





|
|||||||


|



|
|
 |
|
|
Strumenti |
 05-06-2016, 01:00
05-06-2016, 01:00
|
#2901 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
Quote:
poi non ha mentito (salvo JF che parlava a quanto pare a titolo personale), ma ha fatto slide ridicole... confronti nei giochi con il 980x (quando il 2600k andava meglio e costava molto meno) e in condizioni gpu limited... 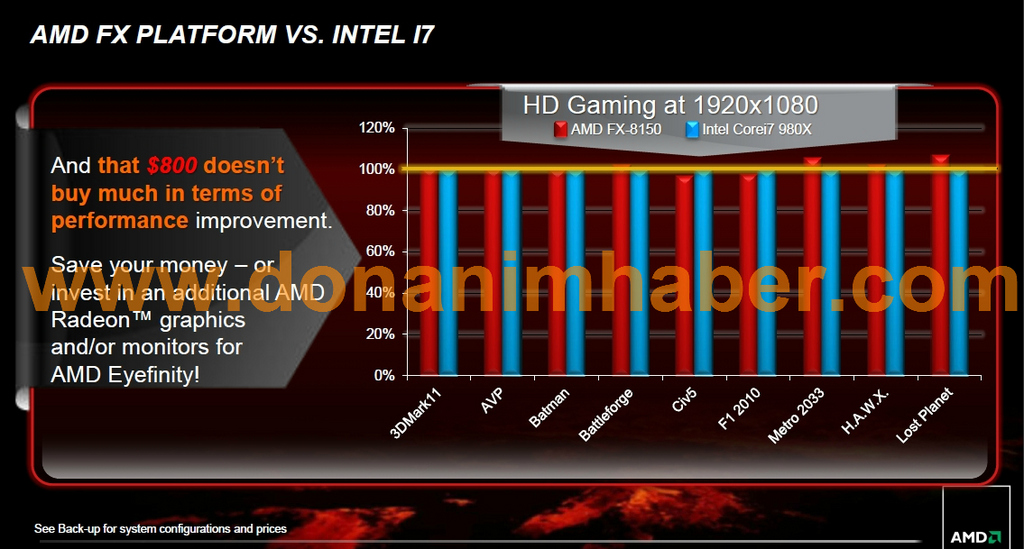
Ultima modifica di tuttodigitale : 05-06-2016 alle 01:10. |
|

|

|
05-06-2016, 03:18
|
#2902 | ||
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32182
|
Quote:
Noi stiamo considerando BD in accoppiata al 32nm, perchè quotando Tuttodigitale, BR, pur sul 28nm (e non 14nm Intel), 15W, di 2,7/3,6GHz per il quad core XV. per paragone Intel aveva su 32 nm 1,8/2,9 (+900MHz ovvero +50% / +700MHz ovvero +25%) 22nm 2,1/3,3 (+600MHz / +300MHz) 14nm 2,4/3,4 (+300MHz / +200MHz). Penso assolutamente che il 32nm Intel sia migliore del 28nm GF, eppure con +50% di frequenza def, pareggerebbe con il cazzuto IPC Intel anche con -50% di IPC ed idem -25% in ST (frequenze Turbo). Se BD fosse un'architettura INEFFICIENTE, come potrebbe su un silicio 28nm GF vs il 14nm Intel reputato il migliore sulla piazza, a essere lì? Allora sarebbe tutto merito del 28nm Bulk GF migliore addirittura del 14nm Intel? Ora... se BD avesse avuto quei famosi ~5GHz turbo, avrebbe avuto una potenza ST del 25% superiore (ovvero più di XV odierno, considerando IPC * frequenza), e un MT ben superiore considerando che avrebbe potuto produrre Komodo X10, e si sarebbe scontrato (allora) con il 4790K 22nm e non con il 14nm di oggi. E' giusto affermare che Broadwell deve l'incremento di potenza al 95% al 14nm? Nel mobile 15W passa da 1,9GHz a 2,5GHz allo stesso TDP (+25%), da un X8 ad un X10 alla stessa frequenza e TDP (+25% di core), paragona questo incremento all'incremento percentuale di IPC e trai le conclusioni. Le affermazioni tipo "cacchio, quanti core mette Intel confronto ad AMD", mo va... se da un 8350 X8 32nm sul 14nm avremmo un XV X16 allo stesso TDP, dimmi cosa c'entra l'architettura (vuoi che XV sia più efficiente di PD di oltre il 100%?) e invece quanto conti il silicio... Fai un X10 3GHz Broadwell nei 140W sul 32nm HKMG ULK Bulk Intel, allora c'era cosa? Un X6 3,2GHz a 140W. Quote:
Guarda i post precedenti... Ad AMD sono serviti più di 8 anni per trovare i dindi per realizzare Zen, oltre che, soprattutto, trovare il silicio (14nm FinFet).
