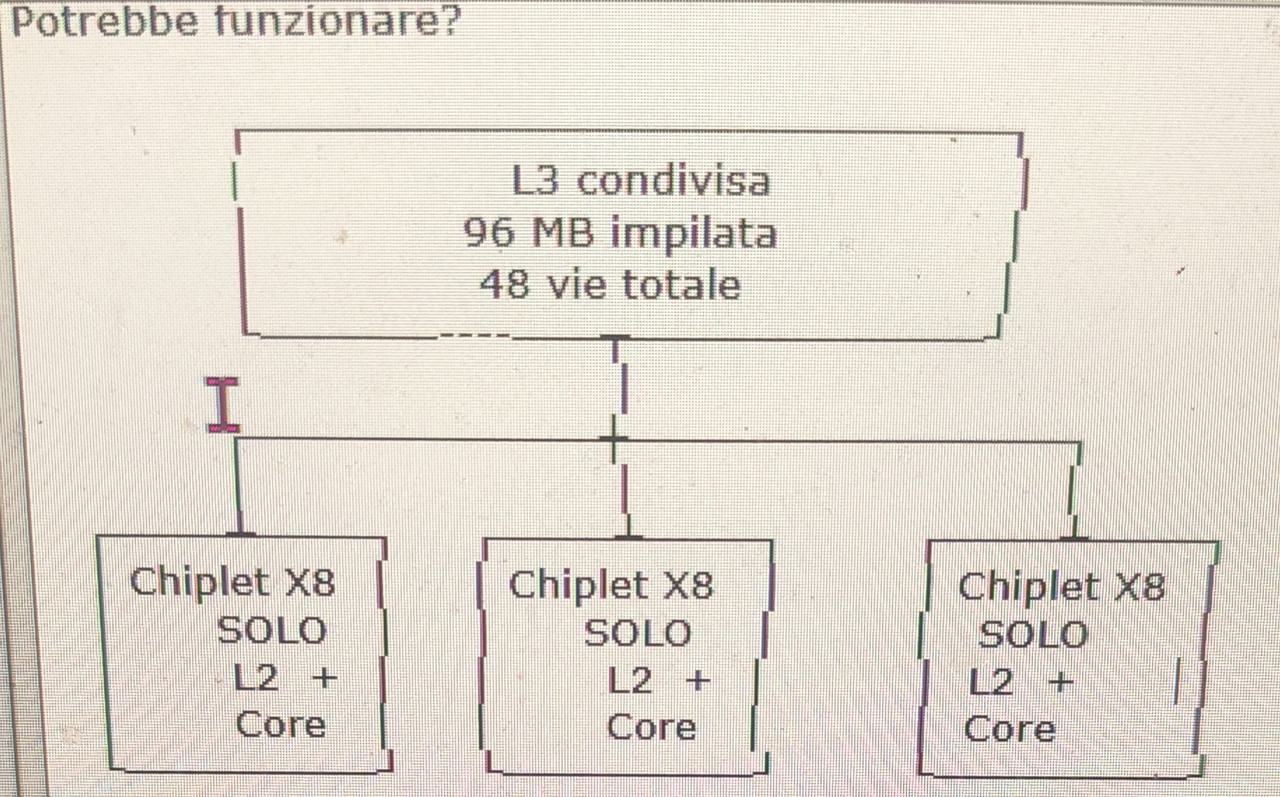 Ogni chiplet X8 ha solo L2 + core, nessuna L3 fisica. L3 condivisa impilata 3D fuori dai chiplet (32MB * 3) → 96 MB, 48 vie. Accesso dinamico: Se solo 1 chiplet è sotto carico (es. gioco), quel chiplet vede tutta la L3 da 96 MB, come se avesse un vero 3D stack. Se più chiplet lavorano, la L3 viene condivisa e gestita dal controller (48 vie). Risultato: effetto “3D” per un chiplet sotto carico senza avere L3 impilata su un chiplet (esempio 9950X3D) ------------------------- https://www.tomshardware.com/tech-in...ving-next-year 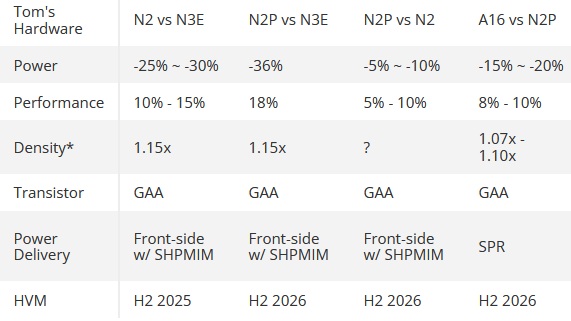 Parametrizzando con l'N4P (ChatGPT) 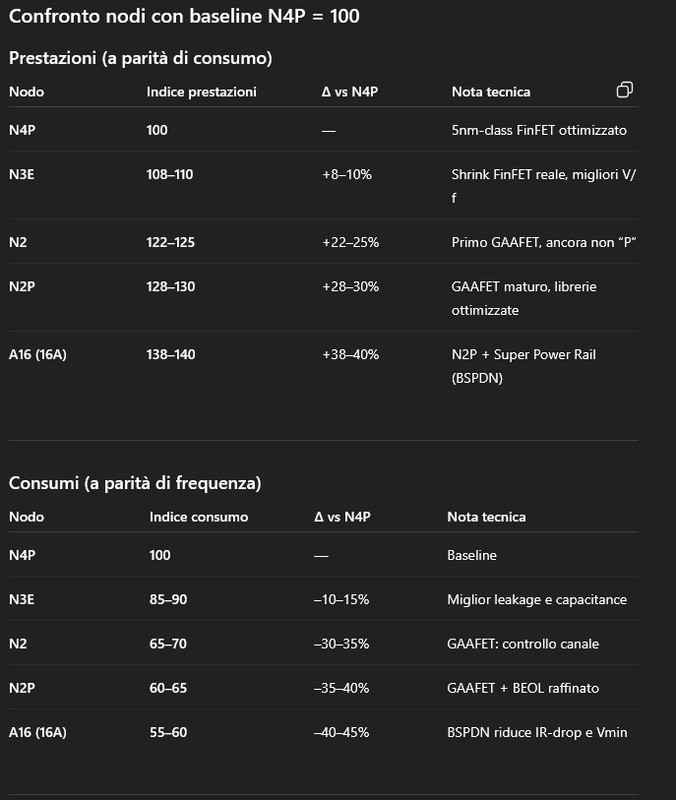 Applicazione diretta al 9950X N4P 230W (170W TDP) con X prestazioni MT N3E 230W → 9950X N4P a ~250W N2P 230W → 9950X N4P a ~297W A16 230W → 9950X N4P a ~317–324W -------------------- Core-count X16 → X24 = +50% core Scaling reale MT a TDP fisso: ~+30% Nodo (N4P → N2P / A16) Efficienza: +30–40% Impatto MT @ TDP fisso: ~+30–35% IPC Zen 6 (stime diffuse) +10–12% Totale +90–97% teorico massimo fattori reali di perdita: IF / memory scheduling thermal density non-linear MT scaling Riduzione prudente: –20–25% = +65%/+77% Il +70% dichiarato da AMD non è marketing: deriva dalla combinazione di X8→X12 (+30% MT @ TDP fisso), nodo N2P/A16 (+30–35% efficienza) e IPC Zen 6 (~+10%). A parità di consumo, un Zen 6 X24 equivale a un 9950X che dovrebbe spingersi verso 390 W.
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 17-01-2026 alle 18:59. |
|
|
|
|
19-01-2026, 14:46
|
#311 |
|
Senior Member
Iscritto dal: Sep 2003
Città: Torino
