





|
|||||||


|



|
|
 |
|
|
Strumenti |
 30-09-2009, 21:46
30-09-2009, 21:46
|
#5861 | |
|
Senior Member
Iscritto dal: Aug 2005
Messaggi: 2052
|
Quote:
|
|

|
|
30-09-2009, 21:46
|
#5862 |
|
Senior Member
Iscritto dal: Feb 2000
Messaggi: 11319
|
Dal silenzio di nVidia mi sa tanto che sto chippone lo vedremo tra un bel pò, probabilmente devono calibrarlo in qualche modo per pareggiare (perchè può essere) o superare Cypress, una nVidia così silenziosa non l'avevo mai vista
__________________
PC 1 : |NZXT 510i|MSI PRO Z690 A|I5 [email protected] Ghz (Pcore) 4.5 Ghz (Ecore)|AIO ENDORFY NAVI F280|32 GB BALLISTIX 3600 cl 14 g1|GIGABYTE 4070 SUPER AERO OC|RM850X|850 EVO 250|860 EVO 1TB|NVMe XPG-1TB||LG OLED C1 - 55 | PC 2 : |Itek Vertibra Q210|MSI PRO B660M-A|I5 12500|32 GB KINGSTON RENEGADE 3600|ARC A770 LE 16 Gb|MWE 750w| ARC 770 LE 16 Gb Vs RTX 3070 - CLICCA QUI |
|
|
|
30-09-2009, 21:48
|
#5863 |
|
Senior Member
Iscritto dal: Apr 2003
Messaggi: 16462
|
Se Maometto non viene alla montagna, portiamo la montagna da Maometto.
E cio' che mi viene in mente leggendo le ultime notizie sulla nuova architettura Nvidia. Nvidia delle tre aziende che operano nel campo grafico (le altre due sono AMD che ha acquistato ATI, ed Intel che bene o male fornisce le sue gpu integrate) e' l'unica a non avere una licenza x86. E questo a lungo andare le sarebbe stato fatale. L'ironia della sorte e' che Intel cerca tramite Larrabee di avvicinare le tecniche tradizionali di cpu nel campo gpu, Nvidia con questa nuova architettura invece ha fatto l'opposto. Sta cercando di rendere la gpu molto piu' simile ad una cpu, ed in questo superano il problema di non avere alcuna licenza x86. E una grossa scomessa, ma che ha senso in ambito "professionale" non certo in ambito consumer. Vedremo come si evolvera' la situazione, ma un bestione del genere non lo vedo competitivo per niente in ambito consumer.
__________________
MICROSOFT : Violating your privacy is our priority |
|
|
|
30-09-2009, 21:52
|
#5864 | |
|
Senior Member
Iscritto dal: Jul 2005
Messaggi: 7819
|
Quote:
http://www.hardocp.com/article/2009/..._card_review/8 If you are waiting for NVIDIA to jump out of the GPU closet with a 5800 killer and put the fear into you for making a 5800 series purchase for Halloween, we suggest paper dragons are not that scary. We feel as though it will be mid-to-late Q110 before we see anything pop out of NVIDIAs sleeve besides its arm. We are seeing rumors of a Q409 soft launch of next-gen parts, but no hardware till next year and NVIDIA has given us no reason to believe otherwise.
__________________
Sample is selezionated !
|
|
|
|

|
30-09-2009, 21:54
|
#5865 | |
|
Senior Member
Iscritto dal: Jul 2007
Città: in mezzo alla nebbia
Messaggi: 7763
|
Quote:
__________________
(firma tolta.. era così vecchia che sembrava una mercatino di antiquariato) |
|
|
|
|
30-09-2009, 21:55
|
#5866 |
|
Bannato
Iscritto dal: Jan 2006
Città: Red Light District
Messaggi: 13937
|
Articolo tradotto con Google!
Se vi da fastidio edito e cancello! Introduzione Negli ultimi anni diversi, il paesaggio per l'informatica è diventata sempre più interessante e vario. Forse il primo segno è l'architettura alternativa del processore Cell, che è stata una partenza radicalmente dagli sforzi di CPU da AMD, Fujitsu, IBM, Intel e Sun - buttare parecchi decenni di progressi programmabilità a favore di maggiori prestazioni ed efficienza. Purtroppo, i cambiamenti radicali sembrano relativamente soccombente rispetto alle pressioni graduale di evoluzione e perfezionamento - Cell dimostrato questo punto, in quanto è al di fuori gran parte inutilizzata della PlayStation 3 e non sembra avere molto di un futuro in uso mainstream. GPU si sono progressivamente evoluti per essere meno specifica applicazione e un po 'più generalizzata rispetto ai loro antenati funzione fissi. Le modifiche iniziata nel DirectX 9 tempo previsto, con reali in virgola mobile (FP) i tipi di dati, ma ancora fissato vertice, la geometria e l'elaborazione dei pixel. Hardware DX10 è stato veramente il punto di svolta con shader unificati, i tipi di dati relativamente completi (interi vale a dire sono stati aggiunti) e controllo di flusso leggermente più flessibile. Oggi l'high-end è una gara tra i quattro cavalli nee AMD ATI, Intel e grafica integrata AMD e Larrabee, e Nvidia. Tutti di fronte a quattro diversi obiettivi, i vincoli e, quindi, hanno avuto percorsi leggermente diversi. Gli sforzi di AMD si sono concentrati principalmente sulla grafica eccellenza e migliorare la loro quota di mercato e la presenza in quel campo - sono contento di lasciare che gli altri sopportare lo standard per il calcolo ai fini generali, fino a quando esiste un mercato vero. AMD è consapevole dei costi con la strategia del 'sweet spot' che ottimizza per il cuore del mercato e rifuggendo gli oneri di una maggiore programmabilità, ma non di costo limitato. D'altra parte, il processore Intel e la grafica integrata AMD (IGP) sono gravemente costo limitato; assegnate solo una striscia sottile di silicio in un Northbridge, e presto nello stesso pacchetto o morire come la CPU. Raramente hanno un budget molto grande potenza o di memoria ad alta velocità. Nonostante i risultati conseguenti bassi, sono i titani dei quattro, con circa il 50-60% del mercato, e di accelerare la crescita. NVIDIA è una specie di uomo strano qui, in questo IGP sono fortemente integrata con CPU, di cui sono carenti. Larrabee è un altro paio di maniche interamente. E 'una nuova iniziativa da parte di Intel, promettendo progressi sostanziali in termini di programmabilità che metterà GPU alla pari con le CPU, i programmatori che offrono un potenziale illimitato. Questa visione è convincente, ma non i prodotti arriveranno fino al prossimo anno. Viene per ultimo in ordine alfabetico, ma in prima linea di programmabilità è Nvidia. Storicamente, hanno spinto la programmabilità GPU in avanti, piuttosto che AMD. Essi sperano di percorrere un percorso illuminato di mezzo, tensione verso la programmabilità completa, senza cedere il loro patrimonio grafico per una combinazione di AMD si è concentrata prodotti discreti e IGP. Prodotti programmabili Nvidia sono concentrati sul calcolo ad alte prestazioni (HPC) del mercato, dove i margini sono piuttosto elevati rispetto alle schede grafiche consumer. Prodotto di Nvidia di ultima generazione, il GT200 ha colpito un buon equilibrio. L'architettura certamente spinto la busta di programmabilità, aggiungendo il supporto a doppia precisione, le operazioni atomiche e di un ecosistema l'involo del software, mentre si tiene il massimo delle prestazioni per un prodotto a GPU singola. Al momento, la corona che appartiene in realtà alla Radeon di AMD 5870, che ha lanciato la scorsa settimana. Ottimizzazione focalizzata AMD sta mostrando guadagni in molti segmenti del mercato delle schede grafiche, in particolare quelle sotto i punti 'estreme' dei prezzi, sul mercato mainstream. E 'in questo contesto che Nvidia ha annunciato una architettura di nuova generazione, che mira per prestazioni ancora maggiori, l'affidabilità e la programmabilità, liberare le capacità del software ancora di più. Questa nuova architettura va da diversi nomi per la mantenere gli incauti sulle loro dita: Fermi o GF100, anche se alcuni in stampa sono erroneamente bandying su GT200. NVIDIA ha scelto di discutere principalmente di architettura e di non divulgare microarchitettura più o realizzazione, dettagli in questo annuncio. Dove possibile, il nostro speculazione educato colma le lacune e saranno chiaramente notare come tale. La mancanza di dettagli è in parte dovuto al fatto che i prodotti basati su Fermi, non sarà fuori per diversi mesi - e anche questa linea temporale non è chiaro. Curiosamente, non sono discutendo anche le capacità