





|
|||||||


|



|
|
 |
|
|
Strumenti |
 12-03-2017, 21:36
12-03-2017, 21:36
|
#841 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6807
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|

|

|

|
12-03-2017, 22:30
|
#842 | |
|
Senior Member
Iscritto dal: Jul 2003
Messaggi: 26775
|
Quote:
Bulldozer era 18-20 (infatti certi sample superavano i 5,0 GHz) e con Ryzen è stato dichiarato di aver fatto il lavoro opposto: riduzione della lunghezza della pipeline (ovvero aumento del IPC e di conseguenza diminuzione delle frequenze operative). Tale dichiarazione viene direttamente da Michael T. Clark, ingegnere capo che ha preso il posto di Jim Keller, ed è impegnato sulle architetture AMD da 24 anni. Da nessuna parte è riportata la specifica ufficiale. Fra i 20 di Bulldozer e i 12 del Athlon64 credo sia lecito immaginarsi un valore nell'intorno dei 14-16 (comunque inferiore sia a Bulldozer che a Kaby Lake). Ultima modifica di MiKeLezZ : 12-03-2017 alle 22:35. |
|
|
|
|
|
13-03-2017, 06:07
|
#843 | ||||||||||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Germania
Messaggi: 26107
|
Quote:
Quote:
E, come già detto da leoneazzurro, quello che s'è visto è un problema generale, che affligge anche le CPU Intel, sebbene in misura minore (mi pare che hardware.fr abbia effettuato dei test appositi). Quote:
Quote:
Quote:
Quote:
Considerato che ARM ha già in casa progetti di GPU, e che unità vettoriali così massicce sono particolarmente complesse da implementare (del clock skew ne parlavi tu tempo fa, se non ricordo male), sarebbe una svolta illogica rispetto a quello che avevi scritto prima. Quote:
La microarchitettura di Ryzen è abbastanza strana / particolare anche andando a guardare dentro il singolo CCX. L'ho fatto di recente, anche con le immagini dei die, e sembra che la situazione sia più complicata. Un core ha, come detto prima, 2MB di cache L3 affiancati, e a cui può accedere con latenza minima. Può anche accedere con la stessa latenza a 1MB di cache L3 dei due core più vicini, e dunque per un totale di 4MB di cache L3. Ma i due vicini hanno un altro MB di cache L3, solo che per accedere a questo la latenza aumenta. Infine, la latenza aumenta anche nel caso in cui si volesse accedere ai 2MB di cache L3 dell'ultimo core del CCX, che si trova all'opposto. Dunque un core riesce ad accedere soltanto parzialmente alle cache L3 dei vari core, e in misura diversa a seconda delle reciproche posizioni. Immagina il lavoro che dovrebbe fare uno scheduler se dovesse anche cercare di tenere conto di tutto ciò, all'interno del singolo CCX. La cosa più sensata da fare in questi casi sarebbe quello di non far muovere del tutto i thread hardware da dove stanno: bloccarli lì fino alla loro fine. Ma immagino che anche questo produrrebbe dei problemi, perché un'applicazione (in particolare i giochi sono un buon rappresentante di questa tipologia) che crei thread/processi non omogenei a cui smistare i vari task, dovrebbe farsi carico personalmente della loro collocazione in una piattaforma come questa, se l'obiettivo è quello di sfruttarla al meglio. Il che crea problemi lato sviluppo, perché non credo che sia piacevole realizzarlo, peraltro con la prospettiva che in futuro le cose possano cambiare (ad esempio, e del tutto teoricamente sia chiaro, AMD potrebbe realizzare un CCX diverso con Zen2, con una cache unificata L3 per CCX, che serva equamente i 4 core), e dunque vanificando il lavoro fatto dagli sviluppatori per supportare questa strana configurazione degli attuali CCX di Ryzen. Da qualunque parti la si guardi (s.o., applicazioni) è una bella gatta da pelare. Quote:
Quote:
Quote:
Fatta eccezione per l'uso intensivo della AVX (e nemmeno di molto), come già detto, ma in questo caso anche a fronte di vantaggi prestazioni che possono essere notevoli. Quote:
Quote:
__________________
Per iniziare a programmare c'è solo Python con questo o quest'altro (più avanzato) libro @LinkedIn Non parlo in alcun modo a nome dell'azienda per la quale lavoro Ho poco tempo per frequentare il forum; eventualmente, contattatemi in PVT o nel mio sito. Fanboys |
||||||||||||
|
|
|
|
13-03-2017, 07:08
|
#844 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6807
|
Quote:
"The basic integer pipeline is 19 stages" Io non parlo mai a vanvera. Se dico che c'è un paper, allora c'è. Se non hai seguito il thread nella sezione processori allora forse ti sei perso il link.