Messaggi: 21681
|
|
|
|
|
|
19-01-2026, 21:04
|
#312 |
|
Senior Member
Iscritto dal: Jul 2001
Città: Napoli-Hellas
Messaggi: 606
|
Si può immaginare un design in cui ogni chiplet X8 contiene solo core + L2 (nessuna L3 locale) e la cache di ultimo livello viene spostata in un die dedicato impilato 3D e condiviso, per esempio 96 MB totali (32 MB × 3) con 48 vie: in pratica non sarebbe più una L3 Zen classica per-CCD, ma una LLC esterna che assomiglia a una L4, quindi molto capiente ma inevitabilmente più vincolata da latenza e banda perché laccesso avviene via fabric/die-to-die. Un controller centrale potrebbe gestire la condivisione con politiche di QoS e partizionamento delle vie/slice, così che quando un solo chiplet è realmente sotto carico gli altri non sporchino la cache e quel chiplet possa beneficiare della massima capacità disponibile; tuttavia questo non replica automaticamente leffetto X3D attuale, perché la V-Cache funziona soprattutto grazie alla località (latenza/banda) della cache impilata direttamente sopra il CCD. Il vantaggio plausibile di una cache condivisa impilata sarebbe quindi più sistemico (ridurre miss in DRAM e traffico memoria su working set grandi, migliorare alcuni carichi misti) che non un equivalente 1:1 della V-Cache per gaming, mentre i punti critici sarebbero la coerenza (directory/snoop filtering), leventuale hotspot sul controller e lo scaling non lineare quando più CCD competono per gli stessi link. In sintesi: architettura credibile come shared stacked LLC/L4 con QoS dinamico, ma da presentare come strada diversa dalla V-Cache locale, non come sostituzione diretta.