grafiche di questo chip e invece concentrarsi solo sul calcolo. Di qui la nostra discussione è incentrata principalmente sulla GPU come un dispositivo di calcolo. Pertanto, cercheremo di utilizzare una terminologia standard e indicare dove e come si differenzia la terminologia GPU. The Road to Enlightenment La programmazione CUDA e il modello di memoria sono stati descritti in dettaglio nella nostra analisi precedente del GT200. Questo modello è discendente di DirectX e OpenGL, piuttosto che i modelli tipici di programmazione esposti da PowerPC, x86 e ARM. Come risultato, CUDA e altri modelli di programmazione GPU svolgere molte delle limitazioni di queste API grafiche - una collezione bizantina di spazi di indirizzi e ricordi, con strutture molto semplici dati come array o matrici. Una delle tendenze chiare per prossima generazione di Nvidia di hardware è quello di abbattere questi ostacoli e consentire un maggiore grado di indirezione e supporto alla programmazione. Modello di programmazione La prima serie di questi cambiamenti sono quelli che il flusso di controllo di impatto. Ci sono tre principali miglioramenti qui. Il primo è indiretto ramificate, che è abbastanza comune per le CPU per meritare il suo tipo predictor proprio ramo, ma è stato precedentemente vietato per le GPU NVIDIA. Rami indirette sono quelle in cui l'indirizzo di destinazione non è esplicitamente codificati nelle istruzioni. Invece l'istruzione specifica un registro delle aziende il target ramo (ad esempio,% eax JMP in x86), che consente a un unico ramo di target più indirizzi, in situazioni diverse. Flusso di controllo indiretto consente funzioni virtuali per C + +, e altre lingue. In secondo luogo, la gestione delle eccezioni a grana fine è stato aggiunto. In precedenza non vi era alcuna manipolazione vera eccezione. Ora, ogni corsia singoli vettori (che Nvidia chiama un thread), può innescare un gestore di eccezioni, che sono necessari per il tentativo di raggiungerlo metodi comunemente utilizzati in C + +. Ciò è del tutto non banale - per far scattare un eccezione dello Stato per la corsia vettore devono essere spostati in modo sicuro da qualche parte, in modo che quando si avvia il gestore di eccezioni può ispezionare lo stato. La cosa interessante è che le due caratteristiche di cui sopra può essere abilmente combinati per ottenere il terzo cambiamento programmabilità importante - che consente alla GPU ad effettuare chiamate. La possibilità di salvare lo stato prima di una deroga può essere riutilizzato per salvare lo stato del chiamante, e quindi, indirettamente ramificazione può essere utilizzata per raggiungere una funzione che è già stato caricato nello spazio di indirizzi. Chiamate ricorsive sono supportati come bene, anche se Nvidia non ha al momento rivelato l'ABI e le convenzioni di chiamata. Questo è un bel passo in avanti notevole in termini di programmabilità, ancora una volta si allontana da un modello semplicistico GPU verso un ambiente più completo. Modello di memoria Uno dei passaggi chiave per Nvidia, con il loro hardware di prossima generazione è quello di ripulire il loro modello di memoria confusa e creare uno spazio unico indirizzo unificato per locali (thread privati), in comune (per ogni blocco di thread) e memoria globale (dispositivo e per tutto il sistema ). Essi sono stati consolidati nel esistenti a 40 bit virtuale e fisica dello spazio degli indirizzi utilizzati dagli GT200. In precedenza istruzioni di carico separate sono stati utilizzati per accedere a ogni spazio indirizzo, e questi sono stati soppiantati da una singola istruzione di carico. Al momento della compilazione, gli indirizzi per queste memorie sono determinati, e l'hardware sia configurato correttamente il percorso prende il sub adeguato spazio. Con uno spazio unificato indirizzo, indirezione di strutture di dati è possibile. NVIDIA supporta ora puntatori e riferimenti agli oggetti, che sono necessarie per C + + e linguaggi di livello più alto di altri che passano di riferimento. Sulla stessa nota, Nvidia ha aggiunto una nuova modalità di indirizzamento, come richiesto dalla OpenCL. Le immagini sono un cittadino di prima classe per OpenCL e richiedono (x, y) affrontare la modalità per migliorare il trattamento dei dati grafici. Questi sono i cambiamenti più significativi a livello mondiale a ISA Nvidia, ma ci sono altre più sottili cambiamenti che verranno spiegate successivamente in la sub-sezione appropriata. System Architecture Architettura Nvidia sistema continua a concentrarsi sul rendimento più elevato per un monolitico GPU, e quasi il reticolo di riempimento per i sistemi di TSMC litografia. Ciò è determinato da tre fattori. Dal punto di vista del calcolo, cercando di programma di due GPU in parallelo è estremamente scomodo, in modo da massimizzare le prestazioni di una GPU singola è indispensabile per i programmatori. Inoltre, la competizione per computer ad alte prestazioni (HPC), i sistemi non è una singola CPU, ma piuttosto un sistema dual socket HPC orientato con 4-6 core per socket. GPU Nvidia massiccia costruzione consente di mantenere la corona di più le prestazioni delle GPU singola, che viene percepito di avere un 'Halo', un valore di marketing che si estende in tutta l'intera linea di prodotti (anche schede di fascia bassa). Il rovescio della medaglia, naturalmente, è che i chip di grandi dimensioni non sono a buon mercato per la produzione, come i rendimenti non drop-lineare con la dimensione del die. Figura 1 qui sotto mostra l'architettura del sistema di Fermi, GT200 e G80. Nonostante le etichette, G80 ha solo cache consistenza, proprio come GT200. Figura 1 - Fermi e GT200 System Architecture L'architettura di Fermi sistema è molto più pulito e più elegante rispetto alla generazione attuale, in cui tre nuclei condivisa una pipeline di memoria. Fermi dispositivo è di 16 core, ma ciascun core (o SM nel gergo Nvidia) è cresciuto in modo sostanziale con 32 unità funzionali e di un semi-coerente cache L1, che possono essere 16KB e 48KB di dimensione. Si tratta effettivamente di semi-cache coerente, a differenza delle generazioni attuali e precedenti, anche se i dettagli saranno toccati in seguito nella sezione appropriata. Le cache L1 sono legati insieme da una 768KB di cache L2 condivisa, che è l'agente di memoria e può aiutare con alcuni di sincronizzazione. Fermi ha sei controller di memoria GDDR5, che operano ciascuna due canali di memoria. L'interfaccia di memoria 384-bit wide e può anche essere configurato per accedere alla memoria DDR3. Dal momento che Nvidia non è di comunicare qualsiasi prodotto o le caratteristiche operative del Fermi, dobbiamo fare alcune ipotesi plausibili per quanto riguarda la larghezza di banda di memoria. A velocità GDDR5 di 3.6gbps, ciò comporterebbe 172.8GB / s di banda passante di memoria, appena fuori bordo che offre più recenti di AMD. Una interfaccia di memoria DDR3 operanti a norma 1.6gpbs tasso produrrebbe solo 76.8GB / s, mentre un 1,575 volt, 2Gbps interfaccia otterrebbe 96GB / s. Qualcosa da tenere a mente, però, è che il calcolo GPU operano tipicamente orientato la loro memoria interfacce a frequenze inferiori - Tesla ha raggiunto la posizione 1.6GT / s GDDR3 rispetto 2.2GT / s per i prodotti di consumo orientati, probabilmente per motivi di stabilità e di capacità. DRAM utilizzando x16 in un unico grado, possono accedere Fermi 24 dispositivi. In teoria, ciò significa che il satellite Fermi supportano fino a 6GB con DRAM 2Gbit e 12GB con dispositivi 4GBit. Al momento, però, non ci sono ad esempio nella produzione di DRAM, solo offerte 1GBit da Qimonda, Samsung e Hynix. Qimonda ha annunciato pubblicamente che si terra dispositivi 2Gbit po 'di tempo nel 2010, però, e ha espresso l'interesse delle DRAM 4GBit ulteriormente sulla loro