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 05-06-2016 alle 03:58. |
||
|
|
|
05-06-2016, 03:42
|
#2903 | ||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32182
|
Quote:
Quindi anche un BD con -25% di clock avrebbe comunque pareggiato la potenza del Phenom. Fai lo stesso errore delle varie testate pro-Intel, cioè quello di overcloccare il procio Intel alla stessa frequenza (ma def) di un procio AMD, per dimostrare che a parità di frequenza quanto l'ha lungo Intel. Ma che mazza c'entra? Il procio viene venduto ad un determinato TDP e su quel TDP può variare sia l'IPC che la frequenza a seconda dell'FO4 impostato, ma è ovvio che se overclocchi quello che ha per def una frequenza inferiore, sballi il rapporto, guarda a caso, a senso unico pro Intel. Quote:
Senza il silicio qualsiasi architettura non produce nulla di buono, con il silicio anche un'architettura ciofeca può raggiungere potenze alte. Esempio? Prendi il Phenom I (quello sul 65nm). Architettura acerba e gambizzata dal 65nm ignobile. Proiettala sul 14nm, ci fai un X16 a 4GHz (esempio, per fare un confronto). Prendi Broadwell, ha un IPC cazzuto? Bene, mettilo sul 32nm Intel, e che ci fai? Un 6700K a 3GHz? Non considerare quello che scrivo come se dicessi che BD è una tra le migliori architetture, ma ti ripeto che il miglior prodotto è il mix in primis con un ottimo silicio (meglio ancora se in anticipo di miniaturizzazione con gli avversari) ed una architettura così lasciata libera di "esprimersi" aiutata da un numero maggiore di core rispetto agli avversari. Quote:
Quote:
La riuscita di Zen in ST è ESCLUSIVAMENTE legata al PP 14nm FinFet. Poniamo Zen -10% di IPC vs Broadwell (onestamente io oramai ci capisco poco... una volta era -20%, poi ora sembra tra Skylake e Broadwell, ma siccome tra Skylake e Broadwell la differenza è irrisoria, dovrebbe essere a ridosso di Intel). Il procio più potente in ST è il 6700K. Benissimo, il 14nm Intel gli permette i 4,3GHz in Turbo. Zen, con l'FO4 ipotizzato, dovrebbe avere frequenze turbo poniamo del 20% superiori (allo stesso TDP). Mi sembra ovvio che con -10% di IPC ma con +20% di clock, Zen avrebbe una potenza ST superiore. Se poi il PP del 14nm FinFet non fosse dei migliori e concedesse la stessa freuenza del 6700K, 4,3GHz, tu subito diresti che AMD ha fatto ciofeca perchè ha meno IPC di Intel... sarebbe giusto? Pensaci.
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 |
||||
|
|
|
05-06-2016, 07:58
|
#2904 | |
|
Senior Member
Iscritto dal: Sep 2005
Messaggi: 2177
|
@tottodigitale:
Sinceramente ricordo che ipc BD è -30% rispetto a K10 se XV ne guadagna 12 rispetto a kaveri che ne ha solo 3% in più su PD e quest'ultimo ne ha 7 su BD... siamo quasi vicini, ma poi dopo 5 anni buoni. JF parlava sui forum a nome suo per mesi e mesi e amd non si accorge di nulla? Curioso dai @Paolo: si ipc rapportato alla frequenza, le solite cose, infatti io mi riferisco sempre a ipc a pari frequenza e tutto il discorso che ho fatto non fa una piega da quel punto di vista, l'ipc rapportato a frequenza maggiore o minore è l'altro punto di vista che ha portato BD nella mer.a per il pessimo silicio. Ritorniamo sulle solite cose? Ma poi che errori faccio scusa? Ma che mi frega di quello che recensiscono le testate pro intel quando io guardo e parlo di un altra cosa. Ho chiaramente scritto che BD ha perso con la concorrenza per il suo scarsissimo ipc a parità di frequenza, hanno optato per il cmt che da un guadagno elevato in MT a fronte di un basso ipc che lo ha penalizzato sia in ST e sia nell'MT stesso alla fine perché il silicio faceva schifo. Questa è realtà e un dato di fatto e amd è tornata sui suoi passi e non c'entra proprio un bel niente che amd sviluppasse da prima l'smt per conto suo perché conta quello che ha messo su strada non quello che di meglio si è tenuta in casa... se faccio errori a guardare un punto di vista che tiene conto delle lacune contro il vostro che tiene conto di altre cose mi sa che allora non sono l'unico e farli Ogni volta che evidenzio i limiti di BD, gli stessi che hanno portato