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
|
13-03-2017, 07:11
|
#845 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6807
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
|
13-03-2017, 09:00
|
#846 | |
|
Senior Member
Iscritto dal: Apr 2015
Messaggi: 2533
|
Quote:
"Non sai niente di CPU, hai chiesto quale processore era meglio usare su un socket 7, e vieni qui a fare il gradasso?" (cit.) Piuttosto, ho notato che il commento di Mister D sul FO4 è stato bellamente ignorato   P.s. Concordo con chi dice don't feed the troll
__________________
My PCs: Pentium4 3.2/2GB/GeForce6600, Athlon 3000G/16GB, Phenom II x6 1055T/16GB/GTX750, R7 2700X/32GB/Vega64, R5 3600XT/32GB/RTX4060. DA EVITARE: Alessio.16390 Ultima modifica di fatantony : 13-03-2017 alle 09:05. |
|
|
|
|
|
13-03-2017, 09:01
|
#847 |
|
Bannato
Iscritto dal: Jun 2016
Messaggi: 992
|
Quante pippe ragazzi, ma non dovremmo essere TUTTI contenti che AMD, che partiva da una distanza siderale, è quasi riuscita a raggiungere Intel?
Ne guadagniamo tutti a prescindere. Anche se il 1800x non raggiunge il 700k (e grazie al cazzo che non lo possa raggiungere, era ovvio) però almeno si è avvicinato molto. Non capisco questa guerra all'ultimo frame dove addirittura si taroccano i grafici per far vincere l'uno o l'altro. Mah |
|
|
|
|
13-03-2017, 09:12
|
#848 | |
|
Senior Member
Iscritto dal: Apr 2015
Messaggi: 2533
|
Quote:
__________________
My PCs: Pentium4 3.2/2GB/GeForce6600, Athlon 3000G/16GB, Phenom II x6 1055T/16GB/GTX750, R7 2700X/32GB/Vega64, R5 3600XT/32GB/RTX4060. DA EVITARE: Alessio.16390 |
|
|
|
|
|
13-03-2017, 11:27
|
#849 | ||
|
Senior Member
Iscritto dal: Jul 2003
Messaggi: 26775
|
Quote:
Quello non è un paper ufficiale, quella è una rivista. Speculazioni. The company also made the chip’s integer and floating point processing units more dynamic and accessible to single- and multithreaded workloads. It will take fewer cycles to load operations on the processing units. The units in Bulldozer and its derivatives weren’t as dynamic, widely considered a problem. The designers also sharpened the chip’s execution units. Zen has a distributed scheduler, and it provides visibility to more threads in a window. Bulldozer had a unified scheduler with more complexity. It all begins with branch prediction, which feeds instructions into the 64K 4-way I-Cache. Data flows into decode, which then issues four instructions per cycle to the micro-op queue. Micro-ops are also stored in the op cache, which, in turn, serves frequently encountered ops to the queue. This technique boosts performance and saves power by reducing pipeline stages. As expected, Clark declined to comment on the specific length of the pipeline but noted that the op cache scheme allows the company to shorten it. Clark said that the Zen core has much better branch prediction, and that one of the biggest new features was a large op cache. “In the X86 architecture, there is a variable instruction length and this makes trying to find multiple instructions to get going in the machine a very difficult problem because it is a serial process. To attack that, you build a pretty deep pipeline and you spend a lot of logic, it burns a lot of power. Having seen instructions once come through the pipeline, we now have the micro-ops and we can store them in an op cache and store them so that the next time we hit those instructions, we can just pull them out of the op cache. We can cut stages out of our pipeline when we are hitting the op cache and we can use those high power decoders and not burn all that power as well removing the state we can also deliver more ops into the machine per cycle, too. This is a really great feature that delivers us way more performance and saves us power at the same time.” Quote:
Fra chi compara il 1800X al 7700K downcloccato, a chi spaccia per ufficiali delle indiscrezioni, a chi sogna infattibili CPU Ryzen da 5,0 GHz, a chi non sa riconoscere neppure un esponenziale, a chi non sa montare un dissipatore aftermarket, il lavoro non è dei più facili. Ultima modifica di MiKeLezZ : 13-03-2017 alle 11:38. |
||
|
|
|
|
13-03-2017, 12:09
|
#850 | |
|
Senior Member
Iscritto dal: Sep 2005
Messaggi: 2177
|
Quote:
Quando intel ha introdotto il suo SMT nei coreduo non c'è mai stato bisogno (da parte delle software house) di ottimizzare le varie applicazioni per questa feature? O riconoscevano automaticamente l'SMT? I drivers, bios, di tutte le applicazioni esistenti, siano esse giochi, OS, e quant'altro, a cosa servono? Facevi prima a risparmiare i caratteri con la tua solita uscita "Fonte?".