tabella di marcia. Un'altra alternativa per aumentare la capacità sarebbe utilizzando due file di DRAM, anche se questo probabilmente ridurre la frequenza di funzionamento. L'interfaccia esterna al resto del sistema è invariato, sempre basandosi su PCI-Express Gen 2, ma la logica di controllo è migliorato. Fermi possono ora trasferire simultaneamente i dati da e verso l'host, che permette il calcolo della GPU per essere meglio pipeline rispetto al resto del sistema. Pianificazione gerarchica La gerarchia di controllo è simile a quello GT200, con uno scheduler globale che questioni di lavoro per ogni SM. In precedenza l'utilità di pianificazione a livello mondiale (e quindi la GPU) potrebbero avere solo un singolo kernel in volo. Più recenti scheduler Nvidia può mantenere lo stato per un massimo di 16 kernel diversi, uno per ogni SM. Ogni SM gestisce un singolo kernel, ma la capacità di mantenere kernel multipli in volo l'utilizzo aumenta soprattutto quando un kernel comincia a finire e ha meno blocchi di sinistra. Ancora più importante, l'assegnazione di un kernel per mezzo di base che i kernel più piccoli possono essere spediti in modo efficiente alla GPU. La latenza di context switch tra il kernel è stato inoltre ridotto da 10X a circa 25 microsecondi, questo ritardo è dovuto in gran parte per la pulizia dello Stato che ogni kernel deve brano - come TLB, i dati sporchi in cache, registri, la memoria condivisa e gli altri kernel contesto. Figura 2 - Fermi e GT200 Panoramica Come sopra illustrato nella figura 2, Fermi è un grande cambiamento da GT200, in particolare per la gerarchia di memoria. I core in GT200 non sono completi e ogni gruppo di tre nuclei azioni di una pipeline di memoria - questo ente è chiamato Thread Processing Cluster (TPC). Fermi sopprime questa disposizione e dà a ciascuno la sua unità core store proprio carico (LSU) e L1D, anche se uno condivisa tra i due gasdotti di esecuzione. Fermi SM Panoramica I nuclei (o SMS) di Fermi è stata notevolmente rinforzati e le risorse sono state spostate in modo sostanziale. Ad alto livello, le risorse di esecuzione sono quadruplicati, ma sono condivisi tra due condotte di esecuzione scalare; ogni gasdotto ha il doppio delle risorse di esecuzione corsie vettore (o), del core GT200. È essenziale notare che, mentre i due gasdotti in grado di eseguire due orditi dal blocco stesso thread, non sono superscalare, nel senso di una CPU. La pipeline di memoria è stato portato nel nucleo, mentre in precedenza ogni pipeline di memoria è stata condivisa fra tre core. Ancora più importante, la memoria condivisa è stato piegato in un (semi-coerente) L1 cache di dati, dando ogni core di una gerarchia di memoria reale. Per molti aspetti, queste modifiche sono concettualmente ricorda i miglioramenti tra Niagara I e II. Niagara II raddoppiato il numero di thread a 8, ma ogni set di 4 thread aveva uno scheduler e dedicato interi (ALU) gasdotto, rispetto al ALU dedicata e in virgola mobile (FPU) gasdotti per il Fermi. Tutti e 8 i fili in un nucleo Niagara II condotte di memoria condivisa, come Fermi, e FPU, che sono analoghe alle unità speciali di funzione (SFU). Di utilizzare tali risorse di esecuzione, il numero di thread in volo per ciascun core Fermi è aumentata del 50% a 1536, dislocate su 8 blocchi di thread simultanei. Questo significa che per utilizzare appieno uno dei nuovi nuclei, 192 fili per blocco sono necessari fino da 128 in GT200. Come per l'attuale generazione, l'esecuzione all'interno di un SM avviene a granularità di una trama, che è un insieme di 32 thread. Con l'aumento delle discussioni, ciascun core può avere fino a 48 orditi in volo alla volta. Come con tutto l'hardware Nvidia DX10, Fermi ha diversi domini di clock differenti in ciascun core - principalmente per regolare l'orologio front-end e la programmazione, e quindi l'orologio veloce per le unità di esecuzione effettiva che funziona a due volte l'orologio regolare. Front End I cambiamenti nel nucleo (o SM) comincia a front-end e la cascata da lì. Fermi ogni core ha una cache istruzioni, con la lettura standard semantica solo - anche se ogni altro dettaglio sulla cache L1I è attualmente sconosciuto, sia per quanto riguarda la GT200 e Fermi. In Fermi, la cache di istruzioni è condivisa tra i due gasdotti ed è quasi certamente una scenografia associative. La Figura 3 illustra i core da Fermi e GT200. Figura 3 - Front-end per Fermi e GT200 Cores Purtroppo, Nvidia non è ancora rivelare la dimensione della cache istruzioni, che potrebbe anche ricordare il suo scopo e la funzionalità. Se l'obiettivo è quello di cache più di un kernel (o shader) e sfruttare le località temporale, la dimensione della cache dovrebbe essere una frazione ragionevole di un singolo kernel. Tuttavia, se il punto è quello di amplificare solo la larghezza di banda, che potrebbe essere fatto con una cache molto piccolo, o forse da abilmente trasmissione un'istruzione fetch alle code Instruction Multiple curvatura. Ciò che è chiaro però è che le cache istruzioni sono state modificate in modo sostanziale Fermi, dal momento che ciascun core può essere in esecuzione di un diverso flusso di istruzioni. Fermi introduce predicazione completa per tutte le istruzioni per migliorare l'istruzione fetch eliminando le bolle causate da rami presa. In GT200, una divergenza si tradurrebbe in un ordito di esecuzione e quindi attraverso la diramazione tra ogni percorso del flusso di controllo. Ad ogni ramo, la curvatura di stallo fino a quando il ramo potrebbe essere risolto e l'indirizzo successivo recupero. Con la predicazione, la curvatura è possibile eseguire in modo sequenziale attraverso tutti i percorsi divergenti del flusso di controllo, senza rami, e semplicemente mascherare le corsie inutilizzati vettore. Il prossimo cambio della GT200 è solo dopo la cache. Fetched istruzioni sono consegnati dalla cache e poi depositati in due buffer di istruzione logica ordito per Fermi, uno per ciascuno dei due gasdotti. Questi buffer probabilmente implementato come un insieme di 48 code, una per ogni curvatura. Ogni coda contiene probabilmente almeno due voci - che richiedono 128-bit come la maggior parte istruzioni prime sembrano essere a 64 bit [1]. Se 96 voci sono state attuate che consumano un totale di 768B di SRAM. Tuttavia, supponendo che le linee di cache istruzioni sono 64B ampio, allora è più probabile che ogni operazione di recupero in 4-8 porta le istruzioni per ordito, con un buffer più grande (circa 1.5-3KB). Una volta che le istruzioni sono depositati nel code di curvatura, essi devono essere decodificati in modo che possano essere programmati. Ogni ciclo, i due di pianificazione può emettere (o della spedizione in gergo Nvidia) due orditi dalla testa di queste code - uno per ciascuno dei due gasdotti. Ancora una volta, per ciascuna condotta è ancora scalare, ma ora ci sono due per un throughput aggiunto. Nonostante l'idea che core GPU sono più semplici di core della CPU, l'utilità di pianificazione devono affrontare notevole complessità. Una complicazione per lo scheduler è la varietà di istruzioni di calcolo con una latenza di esecuzione diversi. Istruzioni Pianificazione con una latenza uniforme o quasi uniforme è molto più semplice che cercare di gestire un pool di istruzioni in cui la latenza di esecuzione varia di un fattore 4. Le curvature sono scoreboarded per tenere traccia della disponibilità degli operandi e anche diffidare di eventuali rischi strutturali. I rischi strutturali, in particolare, sono molto più complicate per Fermi che la GT200. Le risorse condivise di esecuzione presente parte della sfida qui - il gasdotto di memoria e unità di funzione speciale (SFUs) sono i punti evidenti di contesa tra le due condotte, ma a 64-bit operazioni FP sono anche una questione sottile. In