l'azienda a fare totalmente marcia indietro preferendo un più alto IPC a pari frequenza e per la prima volta su strada l'SMT io sono anti amd e pro intel e sbaglio i miei ragionamenti? Per la proprietà commutativa allora anche AMD stessa sbaglia a ragionare su BD perché ha optato per un diverso approccio dai suddetti punti di vista (ipc e smt). Riguardo il cambio di silicio ci arrivo anche io che zen farebbe il doppio di un 8350 su pp diverso, ma anche lo stesso 8350 andrebbe meglio...e che c'entra con il mio discorso dell'IPC a pari frequenza? Sempre nulla perché qui si vuole difendere a tutti i costi sempre un progetto reso invalido proprio dal basso ipc a pari frequenza. Tanta di quella potenza nei cores int e fpu resa nulla perché volevano pompare le frequenze a 10.000 mhz tanto l'ipc basso lo permetteva... poi si sono accorti che anche il silicio ha la sua importanza. Voglio definitivamente chiudere il discorso IPC a pari frequenza con il fatto rispondendo al tuo "anche qui non hai le idee chiare"... beh se permetti, solo chi ha Zen tra le mani ha le idee chiare non certo io o tu o chiunque qui sul forum. Però, io ho espresso proprio un pelo di timore su una cosa del genere Quote:
Poi riguardo budget amd, non so, mettiti d'accordo con tuttodigitale dove dice che per BD i soldi c'erano in quantità maggiori rispetto a oggi... però come gia scritto altre volte, tu puoi avere un budget ridicolo ma con quel budget mi fai una cpu fatta bene anche se va meno della concorrenza e non ci metti millemila cose dentro sfruttate male (cache pessima e lenta, potenza int e fpu mal sfruttata e basso ipc per compensare tanto con frequenze elevatissime se il silicio regge). Amd non ha recuperato soldi in 8 anni per zen ma questo è stato pagato dai suoi clienti. Qui occorre dare atto a Lisa Su per la sua intraprendenza nelle partnership. Comunque guai a toccare BD qui anche solo per evidenziare una cosa che amd stessa ha negli ultimi due anni sempre dichiarato, a ognuno i suoi errori
__________________
__________ Configurazione: Mainboard Gigabyte G1.Sniper A88X (rev. 3.0) ; APU A10 7850K ; HDD Western Digital SATA III WD Blue 1 TB ; Ram Corsair 1866 mhz 16 gb ; OS Seven premium 64 bit |
|
|
|
|
05-06-2016, 11:36
|
#2905 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Ricapitolo brevemente le differenze: La logica statica usa il doppio dei transistors, compresi i più lenti p-MOS, perciò occupa più area, è più lenta, ma consuma di meno, invece la logica dinamica occupa poco più della metà dell'area (sostituisce i p-MOS con resistenze), usa la metà dei transistor, è più veloce, ma consuma di più e non può essere spenta senza perdere i dati: richiede un clock minimo. I Phenom erano sicuramente a logica dinamica, perchè se ricordate c'era una frequenza minima di 800/1000MHz a seconda del modello. A giudicare dalla dimensione del core Zen stimata, potrebbe darsi che ancora si usi la logica dinamica in AMD... Se qualcuno trova info, per favore le posti... Io penso che Jaguar e i core low power, oltre ad avere transistors RVT e HVT possano essere implementati in logica statica, così da ridurre la potenza dissipata... Non escludo neanche gli Excavator mobile... Per questo con i BR, forse, si ottiene un tale salto di clock: Da RVT a LVT e da logica statica a dinamica... Ma ripeto: non ho trovato info... So solo che i Phenom erano a logica dinamica e i Nehalem a logica statica... Se qualcuno si può spulciare i vecchi paper di Hotchips, magari quelli di Jaguar o Bulldozer, forse è accennato se sono a logica statica o dinamica... Mi interesserebbe saperlo...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|



|
05-06-2016, 11:39
|
#2906 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
05-06-2016, 11:43
|
#2907 | |
|
Senior Member
Iscritto dal: Sep 2005
Messaggi: 2177
|
Quote:
Se BD avesse avuto almeno lo stesso ipc per frequenza del K10 a quest'ora manco esisterebbe Zen e Keller sarebbe rimasto ancora in apple... tutto sommato ci voleva uno scossone in amd. Poi tanto di guadagnato se il silicio 14 nm è buono, davvero.