__________________
__________ Configurazione: Mainboard Gigabyte G1.Sniper A88X (rev. 3.0) ; APU A10 7850K ; HDD Western Digital SATA III WD Blue 1 TB ; Ram Corsair 1866 mhz 16 gb ; OS Seven premium 64 bit |
|
|
|
|
|
13-03-2017, 12:12
|
#851 | |||
|
Senior Member
Iscritto dal: Jan 2007
Messaggi: 5325
|
Quote:
Quote:
Basta pensare ad esempio alle cpu dei vecchi supercomputer Cray. A differenza di Intel ed AMD, c'è da considerare che ARM propone un vero e proprio arsenale di IP adattabili alle esigenze di vari settori e di vari target di consumo e potenza di calcolo, ma il set d'istruzioni "base" ARMv8 ha registri SIMD a 128bit. Non a caso la SVE non è un estensione SIMD tipo SSE, AVX o NEON ma un vero e proprio COPROCESSORE VETTORIALE con lo stesso set d'istruzioni per implementazioni di SVE da 128bit a 2048bit ( è "vector-lenght agnostic" ), tutto un altro paio di maniche insomma. Gli dai le dimensioni dei vettori/matrici da processare e lo SVE se le macina con una granularita interna dipendente dall'implementazione se ho capito bene. Quote:
1) dare (a parità degli altri criteri di selezione) la preferenza di selezione thread sullo stesso core del precedente time slice ed in secondo ordine a quelli adiacenti; 2) non deattivare completamente i due core adiacenti ad un core attivo (perché in tal caso gli accessi alle L3 "di secondo livello" si allungano, se ho capito bene). Non si tratta di sfruttare al 100% le peculiarità dell'architettura delle L3 di Ryzen, ma semplicemente di sfruttarle meglio ( e già ora ha buone prestazioni per il prezzo che ha). Edit: corretto un quote terminato male Ultima modifica di LMCH : 13-03-2017 alle 18:04. |
|||
|
|
|
|
13-03-2017, 12:32
|
#852 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6807
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
|
13-03-2017, 14:02
|
#853 | |
|
Bannato
Iscritto dal: May 2001
Messaggi: 6246
|
Quote:
una APU è HSA, ma condivide il bus con la CPU, ed ha accesso diretto alla memoria e caches. Intel usa un bus interno PCIe, come le soluzioni HSA AMD su scheda video didicata. per quanto riguarda la gestione delle frequenze di CPU e iGPU di una APU è un altro paio di maniche rispetto alle AWX Intel. anche in overclock del 50% la iGPU integrata nella APU è talmente blanda da non risentire di colli prestazionali nemmeno quando i 4 core la CPU sono a 2.4Ghz... non saturano affatto la CPU e le prestazioni calano solo di una piccola percentuale dovuta agli spike... ho una APU, ed arriva a 4.9Ghz con iGPU a 1199mhz, sforando i 140W, ma usandola con la iGPU è totalmente inutile averla fissa a quella frequenza, come è inutile avere un i7-7700K a 5Ghz quando usi la sua iGPU.... diversa la questione della AWX: sono computo diretto, e piu' vanno su in frequenza piu' producono prestazioni... chiamalo overclock o chiamala gestione dei consumi, ma la frequenza della CPU non centra nulla. le AWX consumano, e tanto, ed intel è costretta a limitarne la frequenza. stesso dicasi della temporizzazione caches; se overclocki un i7 verrà aggiunta latenza, perche' la caches non regge e non otterrai prestazioni lineari rispetto alla frequenza, soprattutto negli ambiti in cui la caches la fà da padrona. sono giusto delle precisazioni. Ultima modifica di lucusta : 13-03-2017 alle 14:08. |