particolare, una curvatura doppia precisione utilizza entrambe le condotte contemporaneamente da eseguire. Così le combinazioni consentite ordito sono più memoria / ALU, ALU / ALU, ALU / SFU e la memoria / SFU; doppia precisione non può essere rilasciata con qualsiasi altra cosa. Pianificatori emetterà la priorità più alta, pronta a eseguire curvature e quindi contrassegnare le code di alcuni come 'non è pronto', sulla base della latenza atteso l'istruzione - e l'utilità di pianificazione permette di saltare su di loro fino a quando non diventano di nuovo pronto. Come per l'attuale generazione, non c'è nessuna penalità per la commutazione tra le diverse code, ed è probabile che la stessa coda potrebbe continuare a rilasciare pure. Priorità può essere determinato sulla base di diversi fattori come il tipo di shader (vertex, geometria, pixel, calcolare), l'utilizzo di registro, ecc Un altro grande cambiamento per i programmatori e lo scheduler è la latenza relativa esecuzione. Dal momento che ogni unità dispone di 16 pipeline di esecuzione, una trama semplice prende ora solo 2 cicli veloci per finire (o un ciclo di pianificazione). Ciò significa che nasconde un importo fisso di latenza della memoria avrà il doppio di orditi molti come prima. Non è chiaro se il buffer di curvatura e di pianificazione è effettivamente messo in atto come una entità unitaria o frazionata. Un scheduler split sarebbe probabilmente più efficace, dal momento che ogni scheduler avrebbe solo di valutare 24 del 48 curvature potenziale; la parte difficile sarebbe comunicare quando uno scheduler ha riservato una risorsa condivisa, come il gasdotto di memoria o SFU. Registri Come mostra la figura 3 nella pagina precedente ha mostrato, le risorse già massiccia di archiviazione per ciascun core sono stati raddoppiati a sostenere il secondo gasdotto. Registrati Fermi file aumentata a 32K voci o 128KB totale, sebbene il numero di registri per unità di esecuzione che dimezzato, a 1K, le voci contro l'attuale generazione. Nella GT200, un singolo thread può essere assegnato 4-128 registri - anche se non è chiaro se Fermi offre la stessa gamma. Come nel caso di implementazioni precedenti, interi a 64 bit o valori in virgola mobile si consumano due registri. Il file di registro è stato progettato per sostenere la piena a 32-bit per ogni ciclo di throughput, che richiede 96 i valori di input e 32 i valori di uscita, nel caso di un multiply-add. Operando Collectors Uno degli aspetti più sconcertanti di hardware Nvidia attuali e passate, è la lettura e writeback per le unità di lunga latenza funzionali, come la SFU e pipeline di memoria. Nella GT200, un ordito di SFU può essere rilasciato, seguita da un ordito FMAD, poiché l'istruzione SFU prende un po 'di eseguire, i due saranno eseguiti contemporaneamente. Forse ancora più importante, le due curvature sembrano aver bisogno di input simultanei - che pone la questione, come possono essere alimentati tutti in una volta? La risposta, un pezzo di hardware chiamato collettore operando, è venuta alla luce nelle nostre discussioni in merito Fermi. I collettori operando sono unità hardware che leggono i valori registrati molti e li buffer per il consumo dopo, una sorta di cache registro temporale per le unità funzionali (abbastanza interessante, il EV8 aveva qualcosa di simile). Probabilmente fornire anche altri vantaggi - forse trasmissione dei valori tra le unità funzionali. Così il collezionista operando in grado di leggere tutti 64 operandi necessari per un'operazione di SFU, e allora che li alimentano la SFU per i prossimi 16 cicli. Questo semplifica radicalmente la pianificazione, consentendo ingressi per essere raccolte in una sola volta, anche per le istruzioni di latenza elevata. Inoltre, i collezionisti operando può essere cablato con una traversa per consentire numerose a basso numero di porte (ad esempio, 1R 1 W o 1R / W) registrare i file di apparire come se fossero un unico file di registro molto portato. Mentre il collettore operando più, ovviamente, funziona con i file di registro, si può anche essere in grado di raccogliere operandi da altre fonti, come memoria condivisa e costante o texture cache. Fermi, la GT200 e le generazioni G80 probabilmente tutti comprendono i collezionisti operando, e le dimensioni minime sono probabilmente 64 o 96 operandi. Risultati coda Gli stessi conflitti potenziali che si verificano per il registro si legge, di cui sopra, si applicano anche alle scrive nel file di registro. Il duale al collettore operando è la coda di risultati, che il buffer di uscita da unità funzionali prima di essere scritta nel file registro. Per essere efficace la coda risultati dovrebbero essere almeno la dimensione di un ordito - 32 operandi. Anche se non necessariamente presenti in hardware Nvidia, la coda di risultati crea un'opportunità per l'ottimizzazione supplementari. In particolare, non tutte le operazioni devono writeback nel file di registro - alcune operazioni di esistere solo per produrre un risultato intermedio che viene consumato da un'altra operazione. In tale situazione, se i due può essere dinamicamente in programma abbastanza vicino, è ipotizzabile che il valore di uscita potrebbe essere trasmessa con l'ingresso della prossima operazione - proprio come una rete di CPU di inoltro, fatta eccezione nella corsia vettore. Esecuzione Unità Il cuore di hardware Nvidia di nuova generazione è in realtà le risorse all'interno di ciascun core di esecuzione, non solo hanno questi stata aumentata, ma essi sono stati sostanzialmente raffinati pure. Il solo numero di ALU e FPU per core ha quadruplicato nel corso degli GT200 attuale generazione, ma ora sono divisi tra due condotte indipendenti con 16 unità ciascuna. Così la latenza di un singolo ordito viene dimezzata a due cicli e il volume è raddoppiato con due bracci da diversi gasdotti. Per inciso, questo mette in evidenza uno dei motivi per utilizzare un concetto microarchitectural come l'ordito - che consente di ampliare le risorse di base di esecuzione. Figura 4 qui sotto mostra le carote per la GT200 e Fermi. Figura 4 - Esecuzione Locale Fermi e GT200 Cores Ogni unità di esecuzione (che Nvidia chiama un core "CUDA") ha dedicato un intero (ALU) e uno in virgola mobile (FPU) il percorso dei dati. I due percorsi dati parti una porta problema e non possono essere rilasciati contemporaneamente. La ALU è stato aggiornato con nuove operazioni e una maggiore precisione. Moltiplica Integer sono nativi a 32-bit adesso, invece di 24 in GT200, anche se eseguite a velocità dimezzata - ogni pipeline in grado di eseguire 8 moltiplica per intero ciclo. Inoltre, il bit-wise operazioni necessarie per DX11 sono supportati, tra cui bit-conta, inserti, estratti e molti altri. Sostegno maggiore precisione è una priorità anche per Fermi. Operazioni a 64-bit semplice ALU, come l'addizione e sottrazione, può essere fatto da cracking l'operazione in metà di 32 bit a basso e alto, e utilizzando la ALU con mezza throughput. 