__________________
__________ Configurazione: Mainboard Gigabyte G1.Sniper A88X (rev. 3.0) ; APU A10 7850K ; HDD Western Digital SATA III WD Blue 1 TB ; Ram Corsair 1866 mhz 16 gb ; OS Seven premium 64 bit Ultima modifica di george_p : 05-06-2016 alle 11:47. |
|
|
|
|
05-06-2016, 12:59
|
#2908 | |||||||||||||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32182
|
Quote:
"Champlain" (45 nm) X4 Model Number Freq. L2 Cache HT Multi 1 TDP Socket Release Date Part Number(s) Phenom II P960 1.8 GHz 4x 512 KB 1.8 GHz 9x 25W S1G4 October 19, 2010 HMP960SGR42GM Phenom II N970 2.2 GHz 4x 512 KB 1.8 GHz 11x 35 W S1G4 January 4, 2011 HMN970DCR42GM Phenom II X940 BE 2.4 GHz 4x 512 KB 1.8 GHz 12x 45 W S1G4 January 4, 2011 HMX940HIR42GM X2 Model Number Freq. L2 Cache HT Multi 1 TDP Socket Release Date Part Number(s) Phenom II P650 2.6 GHz 2x 1 MB 1.8 GHz 13x 25 W S1G4 October 19, 2010 HMP650SGR23GM Phenom II N660 3.0 GHz 2x 1 MB 1.8 GHz 15x 35 W S1G4 January 4, 2011 HMN660DCR23GM Phenom II X640 BE 3.2 GHz 2x 1 MB 1.8 GHz 16x 45W S1G4 May 10, 2011 HMX640HIR23GM Llano (K10 sul 32nm SOI) A4 3320M 2,0/2,6GHz nei 35W A4 3330MX 2,3/2,6GHz nei 45W A8 3550MX 2,0/2,7GHz nei 45W BD Trinity X4 A8-5545M 1.7 GHz 2.7 GHz HD 8510G 450 MHz 554 MHz 19 W DDR3-1333 A10-5745M 2.1 GHz 2.9 GHz HD 8610G 533 MHz 626 MHz 25 W DDR3-1333 A10-5757M 2 (4) 2.5 GHz 3.5 GHz 2 × 2 MB HD 8650G 384:24:8 533 MHz 720 MHz 35 W DDR3-1600 FP2(BGA) BD 32nm VS K10 45nm, vede BD, allo stesso TDP, ad avere frequenze turbo pari agli X2 K10, ma in def X4 anzichè X2. Verso gli X4 la frequenza operativa è percentualmente superiore rispetto alla perdita di IPC. Tutto questo ottenuto con Trinity che buona parte del TDP è destinato all'IGP, e senza scomodare Richland, sempre PD, sempre 32nm SOI, che offre frequenze maggiori. Il confronto BD 32nm vs K10 32nm l'abbiamo con Llano... a parità di Watt Trinity ha 2,5GHz vs Llano 2GHz (+500MHz/+25%), Turbo 3,5GHz vs Llano 2,6GHz (+900MHz/quasi +40%). Il rapporto IPC/frequenza è tutto a favore di BD, e sempre con Trinity e non con Richland. Non ho preso SR e XV e tantomento XV-BR perchè chiaramente il K10 sembrerebbe un Sempron X1... però se ipotizzassimo una evoluzione dell'8350 pari a quella di Trinity-BR, un Thuban sembrerebbe un X2... Quote:
Quote:
Ricordati l'incremento che ha avuto il 45nm passando dalla versione liscia all'implementazione low-k, da X4 125W si passò a X6 125W. Sulla base di questo chiunque ipotizzava che il passaggio dal 45nm al 32nm e l'aggiunta dell'HKMG avrebbe fatto meraviglie. Ricordati che la stessa GF ha sborsato un tot di dindi rilevando le FAB AMD proprio su questa base... se avesse saputo a priori il PP 32nm SOI, forse manco l'avrebbe acquistata e comunque se sì, ad un tot di meno. Prova a pensare in questi anni quanto avrebbe guadagnato tra un 32nm SOI ottimo (e quindi BD desktop/mobile/server), il passaggio praticamente gratis al 22nm SOI (il SOI permette il passaggio a miniaturizzazioni maggiori conservando i macchinari e cambiando solamente la parte litografia) e quant'altro. Quote:
Il K10 a portarlo a IPC Intel quanto costava? Prendere il K10, modificarne l'FO4 più ovviamente la parte I/O e quant'altro, sarebbe costato molto meno. Se poi l'FO4 17 sul 32nm SOI non ha portato le frequenze sperate, è ovvio che il rapporto IPC * frequenza NON PUO' DARE il risultato previsto, ma tu dicendo che il problema è l'IPC in BD, è scontato che se AMD avesse saputo di arrivare solamente a 4GHz def, volente o nolente avrebbe aumentato l'IPC per aumentare le potenze, ma è ovvio che bisogna considerare che da 4GHz a 5GHz c'è una differenza del 25% e su questa base concordi o no che a 5GHz servirebbe un IPC del 