__________________
MacBook Air M1 - MacMini M4 |
|
|
|
|
26-01-2026, 02:35
|
#313 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32077
|
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 |
|
|
|


|
26-01-2026, 08:59
|
#314 | |
|
Member
Iscritto dal: Oct 2025
Messaggi: 139
|
Quote:
dovremo cambiare mobo? |
|
|
|
|
|
26-01-2026, 09:56
|
#315 |
|
Senior Member
Iscritto dal: Jan 2023
Messaggi: 601
|
Amd :
Stessa ram= stesso socket Intel: Lo sapete....
__________________
9950X3D MSI MAG B850 Tomahawk Max WIFI G.SKILL Trident Z5 6400@cl30
*** Sapphire PULSE 7800 XT su MSI MAG274QRF-QD & LG B4 83" OLED *** |
|
|
|
|
26-01-2026, 10:27
|
#316 | |
|
Senior Member
Iscritto dal: Sep 2008
Messaggi: 14418
|
Quote:
La piattaforma rimane quella, unico dato sicuro, quindi puoi montarli anche sulle 600.
__________________
🖥️ Ryzen 7700 @PBO -30 CO | ❄️ Assassin III | 🛠️ TUF B650-Plus WiFi | 🔥 T-Force Delta RGB 32GB @6200MHz C30 | 🎮 Manli RTX 3060 Ti @17Gbps | 💾 Samsung 990 Pro 2TB - Crucial MX500 500GB |⚡ EVGA SuperNova G2 750W | 🏠 NZXT H510 Elite | 📺 Gigabyte G34WQC | 🎮 Legion GO 🖥️ i7 3930K @4.2GHz | ❄️IFX-14 | 🛠️Asus RE IV x79 | 🔥G.Skill 16GB @2133MHz C10 | 🎮Giga XG GTX 980 Ti | 🏠CM Storm Stryker | W11 |
|
|
|
|
|
26-01-2026, 11:16
|
#317 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32077
|
Epyc Venice è dato per supporto DDR5 8000.
Gli OEM riportano mobo AM5 con QDIMM 10.000+ I rumor riportano che nel desktop sono previsti 2 MC... per cosa al momento non si sa. Ovviamente c'è l'NDA, ma se aumenti il core-count del 50%, incrementi l'IPC, N2P con frequenze superiori... è palese che quel +70% che AMD ufficialmente riporta di incremento (tra core-count, frequenze ed IPC), debba essere alimentato... d'altronde l'IOD (MC e IF) passa da N6 a N3P, è palese che con l'NDA non ci sia nulla di ufficiale, ma viene da sè che non fai 3 salti nodo sull'IOD per lasciare IF ed MC uguale o poco di più.
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 26-01-2026 alle 11:32. |
|
|
|
|
26-01-2026, 11:36
|
#318 |
|
Senior Member
Iscritto dal: Sep 2003
Città: Torino
Messaggi: 21681
|
con intel così indietro e questi prezzi ram, fossi in amd rimanderei zen6 al 2027
|
|
|
|
|
26-01-2026, 11:50
|
#319 | |
|
Senior Member
Iscritto dal: Sep 2008
Messaggi: 14418
|
Quote:
Le varianti lisce penso che nei nostri mercati se ne parla sempre verso ottobre, e si spera si assesti l'attuale situazione delle RAM, altrimenti sarà comunque complicato fare nuove build. Intel sta spingendo moltissimo nel mobile, sta dando molta priorità a quel settore, però vedremo per nova a fine anno cosa ne esce...
__________________
🖥️ Ryzen 7700 @PBO -30 CO | ❄️ Assassin III | 🛠️ TUF B650-Plus WiFi | 🔥 T-Force Delta RGB 32GB @6200MHz C30 | 🎮 Manli RTX 3060 Ti @17Gbps | 💾 Samsung 990 Pro 2TB - Crucial MX500 500GB |⚡ EVGA SuperNova G2 750W | 🏠 NZXT H510 Elite | 📺 Gigabyte G34WQC | 🎮 Legion GO 🖥️ i7 3930K @4.2GHz | ❄️IFX-14 | 🛠️Asus RE IV x79 | 🔥G.Skill 16GB @2133MHz C10 | 🎮Giga XG GTX 980 Ti | 🏠CM Storm Stryker | W11 |
|
|
|
|
|
26-01-2026, 11:55
|
#320 | |||
|
Member
Iscritto dal: Oct 2025
Messaggi: 139
|
Quote:
Quote:
Quote:
ma chi di noi comprerebbe un ipotetico 24core X3D mettendo le vecchie 6000mt/s magari limitato pure all'IF 2000MHz? non credo che le attuali mobo possano spingersi su questi valori anche con Zen6, o mi sbaglio? è vero che alla fine l'IMC è sulla CPU, ma quanto influisce la mobo sulla frequenza/latenza delle memorie e sull'IF? |
|||
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 01:05.