64-bit richiede la moltiplicazione di interi quattro operazioni, in modo che ciascun pipeline in grado di eseguire 4 moltiplica per ciclo e il nucleo di tutto in grado di eseguire 8 per ciclo. La microarchitettura a virgola mobile è stato interamente rinnovato nel corso degli GT200. La GT200 presenta una singola dedicato doppia precisione (DP) FPU per ogni core (versus 8 FPU singola precisione), con conseguente prestazioni unimpressive. Questo approccio è stato senza dubbio guidato da tempo estrema alle pressioni del mercato, in quanto è chiaro che ci sono altri metodi più efficienti anche se con una sostanziale complessità della progettazione di più. Per Fermi, Nvidia è chiaramente volto a massimizzare le prestazioni doppia precisione FP e abbracciato la complessità aggiuntivi necessari. Ciascun core può eseguire un DP fusa multiply-add (FMA), ordito in due cicli utilizzando tutte le FPU in entrambi gli oleodotti. Significativamente, questa è l'unica istruzione ordito che richiede l'uso di entrambi gli oleodotti problema, il che suggerisce alcuni dettagli di implementazione. Mentre l'approccio di Nvidia osta che rilascia due orditi, invece di un rapporto di 8:1 di SP: throughput DP (o 12:1 contare la questione apocrifi doppia), il rapporto di Fermi è di 2:1. Questo è alla pari con Intel e AMD attuazione di SSE e in vista del rapporto di 4:1 per AMD processori grafici. Ricerca suggeriscono che l'area e le sanzioni di ritardo per questo stile di precisione più FPU sono circa il 20% e del 10% su una singola DP FPU [2], ma è probabile che il sovraccarico di Nvidia è leggermente inferiore. Il risultato finale dovrebbe essere un ordine di grandezza aumento delle prestazioni doppia precisione con la stessa frequenza - un bel salto in avanti di una sola generazione. La singola precisione (SP), le prestazioni in virgola mobile, con un aumento del numero di corsie vettore, ma anche diventato più raffinato e utile da un punto di vista numerico. Nella GT200, SP era quasi IEEE-754 conforme, ma mancava di alcune modalità di arrotondamento e la manipolazione denormalizzati. Questo non è un problema per la grafica, ma per reale applicazioni numeriche certamente lasciato un po 'a desiderare. NVIDIA rettificato questi problemi, e ha anche sostituito il precedente 32-bit multiply-add con istruzioni a 32-bit fusi multiply-add (FMA), portandolo in linea con il comportamento DP (che aveva FMA dal GT200). Qui la distinzione è sottile e ha a che fare con arrotondamento intermedi. In un normale multiply-add, il risultato della moltiplicazione viene arrotondato a 32-bit di precisione, prima l'aggiunta è fatta. Con un FMA, non vi è alcun arrotondamento intermedio, così la precisione interna è più alta - che è vantaggiosa per la divisione e l'emulazione radice quadrata. L'ultima modifica alle risorse di esecuzione si trova nella funzione speciale Unità (SFUs). Poiché il numero di ALU e FPU per oleodotto è raddoppiato in tal modo dimezzare la latenza di queste curvature, Nvidia anche raddoppiato il numero di SFUs fino a 4 per core in modo che la latenza di un ordito SFU è diminuito in tandem. Tuttavia, per risparmiare spazio e del potere, SFUs sono condivisi tra le due condotte di esecuzione - una scelta eminentemente design ragionevole dato l'uso frequente. Come con la generazione precedente, l'esecuzione SFU possono sovrapporsi con ALU o l'esecuzione FPU, grazie ai collezionisti operando e le code di risultato. È interessante notare che, mul extra apocrifi ', che sembrava solo a sollevare la sua testa nelle prove di sintesi non c'è più, un artefatto della storia Nvidia marketing. Per fortuna, è stato sostituito da due condotte reali che possono essere utilizzati in applicazioni reali. Nucleo della memoria I cambiamenti nel core di esecuzione sono importanti e migliorare sostanzialmente le prestazioni. Ma ancora più importante ed emozionante è il fatto che gli ingegneri e gli architetti Nvidia ha deciso di utilizzare un semi-coerente L1D cache per ogni core pipeline di memoria, che consente la comunicazione implicita tra i thread in un blocco di cache e una porzione dello spazio unificato indirizzo per ridurre off -chip requisiti di larghezza di banda. Pipeline Fermi di memoria ha un throughput fino a 16x32-bit o 8x64-bit accede a ogni ciclo, né alla memoria condivisa, ovvero l'unità di carico store (LSU), che accede alla cache L1D, ma non entrambi. Le ragioni sarà evidente a breve, ma questo crea un pericolo strutturale che lo scheduler deve rappresentare, per esempio, un ALU / Mem dove la combinazione di fonti di dati operazione ALU dalla memoria condivisa non è permesso. Memoria condivisa La memoria condivisa in Fermi ha subito una radicale trasformazione della GT200. In Fermi, la memoria condivisa e L1 cache dati sono rispettivamente utilizzati per la comunicazione esplicita ed implicita tra i thread. I due sono implementate come un'unica struttura fisica, si sono divisi a 16 singola sopraelevate, 64KB array. L'accesso simultaneo sarebbe possibile, ma solo replicando l'ingresso e uscita e aumentando ulteriormente il settore bancario. L'array può essere configurato con una memoria di 16KB e 48KB condiviso, con il resto utilizzato per la cache L1D. Per i grandi carichi di lavoro che vengono scritti e raccolti 16KB di memoria condivisa (ad esempio GT200), può essere preferibile utilizzare una 48KB di cache L1, dal momento che una memoria condivisa più grande può andare inutilizzata. Lo stesso vale per OpenCL che supporta solo 16KB di memoria condivisa al momento. Una cache più grande è benefico anche sui carichi di lavoro irregolare e imprevedibile, soprattutto quelli con maggiori gradi di rinvio (ad esempio, strutture dati complesse come liste collegate). Per DirectCompute però, un maggiore spazio di memoria condivisa (fino a 32KB) è necessaria e quindi avrebbe bisogno di una dotazione di 48KB. Fortunatamente la configurazione è semi-dinamico. La cache e la memoria condivisa può essere riconfigurato, se l'intero nucleo è quiesced, in genere tra due diverse applicazioni, ma in teoria la configurazione potrebbe essere fatto tra i noccioli. E 'piuttosto chiaro per quale motivo non vi è una opzione per 48KB di memoria condivisa; mi sembra uno spreco. Né DirectCompute né OpenCL possibile utilizzare l'intero 48KB - mi sembra una scissione 32KB/32KB sarebbe più sensato, ma presumibilmente architetti Nvidia ha avuto le loro ragioni. La memoria condivisa è stato anche influenzato dalla conduttura ulteriori modifiche e unità di esecuzione. In GT200, il 16KB intero e 16 provenienti da banche di memoria condivisa è stato utilizzato solo da una singola pipeline, e potrebbe fornito 16 operandi di una curvatura. Ora che la memoria condivisa può essere diviso tra due condotte, la capacità disponibile per ciascun pipeline può diminuire (in una configurazione 16KB) impatto occupazione, e l'accesso condiviso a ridurre la larghezza di banda disponibile per ciascun curvatura. Data Cache Il gasdotto di memoria, che inizia con la semi-coerente L1D, ha enormi cambiamenti. Prima di tutto, non è più comune tra i vari core. L'intera nozione di una TPC è quindi andato, come è stato in gran parte un artefatto di come la gerarchia di memoria diversa dalla gerarchia di controllo in GT200 e G80. La Figura 5 riporta i gasdotti di memoria per Fermi e GT200. Figura 5 - Memory Pipeline di Fermi e GT200 La pipeline di memoria inizia con unità di produzione dedicate indirizzo (AGUS). Il AGUS sono stati modificati per supportare il nuovo (x, modalità y) affrontare, su richiesta del OpenCL. Questa terza modalità affrontare, completa il registro esistenti indiretta e la consistenza di indirizzamento. In Fermi, vi è un solo carico e memorizzare le istruzioni per quasi tutti i tipi di memoria, anche se texturing possono richiedere un insegnamento diverso dal momento che è così diversa da altri punti di accesso. Una volta che l'40-bit indirizzo virtuale è stato calcolato, si è tradotta da un 40-bit indirizzo fisico da parte delle TLB. TLB Fermi, ovviamente, il supporto 4KB dimensioni di pagina per ragioni di interoperabilità, ma non ha voluto rivelare il più grande sostegno dimensioni della pagina. GT200 sembra sostenere 512KB pagine [3] [4] ed è probabile Fermi ha le stesse capacità. La dimensione o associatività del TLB non è stato divulgato anche per Fermi, ma ha solo bisogno di coprire i dati accessibili da un unico core. Il TLB L1 in GT200 si crede di essere una voce di 16-32, design completamente associativo con 4KB e 512KB di sostegno [3] [4], ed è probabile che il TLB Fermi sono le stesse dimensioni o leggermente