25% inferiore per ottenere le stesse potenze ma con frequenza 4GHz? Poi aggiungici pure questo... il 32nm SOI in sè e il mancato pssaggio al 22nm, hanno penalizzato molto di più AMD nell'MT di quanto lo abbia fatto in ST, perchè un aumento dei core allo stesso TDP avrebbe comunque permesso ad AMD di ricreare la medesima situazione Phenom II X4 e Thuban vs Intel, dove il K10 aveva una performances ST inferiore ma il Thuban, grazie a +2 core, otteneva più potenza MT rispetto agli X4 Intel. Se guardi la differenza in MT tra un 8350 32nm ed un 6700K 14nm, personalmente non la conosco perfettamente, quindi non posso scrivere un dato, ma un Komodo X10 già previsto, avrebbe aumentato già del 25% l'MT di un PD 8350, aggiungici l'incremento da PD a XV, aggiungici il passaggio al 22nm, è SCONTATO che BD avrebbe ottenuto un MT ben superiore agli X4+4 Intel, e quindi il discorso IPC sarebbe stato marginale. Quote:
Quote:
Quote:
Tieni presente che il 32nm SOI produce 125W con 1,2 milioni di transistor, il 5960X ne ha più del doppio (2,5 milioni) e ne produce 140W. Zen è X8 +8, quindi reputerei che non si doscosterà granchè dal numero di transistor di un 5960X, ma sul 32nm a parità di FO4 di BD, è ovvio che Zen X8+8 andrebbe ridimensionato al TDP/transistor permesso dal 32nm SOI, ovvero meno della metà (8350 vs 5960X), quindi che ci scappa fuori? Un X4 con meno frequenza? Non avrebbe senso. Sono pagine che discutiamo che Zen debba avere una potenza più che doppia di un 8350 perchè il 14nm consentirebbe un XV X16, e XV è circa il 15% (medio penso) migliore di PD, quindi un XV X16 sarebbe un PD X18 circa e Zen, per giustificare i soldi in più spesi, deve partire ALMENO da quel punto. Quote:
Ipotizziamo un XV X16 vs un 5960X. La potenza ST di un 5960X è superiore a quella di un 8350 PD, ma lo sarebbe ancora verso un BR? Un 5960X va il doppio di un 8350? Ma un XV X8 andrebbe di più di un 8350... quindi mi pare ovvio che un XV X16 andrebbe di più del 5960X. Quello che voglio dire, è che BD offerto ad una quantità di moduli pari al numero di core + SMT Intel, non ci vedo alcuna differenza tra CMT o SMT, soprattutto considerando che Intel riduce drasticamente le frequenze con l'aumentare dei core. Poi è ovvio che ad un X16 CMT se Intel mi schiaffa un X32+32 SMT non ha più senso il mio discorso. Quote:
Quote:
Il PIV doveva triplicare le frequenze raggiunte per essere alla pari, noi parliamo del +25% come frequenza per PD... da +25% a +333% c'è differenza? E' ovvio che Intel ha dovuto cancellare in fretta e furia il PIV, come è ovvio che se AMD ha prodotto BD per 6 anni senza cambiarlo o trasferire il K10, un motivo ci sarà... Quote:
E' ovvio che va inserito anche il discorso +80% 2° TH CMT vs +30% SMT, perchè se Intel ha +65% di IPC, è ovvio che AMD non può pensare a +65% di frequenza... ma è altrettanto ovvio che se il core BD avesse lo stesso IPC di quello Intel, Il CMT non darebbe 130 come l'SMT ma almeno 180. Quote:
Se l'FO4 17 è il valore che IBM inquadra come migliore, questo vuole dire UNICAMENTE che un determinato silicio con un PP nel range frequenza "normale", vedra la curva TDP/frequenza migliore con FO4 17, ma questo comunque si deve rapportare al PP silicio su cui si applica. Quote:
Paragonando alla F1, i team competitivi lo sono quando alle spalle ci sono soldi, poi può capitare il miracolo di una macchina riuscita bene (ovvero il progetto), ma necessita pur sempre del motore idoneo (silicio) per essere competitiva. Quote:
Quote:
Estrapolando la concorrenza, io in un 8370 ci vedo il mondo di più (seppur ancora PD e non BR) di un Thuban 1100T, è ovvio che per me BD è sopra un K10... al più mi potrai giudicare filo-BD più che filo-AMD