|
|
|
|
|
13-03-2017, 14:08
|
#854 | |
|
Senior Member
Iscritto dal: Jul 2003
Messaggi: 26775
|
Quote:
In ogni caso non c'è alcuna analisi da fare: il chief engineer lead architect di Ryzen ha affermato la pipeline sia più corta rispetto a Bulldozer, e di conseguenza Kaby Lake. Tanto basta. p.s. La L3 di Ryzen occupa il 16% di spazio mentre la L3 di Intel occupa il 4,5% di spazio. Anche considerando che la L3 su Ryzen è il doppio rispetto a quella su Kaby Lake, il risultato è che la L3 di Intel è molto più densa e occupa molto meno spazio. Quindi il tuo discorso che su Ryzen i clock siano limitati dal processo produttivo della L3 non fila per nulla (visto che buona parte del suo die è occupata da essa, ed è quella che meno limita la velocità del clock della CPU - inoltre è meno densa e a regola dovrebbe salire meglio). Puoi avere anche 1 miliardo di messaggi ed averne discusso per mesi su qualche thread "aspettando", ma un conto sono le chiacchiere da bar con gli amici che "ve la cantate e ve la sonate", un altro la realtà dei fatti. Ultima modifica di MiKeLezZ : 13-03-2017 alle 15:32. |
|
|
|
|
|
13-03-2017, 14:18
|
#855 | ||||
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6807
|
Quote:
Quote:
Quote:
Sei sicuro? 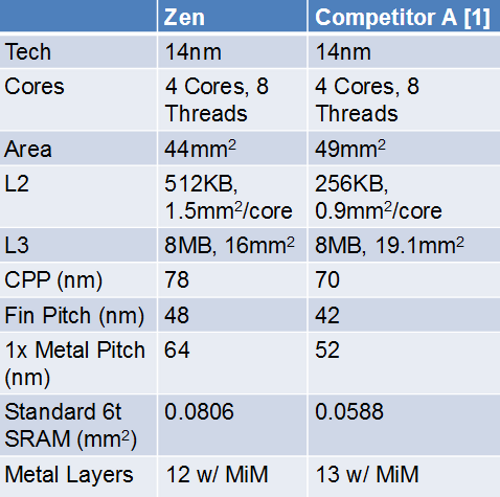  Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
||||
|
|
|
|
13-03-2017, 14:27
|
#856 | ||
|
Senior Member
Iscritto dal: Jul 2003
Messaggi: 26775
|
Quote:
http://www.ece.ualberta.ca/~elliott/...-08/Zhulei.ppt Quote:
Ultima modifica di MiKeLezZ : 13-03-2017 alle 14:41. |
||
|
|
|
|
13-03-2017, 14:34
|
#857 |
|
Senior Member
Iscritto dal: Sep 2005
Messaggi: 2177
|
Scusa ma se la L3 di intel è di 19 mm^2 su 49 mm^2 mi spieghi come fa a essere il 4,5%?
__________________
__________ Configurazione: Mainboard Gigabyte G1.Sniper A88X (rev. 3.0) ; APU A10 7850K ; HDD Western Digital SATA III WD Blue 1 TB ; Ram Corsair 1866 mhz 16 gb ; OS Seven premium 64 bit |
|
|
|
|
13-03-2017, 14:42
|
#858 | |
|
Senior Member
Iscritto dal: Jul 2003
Messaggi: 26775
|
Quote:
 In questo disegno fa 4% e io per gentilezza mi sono tenuto largo. Ultima modifica di MiKeLezZ : 13-03-2017 alle 14:48. |
|
|
|
|
|
13-03-2017, 15:24
|
#859 |
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 10393
|
Ehm, Mikelezz... I dati di Zen riportati nella tabella fanno riferimento al singolo CCX (44mm^2) e quelli di Kaby Lake al complesso core-cache (49 mm^2) e le percentuali sono calcolate rispetto a queste aree. La foto del die a cui fai riferimento contiene parecchie altre cose, tra cui i controller di memoria, I/O e la GPU integrata. Es. Sky Lake e Kaby Lake condividono lo stesso complesso core-cache, e Sky Lake misura circa 122mm^2, con 4 core e GPU (più piccola di Kaby Lake). Kaby Lake nel suo complesso dovrebbe (perchè non è stato confermato ufficialmente) misurare intorno ai 125-140 mm^2.
Ultima modifica di leoneazzurro : 13-03-2017 alle 15:30. |
|
|
|
|
13-03-2017, 15:31
|
#860 | |
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 10393
|
Quote:
|
|
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 11:08.
