più grandi. TLB di controllare anche i privilegi - e le pagine possono essere contrassegnati come di sola lettura (ad esempio, le costanti). Una volta che gli indirizzi sono tradotti, la cache è sondato per accessi 16x32-bit, o 8x64-bit accede a ogni ciclo. La cache L1D è probabilmente una riscrittura e scrivere destinare 64B design con linee e supporto per lo streaming di alcuni dati direttamente alla memoria principale. La politica di sostituzione è sconosciuta, ma è probabile che uno pseudo-Least Recently Used (LRU) variante. Come accennato in precedenza, il L1D o è 16KB e 48KB, con 16 banche per un throughput elevato. L'associatività dei L1D è sconosciuto, ma l'organizzazione implica che ogni modo è 16KB o più piccoli. Data la cache altamente associativa nelle generazioni precedenti [3c], è probabile che il L1D è effettivamente a 16 o associative modo migliore. Nel caso di perdere, l'accesso andrà alla cache L2, che è discusso (accanto alla semi-coerenza) nella sezione successiva. L2 Cache La cache L2 merita propria sezione per una serie di motivi - non solo è la chiave per la coerenza e le operazioni atomiche, ma è anche nel suo dominio orologio. Il 768KB di cache L2 unificata è l'agente esclusivo di memoria, carichi di movimentazioni, negozi e texture recupera - in modo da agire come un punto di inizio di sincronizzazione globale. Come la cache L1, probabilmente ha 64B linee e molte banche, la scrittura politiche saranno discussi di seguito. Mentre Nvidia non ha discusso i dettagli di attuazione, il GT200 ha una cache di 256 KB texture L2, implementato come 8 fette di 32KB, una fetta per la memoria del controllore. Se Fermi segue questo modello, la cache L2 può essere implementato come 6 fette di 128KB, uno per ogni controller di memoria. A differenza di una CPU, la cache di Fermi sono semi-coerenti solo a causa del modello relativamente debole coerenza delle GPU. Il modo più semplice di pensare la consistenza è quella di default è la sincronizzazione tra il kernel, e se il programmatore utilizza qualsiasi primitive di sincronizzazione (ad esempio Atomics o barriere), ma nessun ordinamento altrimenti. Ciascun core può accedere a tutti i dati in suo L1D cache condivisa, ma in generale non può vedere il contenuto della cache remota L1D. Alla fine di un kernel, le carote devono write-through lo sporco dati L1D per la L2 per renderlo visibile ad altri in entrambi i core della GPU e l'host. Questo potrebbe essere descritto come un pigro politica write-through per la L1D, ma sembra più accuratamente descritto come scrivere indietro con la sincronizzazione periodica. Politica di scrittura per la L2 è probabilmente una sorta di write-back con il supporto per lo streaming accessi. Alcuni dati è improbabile da essere riutilizzato come si sta in streaming e la memoria - i dati devono essere scritti con la memoria globale, senza alcuna assegnazione L1 e L2. Altri dati sono suscettibili di essere riutilizzati o condiviso, e dovrebbe essere scritto indietro e assegnati in L2. In genere le CPU hanno writeback con l'assegnazione per i loro nascondigli, ma alcune aree di memoria sono in cache e utilizzati per lo streaming - questa sembra una ipotesi ragionevole per la progettazione L1 e L2 di Fermi. La politica di sostituzione di cache L2 è attualmente sconosciuto, ma è probabile che alcuni pseudo-LRU variante. Poiché la L2 è utilizzato per rendere visibili i risultati a livello globale, ma può anche essere utilizzata per accelerare l'esecuzione delle operazioni a livello mondiale atomica, che permette la sincronizzazione più efficiente tra i blocchi thread in tutto il chip. In precedenza, le operazioni atomiche doveva scrivere torna alla memoria globale per rendere visibili i loro risultati a livello mondiale. In tal modo la latenza minima è stata di circa 350-400ns per GT200 [3] [4]. Se le operazioni multiple in un ordito si contendevano lo stesso indirizzo, ogni atomica avrebbe eseguito serialmente, provocando un ulteriore viaggio nella memoria - una sanzione fino a 32X, nel caso peggiore (~ 13.000 ns). Atomics memoria condivisa sono stati di gran lunga più veloce, ma la memoria condivisa è ovviamente limitata capacità e non possono essere utilizzati per comunicare tra i blocchi o core. In Fermi, la cache L2 ed extra unità di esecuzione atomiche sono utilizzati per accelerare le operazioni atomiche. Fermi cache L2 unificata serializza operazioni atomiche in modo diverso, per ridurre il numero di memoria riprese di valore nette. Nel caso di contesa pieno (32x32-bit accessi allo stesso indirizzo), il nuovo percorso di esecuzione atomica probabilmente fare tutto serializzazione prima di scrivere alla memoria - in modo che solo uno o due accessi alla memoria sono necessarie. C'è overhead aggiuntivo dalle operazioni reali, in modo da Nvidia superiore pretesa fine di una velocità di 20X fino riferisce solo al caso estremo di ridurre gli accessi di memoria 32-1, con un overhead di esecuzione. Questo a sua volta implica che l'esecuzione di 32 operazioni atomiche (escluso il write-back) è di circa la latenza come mezzo un viaggio nella memoria, forse intorno a 100-200ns. In più realistici scenari di utilizzo, i vantaggi che le nuove operazioni atomiche saranno notevolmente inferiori, e in ultima analisi dipende la realizzazione delle operazioni atomiche, che non è stato divulgato. NVIDIA ha affermato incrementi nella velocità di 5-20X, purtroppo è difficile prendere in giro lo scenario corrispondente a una velocità di 5X up - e quindi per determinare se si applica davvero comuni usi atomica. Essa può avere a che fare con le unità supplementari atomica, che possono essere utilizzati in parallelo per le operazioni di uncontended, o può essere che molti casi di operazioni atomiche procedere con la latenza come prima - certamente condivisa Atomics memoria sono rimasti gli stessi. Fino a quando l'hardware viene rilasciato e analizzato, è solo un gioco di indovinare. Per le attività non nucleari, la L2 atti anche a confluire molte richieste di memoria differenti (per esempio da un ordito complesso) in operazioni di meno, migliorando l'utilizzo della larghezza di banda. Affidabilità Come avevamo previsto in precedenza, Fermi avrà il sostegno ECC opzionale per proteggere i dati memorizzati nella memoria, sia per le DDR3 e GDDR5, e l'on-array chip SRAM sono inoltre protetti. Il primo è sorprendente, come è stato progettato per DDR3 ECC fin dall'inizio. Tuttavia, ECC per la memoria grafica è molto più interessante, in quanto gli ingegneri Nvidia ha dovuto andare al di là delle specifiche GDDR5 per raggiungere tale livello di protezione. Purtroppo, Nvidia non ha svelato gli algoritmi e le tecniche utilizzate per ECC. Tuttavia, essi hanno detto che quando si usa ECC hanno osservato un calo delle prestazioni dell'applicazione del 5-20%, con alcune applicazioni che soffrono ancora di più. Questo probabilmente corrisponde a un calo del 25-30% nella larghezza di banda di memoria. Sarà interessante vedere i reali meccanismi e quanto la larghezza di banda e la capacità realmente costo, soprattutto se hanno fatto qualcosa di particolarmente nuovo. Utilizzando ECC consente di proteggere i dati memorizzati in DRAM, ma non necessariamente proteggere i comandi, gli indirizzi ei dati che vengono inviati dal DRAM al controller di memoria (e vice versa) - che è il ruolo delle specifiche di interfaccia di memoria. GDDR5 è facoltativamente CRC e riprovare la protezione per le linee di trasmissione dei dati che corrono tra i controller di memoria e le DRAM, che Nvidia sicuramente uso. Tuttavia, la specifica GDDR5 non ha nessun supporto per proteggere il comando e affrontare le linee [5]. Così, mentre la trasmissione di dati possono essere protetti, non vi è alcuna garanzia che i dati siano effettivamente