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 |
|||||||||||||||
|
|
|
05-06-2016, 13:31
|
#2909 |
|
Senior Member
Iscritto dal: Sep 2005
Messaggi: 2177
|
Amd pubblicizzava così tanto il suo cmt da preferirlo all'smt perché naturalmente un approccio cmt comprende 8 cores reali per 8 threads, l'smt per 8 threads lavora con soli 4 cores reali. Normalissimo che otto cores fisici rendano molto più di 4. Ma è altrettanto normalissimo che il consumo di otto cores non può essere paragonato a quello di quattro cores, diciamo a parità di transistor o di features ecc. Vedi intel che consuma un botto con 8 e 10 cores ed è costretta a ridurre la frequenza. Ti do ragione su BD potentissimo a 6 GHz, ma relegando così tanto la potenza alla frequenza ti seghi le gambe nel caso il silicio sia schifoso, questa ormai è storia A BD gli hanno segato 30% di ipc rispetto alla precedente architettura perché Meyer si è affidato troppo alla frequenza di funzionamento. In più aggiungo, nel CMT raggiungevi l'80% delle prestazioni di un core, quindi sia in ipc sia in MT hai penalizzato una architettura a prescindere dal silicio. Il silicio si è mostrato schifoso e woilà, il gioco è fatto Avesse mantenuto lo stesso ipc e guadagno cmt che ha ora XV da subito, stai tranquillo che anche a 3600 mhz BD avrebbe sbaragliato la concorrenza. Il mio discorso è sempre lo stesso, e ho iniziato solo con una frase... finiamo sempre con millemila post E ribadisco, almeno con Zen hanno aumentato un pò l'ipc, male che vada il silicio amd fallirà, ma almeno la colpa si può attribuire a gf 
__________________
__________ Configurazione: Mainboard Gigabyte G1.Sniper A88X (rev. 3.0) ; APU A10 7850K ; HDD Western Digital SATA III WD Blue 1 TB ; Ram Corsair 1866 mhz 16 gb ; OS Seven premium 64 bit |
|
|
|
05-06-2016, 15:06
|
#2910 | |
|
Senior Member
Iscritto dal: Oct 2011
Messaggi: 2212
|
Quote:
Anche se sono superconvinto che nessuna di queste due tipologie di utenza resterà insoddisfatta veramente, in quanto credo profondamente che i produttori di mobo si inventeranno qualche controller/chip di gestione "X_funzione" (vrm o altro) da mettere sulla mobo (magari solo nelle top di gamma) per poterci mettere a sua volta un dissipatore carino da vedere, fare le solite mobo cazzute (per farle costare di più con features iper-forzate) e continuare ergo a fare le ATX. Ma mi sembra più che giusto che sia cosi, anche i player di mobo devono poter campare, altrimenti davvero finirà che restaranno due player (se tutto va bene). Siccome cosi non sarà, perchè come ci insegna la storia dell'informatica: "In informatica tutto si rivoluziona, tutti gli approcci tecnici subiscono cambiamenti strutturali a architetturali, ma nessun approccio logico-filosofico informatico cambia mai veramente". Ne approfitto per salutare tutto il thread (manco da tantissimo in write_mode, ma sono sempre vigile in read_mode).
__________________
*[email protected](1.38v) - Msi 990fxa-gd80 - Geil evo corsa 4x4gb cl9 1866mhz - Sapphire hd7870 - Wd 2x1tb - Corsair gs800 - Cosmos II *Altre cpu's: Fx-8120/A10-5800k/1055t/965Be/5400+/i920/E5400 - Os: Xubuntu 16.04.4 "xenial" - Debian_jessie 8.0 - Slackware 14.2 - gentoo linux - Kali Linux 2018.2 Catalyst 13.12 problemi con i vecchi OpenGL Ultima modifica di shellx : 05-06-2016 alle 15:21. |
|
|
|
|
05-06-2016, 15:19
|
#2911 | |||||||||||||||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
I POST di BJT2
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Ultima modifica di tuttodigitale : 05-06-2016 alle 15:48. |
|||||||||||||||
|
|
|
05-06-2016, 16:00
|
#2912 |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Bel riassunto!