proveniente dalla posizione destra. Nvidia sostiene di avere un qualche tipo di protezione per il comando e affrontare le linee in GDDR5, che è possibile, ma sembra un po 'improbabile, senza una spiegazione del modo in cui esattamente raggiungere questo obiettivo. Ad esempio, ciascuna delle linee di comando e di indirizzo potrebbe essere replicata sul controller e di bordo e quindi verificata una contro l'altra prima di terminare al DRAM - ma questo sarebbe solo di individuare una classe molto limitato di errori. Questo non vuol dire che le affermazioni di Nvidia sono irragionevoli, ma a questo punto, lo scetticismo è meritato fino a quando i metodi effettivi sono resi noti. Astute lettori noteranno che DDR3 non ha alcuna protezione di sorta. Tuttavia, questa non è la carenza grave sembra essere, come le linee dati sono sostanzialmente in esecuzione più lenta (massimo di 2 Gbps, rispetto a un minimo di 3.6gbps per GDDR5), quindi la possibilità di errori di trasmissione è di gran lunga inferiore. Ingegneri Nvidia ha inoltre deciso di proteggere la 3.75MB on-array di chip SRAM con ECC, utilizzando un unico standard di errore corretto e duplice errore di rilevare (SECDED) algoritmo. Questo comprende i file 16x128KB registro, le cache 16x64KB L1D e 768KB di cache L2. La cache L1I non può essere protetto, in quanto è di sola lettura. Per ora più ottimizzazioni avanzate, come tollerare fallimenti DRAM, pro-memoria attiva o lavaggio SRAM, non vengono attuate. Ma CPU di fascia alta come quelli di IBM e Intel hanno già calcato molto lontano su questa strada, lasciando una chiara tabella di marcia dovrebbe Nvidia e gli altri scelgono di seguire. Software Tutti i progressi in termini di programmabilità sono interessanti, ma fondamentalmente contare su team di Nvidia software per sbloccare loro per gli sviluppatori. Le API standard sono ovvi candidati qui - Fermi è stato progettato per i più grandi: DX11 e DirectCompute su Windows, OpenCL e OpenGL per il resto del mondo. OpenCL 1,0 è relativamente nascente, essendo stato solo di recente finalizzato, e DX11 e DirectCompute non sono ancora fuori. Mentre questi sono indubbiamente il futuro per le GPU, OpenCL e DirectCompute mancano molte delle sottigliezze che NVIDIA offre con l'ambiente CUDA e API proprietarie. CUDA è generalmente focalizzata sulla fornitura di supporto a livello di lingua per le GPU. Questo ha senso in quanto sfrutta una certa familiarità da parte degli sviluppatori. Ma la realtà è che le lingue che sostiene CUDA sono varianti delle lingue originali con estensioni proprietarie e solo un sottoinsieme degli impianti di piena del linguaggio. Attualmente, Nvidia ha CUDAfied C e Fortran, e in futuro con Fermi, che avrà una versione di C + +. Marketing di Nvidia è makinig sostiene ridicolo che prima o poi dovrà Python e il supporto Java, ma la realtà è che né la lingua può essere eseguito in modo nativo su una GPU. Un linguaggio interpretato, come Python avrebbe ucciso le prestazioni, e quindi ciò che probabilmente voleva dire è che Python e Java può chiamare librerie che sono scritti per sfruttare CUDA. Pur essendo proprietario, l'ecosistema che Nvidia sta creando per gli sviluppatori CUDA è promettente. Anche se non è il ricco ecosistema di x86, ARM o PPC, è miglia davanti alla OpenCL o DirectCompute. Alcuni degli strumenti includono l'integrazione con Visual Studio e GDB, un profiler visiva, il monitoraggio delle prestazioni migliorate con Fermi, standard e formati binari (ELF e nano). NVIDIA ha anche il proprio set di librerie, che ora può essere aumentata con 3 librerie di terze parti che sono chiamati dalla GPU. Ora che le norme alternative basate, come OpenCL esistono, CUDA è probabile che vedere più lento assorbimento. Molti clienti hanno imparato ad evitare le soluzioni da un'unica fonte, ad esempio IBM con processore Intel x86 chip nel PC originale. Ma CUDA manterrà importanza strategica per Nvidia come un modo per impostare il ritmo per OpenCL e DirectCompute. Conclusioni L'architettura di Fermi è chiaramente un passo verso una maggiore programmabilità e GPU based computing. Vi è una lista di nuove funzionalità, tutti che permetterà Fermi, quando viene rilasciato a farsi strada una maggiore nello spazio relativamente elevato margine di HPC. Alcune delle modifiche più importanti includono l'aggiornamento del modello di programmazione e di memoria, che abbraccia semi-cache coerente e una migliore performance a doppia precisione e la conformità IEEE meglio. E 'chiaro che Nvidia sta facendo un investimento generazione multi-GPU per il computing a spingere in fascia alta, anche se dovremo aspettare fino a prodotti di arrivare a determinare la reception. Poiché non ci sono dettagli sui prodotti, molti aspetti chiave della performance sono sconosciute. La frequenza è probabile che nello stesso intervallo (+ / -30%) come GT200, e il GDDR5 probabilmente eseguito tra il 3,6-4.0GT / s, ma alimentazione e di raffreddamento sono sconosciuti e che potrebbero essere ovunque da 150-300W. La larghezza di banda e la capacità di una soluzione basata DDR3 è sconosciuto. Quindi da un punto di stand delle prestazioni, è molto difficile fare un confronto significativo per GPU di AMD, che è in realtà di spedizione. Le date di spedizione per la grafica e di calcolo prodotti a base di Fermi sono poco chiare, ma Q4 fine sembra essere il più presto possibile, con bassi volumi, mentre il volume effettivo non si verificheranno fino al 2010 - così valutare le prestazioni dovranno aspettare fino ad allora. Forse la dimostrazione più significativi dell'impegno di Nvidia per calcolare è il fatto che una grande quantità di nuove funzionalità non sono particolarmente utili per la grafica. Doppia precisione non è molto importante, e durante la pulizia del modello di programmazione è attraente, è quasi obbligatorio. La vera questione è se Nvidia ha allontanato troppo dal sentiero della grafica, che dipende ancora una volta l'osservazione e l'analisi comparativa dei prodotti leader in tutta AMD, Nvidia e Intel line up, ma sembra che il rischio c'è, in particolare con AMD Graphics messa a fuoco. Queste sono tutte domande importanti a riflettere nelle prossime settimane, e in realtà alimenterà la domanda finale tecnico - il destino di CPU e GPU di convergenza. Sarà la GPU essere messo da parte solo per la grafica, o come sarà il coprocessore in virgola mobile, un elemento essenziale di qualsiasi sistema? Will it get integrata on-die, e in che misura il mercato restano discrete? Queste sono tutte difficili da prevedere, ma è chiaro che Nvidia è il raddoppio sulla GPU come elemento integrante dell'ecosistema PC per la grafica e di calcolo e il tempo ci dirà il resto. |
|
|
|
30-09-2009, 21:56
|
#5867 |
|
Senior Member
Iscritto dal: Feb 2000
Messaggi: 11319
|
Sugli scaffali tra 5 o 6 mesi???
__________________
PC 1 : |NZXT 510i|MSI PRO Z690 A|I5 [email protected] Ghz (Pcore) 4.5 Ghz (Ecore)|AIO ENDORFY NAVI F280|32 GB BALLISTIX 3600 cl 14 g1|GIGABYTE 4070 SUPER AERO OC|RM850X|850 EVO 250|860 EVO 1TB|NVMe XPG-1TB||LG OLED C1 - 55 | PC 2 : |Itek Vertibra Q210|MSI PRO B660M-A|I5 12500|32 GB KINGSTON RENEGADE 3600|ARC A770 LE 16 Gb|MWE 750w| ARC 770 LE 16 Gb Vs RTX 3070 - CLICCA QUI |
|
|
|
30-09-2009, 22:01
|
#5868 | |
|
Senior Member
Iscritto dal: Apr 2003
Messaggi: 16462
|
Quote:
 Direi che e' un ottima notizia per loro, sopratutto considerando come vanno le cose con le cpu.
__________________
MICROSOFT : Violating your privacy is our priority |
|
|
|
|
30-09-2009, 22:01
|
#5869 | ||
|
Senior Member
Iscritto dal: Jan 2007
Messaggi: 25174
|
Quote:
Quote:
__________________
 Ultima modifica di okorop : 30-09-2009 alle 22:04. |
||

|
|
30-09-2009, 22:02
|
#5870 | |
|
Senior Member
Iscritto dal: Apr 2003
Messaggi: 16462
|
Quote:
 a Nostradamus. a Nostradamus.