Mi sono dimenticato cosa volevo scrivere...  Comunque il riassunto mi ha fatto venire in mente che una latenza cache di 4 cicli può voler dire basso FO4, perchè altrimenti sarebbero stati 3 cicli...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
05-06-2016, 16:05
|
#2913 | |||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
Quote:
a 3 GHz cinebench k10 0,9 PD 0,79 differenza ipc PD->K10 15%, ovvero la distanza che lo separa da XV... Quote:
Le frequenze turbo dal passaggio a Nehalem a SB, sono passate da 3.46 a 3,9GHz....+13% (e tdp ridotto a 95W) da thuban a BD, sono passate da 3,8 a 4,2GHz, +11%: il vantaggio dell'architettura è stato divorato dal processo CMT e basso ipc non sono collegati...e neppure SMT = alto ipc (le architetture power e netburst ad esempio)... Quote:
Ultima modifica di tuttodigitale : 05-06-2016 alle 16:47. |
|||
|
|
|
05-06-2016, 16:57
|
#2914 | |
|
Senior Member
Iscritto dal: Sep 2005
Messaggi: 2177
|
Quote:
Però tu mi porti sempre il PD che non è l'8150. Il mio discorso parte sempre dal primo BD ovviamente. Quindi togliamo un ulteriore 7% che è l'ipc che separa PD da BD. Come si comporta il turbo nel ST? E' una cosa che non ho mai capito, all'epoca dei phenom le cpu intel risultavano più avanti per il turbo. E l'SMT non ho ben capito se entra in gioco anche nel ST. Allora, rapportandolo al MT io ricordo sempre il punteggio di 6 in cinebench dell'epoca (versione 11,5) ottenuto sia con l'8150 (a 3.6 GHz) sia col phenom X6 (a 3.3 GHz). La differenza dei cores è del 33% a favore di BD e in aggiunta questo nel multicore perde un 20% rispetto al 10% che hanno sempre avuto gli athlon. P.s.: cosa intendi per troughput?
__________________
__________ Configurazione: Mainboard Gigabyte G1.Sniper A88X (rev. 3.0) ; APU A10 7850K ; HDD Western Digital SATA III WD Blue 1 TB ; Ram Corsair 1866 mhz 16 gb ; OS Seven premium 64 bit Ultima modifica di george_p : 05-06-2016 alle 17:01. |
|
|
|
|
05-06-2016, 17:31
|
#2915 | |||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4392
|
Quote:
ma la frequenza turbo sembra essere ancorata a 3,9GHz 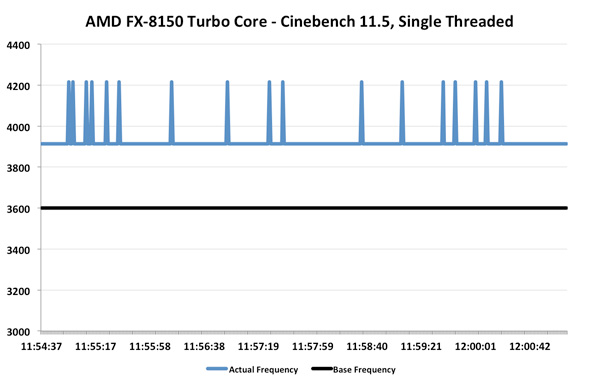 quindi la prestazione a 3GHz in ST sembra essere identica.. miglioramenti più consistenti in MT (5%) Quote:
BD a parer mio è buono proprio per aumentare le prestazioni nel ST... infatti non è che trinity sia sto gran fenomeno paragonato a llano nel MT. (ma non è certo un demerito, gli opteron k10 erano molto buoni). Quote:
Ultima modifica di tuttodigitale : 05-06-2016 alle 17:48. |
|||
|
|
|
05-06-2016, 21:39
|
#2916 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32182
|
http://www.hwupgrade.it/news/cpu/amd...tel_62977.html
Da questo articolo, non è che trapelano cose nuove, ma c'è una frase che mi fa riflettere, sempre se è stata scritta in modo non semplicistico. "Zen è un progetto del tutto nuovo; realizzato con processo produttivo 14 nm FinFET, la nuova architettura sarà alla base inizialmente dei processori desktop AM4 Summit Ridge, cui seguiranno le APU e gli Opteron per il mondo server". Come mai 1° Zen esclusivamente desktop? Io ipotizzo che AMD abbia agito in modo da escludere problemi stile BD/32nm SOI, cioè frequenze più basse delle aspettative, ed associando l'obiettivo di rendere Zen potente quanto Intel a frequenze def (presumo =>3GHz confrontato con gli i7 =>X8) e magari anche poter arrivare a frequenze turbo =>4,3GHz nel caso di confronti sul 6700K. Su questa base direi che AMD abbia impostato Zen per la massima frequenza raggiungibile, utilizzando transistor veloci a scapito di un TDP inferiore, non implementare HDL e quant'altro di simile. Raggiungere con l'ES 3GHz, io credo che sia stato positivissimo per AMD, a tal punto da iniziare l'implementazione di tutto quanto possibile per diminuire il TDP perchè comunque le frequenze erano soddisfacenti. I requisiti server e mobile (in cui possiamo pure includere gli APU), cercano il TDP più basso a scapito delle prestazioni, il mobile per aumentare l'autonomia, l'Opteron perchè comunque ottenendo l'efficienza maggiore TDP/frequenza a core, la potenza la ottiene aumentando il numero dei core. Come dire... Zen 1° versione ottica maggior clock, 2° versione HDL e quant'altro.