__________________
MICROSOFT : Violating your privacy is our priority |
|
|
|
|
30-09-2009, 22:03
|
#5871 | |
|
Senior Member
Iscritto dal: Jan 2006
Città: Grosseto
Messaggi: 13656
|
Quote:
__________________
decine di trattative positive su hwupgrade! Configurazione: Gigabyte B550I AORUS PRO AX , AMD Ryzen 5950X, NVIDIA GeForce 4060Ti MSI GamingX 16GB, Silverstone strider 600W 80+ titanium, GSkill Trident 2X8@4000 MHz, Sabrent Rocket 4.0 Plus 2TB, Silverstone SG09, Samsung Gaming Monitor C49RG90 |
|
|
|
|
30-09-2009, 22:04
|
#5872 | |
|
Senior Member
Iscritto dal: Aug 2005
Messaggi: 2052
|
Quote:
|
|
|
|
|
30-09-2009, 22:06
|
#5873 | |
|
Senior Member
Iscritto dal: Apr 2003
Messaggi: 16462
|
Quote:
__________________
MICROSOFT : Violating your privacy is our priority |
|
|
|
|
30-09-2009, 22:06
|
#5874 | |
|
Senior Member
Iscritto dal: Aug 2005
Messaggi: 2052
|
Quote:
|
|
|
|
|
30-09-2009, 22:10
|
#5875 | |
|
Senior Member
Iscritto dal: Feb 2000
Messaggi: 11319
|
Quote:
O davvero vuole spostare il target dei suoi prodotti un pò fuori dal consumer, ma la vedo un pò difficile, o non so che pensare. Intanto da il tempo ad ATI sia di riempire tutte le fascie di mercatoa saturazione sia di tirar fuori un'altra versione single chip potenziata, cosa fatta in passato con la 4890, solo che a questo giro la possibilità di usare SP dormienti è alta, ci sono, stanno li!
__________________
PC 1 : |NZXT 510i|MSI PRO Z690 A|I5 [email protected] Ghz (Pcore) 4.5 Ghz (Ecore)|AIO ENDORFY NAVI F280|32 GB BALLISTIX 3600 cl 14 g1|GIGABYTE 4070 SUPER AERO OC|RM850X|850 EVO 250|860 EVO 1TB|NVMe XPG-1TB||LG OLED C1 - 55 | PC 2 : |Itek Vertibra Q210|MSI PRO B660M-A|I5 12500|32 GB KINGSTON RENEGADE 3600|ARC A770 LE 16 Gb|MWE 750w| ARC 770 LE 16 Gb Vs RTX 3070 - CLICCA QUI |
|
|
|
|
30-09-2009, 22:11
|
#5876 | |
|
Senior Member
Iscritto dal: Jan 2007
Messaggi: 25174
|
Quote:
Intel potentissima e leader in tutto e per tutto, fa sia gpu sia cpu e tra poco usciranno le cpu con gpu integrata, entro il 2011 esce larabbee Nvida: solo knowhow in ambito gaming, migrazione verso utilizzi professionali e accellerazione tramite la gpu prezzi elevati per le proprie vga e presumibile perdita di una fetta di mercato consumer, tentativo di non stagnarsi perchè dopo il 2011 la vedo durissima per l'azienda di santa clara se non trova sbocchi. Secondo me nel mercato professionale potrebbe farcela, ma andando avanti cosi nel mercato desktop avrà veramente pochi sbocchi, dovrebbe comprare una ditta con licenza x86, ma la vedo durissima, anche perchè sia amd sia intel metteranno dentro le proprie configrazioni complete sia nei desktop sia nei portatili tutti i loro prodotti....
__________________
|
|
|
|
|
30-09-2009, 22:14
|
#5877 | |
|
Senior Member
Iscritto dal: Jan 2007
Messaggi: 25174
|
Quote:
comunque non mi stupirei già se l'anno prossimo nvida destinerà molto meno i propri sforzi nell'ambito gaming, dove i profitti son limitati, e che migri verso altri settori di nicchia potendo anche mettere il prezzo delle proprie vga a 3000-4000 euro garantendole grandi profitti....
__________________
|
|
|
|
|
30-09-2009, 22:14
|
#5878 | ||
|
Senior Member
Iscritto dal: Apr 2003
Messaggi: 16462
|
Quote:
Questo e' quanto riportato da Anandtech : Quote:
Fonte : http://www.anandtech.com/video/showdoc.aspx?i=3651
__________________
MICROSOFT : Violating your privacy is our priority |
||
|
|
|
30-09-2009, 22:15
|
#5879 |
|
Senior Member
Iscritto dal: Feb 2002
Città: Discovery
Messaggi: 34710
|
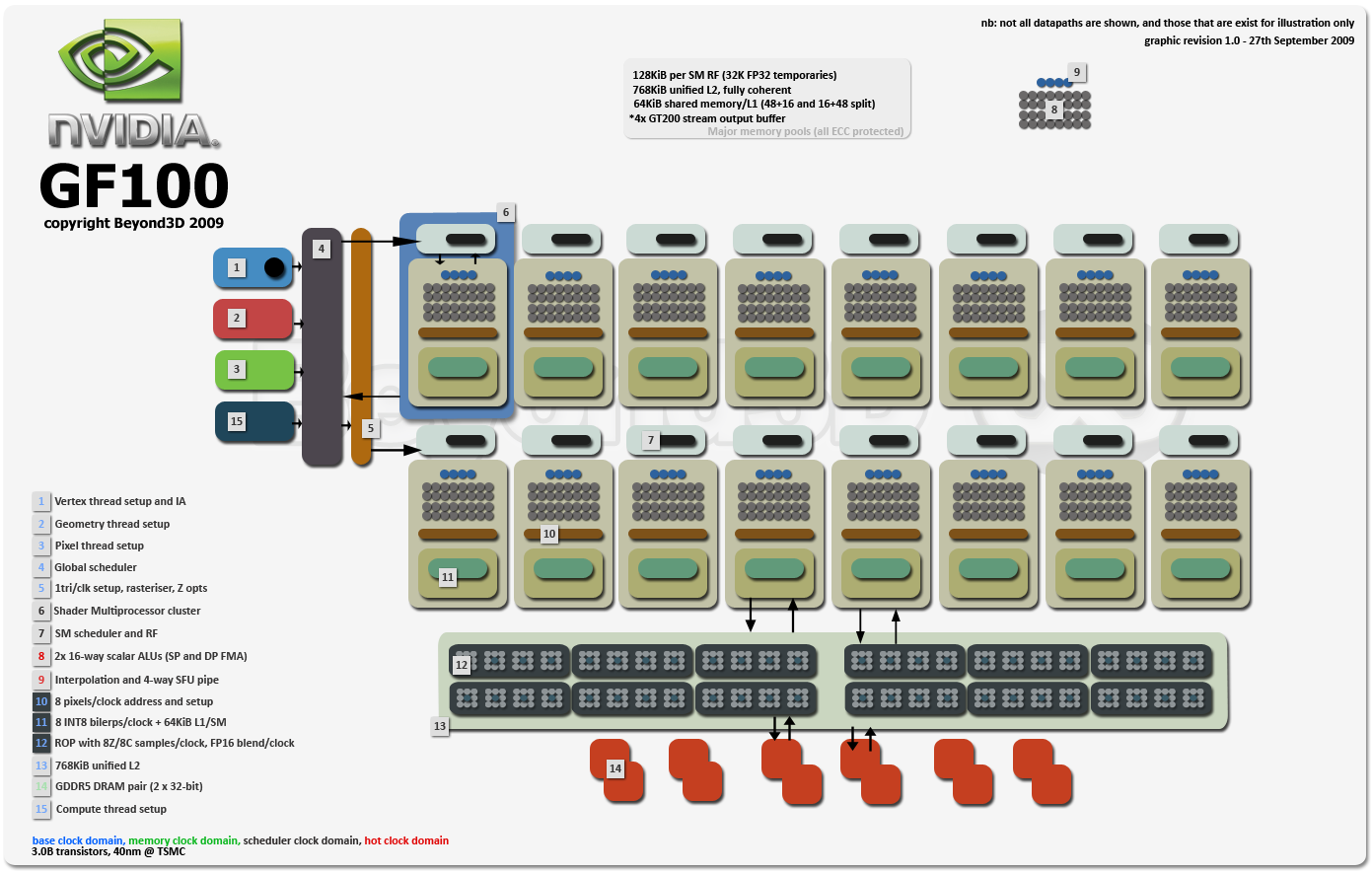
__________________
Good afternoon, gentlemen, I'm a H.A.L. computer. |
|
|
|
30-09-2009, 22:18
|
#5880 |
|
Senior Member
Iscritto dal: Apr 2003
Messaggi: 16462
|
Halduemilauno : ti dispiace rimpicciolire un po' la slide ?
__________________
MICROSOFT : Violating your privacy is our priority |
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 12:05.