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 05-06-2016 alle 21:45. |
|
|
|
05-06-2016, 23:17
|
#2917 | |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24171
|
Quote:
__________________
AMD Ryzen 9600x|Thermalright Peerless Assassin 120 Mini W|MSI MAG B850M MORTAR WIFI|2x16GB ORICO Raceline Champion 6000MHz CL30|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Lexar EQ790 2TB (Games)|1 M.2 NVMe Silicon Power A60 2TB (Varie)|PowerColor【RX 9060 XT Hellhound Spectral White】16GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case Antec CX700|Fans By Noctua e Thermalright |
|
|
|
|
06-06-2016, 00:09
|
#2918 | |
|
Senior Member
Iscritto dal: Mar 2006
Città: Rovigo
Messaggi: 1204
|
Quote:
Spulciando google immagini do trovato gli screen di cpu-z di diverse apu, queste sono le frequenze minime: a10 8700p-> 1300mhz a10 7850k -> 1700mhz a10 7800 -> 1400mhz a8 6600k -> 950mhz a10 6800k -> 1000mhz Il minimo si ha avuto con Piledriver mobile
__________________
CASE: Pure Base 500DX nero | MB: Msi Mag B550 Tomahawk | CPU: AMD Ryzen 5 3600 | COOLER: Noctua NH-C14S | PSU: XFX Pro Series 450W | RAM: Crucial Ballistix 2x8gb 3600mhz C16 | SSD: WD BLACK SN850 1 TB | Samsung 850 Evo 500GB | HDD: WD Green 500GB | Seagate Barracuda ST4000DM004 VGA: XFX Radeon RX 580 GTS XXX Edition | OS: Windows 11 STEAM Ultima modifica di el-mejo : 06-06-2016 alle 00:12. |
|
|
|
|
06-06-2016, 01:44
|
#2919 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32182
|
AMD avrebbe dato la conferma ufficiale (Lisa Su) che entro le 2 prox settimane tutti i produttori avrebbero gli ES di Zen. Ma qualcuno per la rete ha aggiunto ES pre-produzione.
La differenza tra un ES ed un ES pre-produzione sta nel fatto che l'ES rimane un die a sè con uno stadio di messa a punto indecifrato... magari con parti disattivate, addirittura se richiedesse uno step ulteriore, ci vorrebbero altri 6 mesi, mentre l'ES pre-produzione è nella fase ultimale con tutte le sue parti attive e funzionanti, praticamente ha più una funzione di affinamento del processo con un die che non necessita più di interventi se non di aggiustamenti marginali, quindi la partenza della produzione volumi potrebbe richiedere 1 giorno come 1 mese, ma comunque imminente. La notizia degli ES è accompagnata anche da una voce, attendibile o meno non lo so, che AMD aspetterebbe a dare il via alle AM4 perchè vorrebbe avere la certezza che qualsiasi mobo AM4 possa montare BR e successivamente Zen. Se fosse vera, di BR so che 65W c'è, non so se arriva pure a 95W, ma confermerebbe Zen 95W, perchè troverei illogico obbligare i produttori di mobo a supportare 140W quando magari uno ci monterebbe un BR 65W...
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 06-06-2016 alle 09:14. |
|
|
|
06-06-2016, 02:20
|
#2920 |
|
Senior Member
Iscritto dal: Jun 2005
Città: Vitória(ES), Brasile
Messaggi: 8152
|
Potremmo avere:
- BR 65W - Zex x6 95W (o qualcosa meno) - Zen x8 bloccato 95W - Zex FX 125W Quindi mobo speciali per processori speciali.
__________________
Se la vita ti da limoni ... Spremili in occhio a qualcuno e corri! |
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 13:53.















