





|
|||||||


|



|
|
 |
|
|
Strumenti |
 09-03-2010, 15:22
09-03-2010, 15:22
|
#21821 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Ultima modifica di yossarian : 09-03-2010 alle 15:32. |
|

|

|
09-03-2010, 16:06
|
#21822 | |
|
Member
Iscritto dal: Oct 2006
Messaggi: 102
|
Quote:
2) Giusto, ma non mi sembra una perdita di efficienza significativa come ordine di grandezza rispetto agli altri problemi di cui si sta parlando 3) L'elaborazione ad alto livello all'interno del frame è sempre seriale. Visto però che per ogni frame ci sono migliaia di vertici e pixel e che la GPU non ha risorse per elaborarli tutti contemporaneamente, è normale che non si faccia tutto in sequenza, ma "localmente" ad ogni vertice/pixel le operazioni che lo riguardano scorrono ovviamente secondo la pipeline che hai prospettato o cmq quella decisa dal programmatore tramite il codice caricato negli shader. Non vedo che centra con il discorso dell'efficienza tra pixel/vertex e shader unificati. Anzi, se si eseguisse brutalmente in maniera sequenziale ogni pixel dell'interno frame allora si vedrebbe un vantaggio dell'architettura unificata ancora maggiore, visto che mentre la GPU a shader separati deve eseguire tutti i calcoli relativi ai vertex shader finchè non avesse finito tutti i vertici, i pixel shader starebbero con le mani in mano, cosa che ovviamente non accadrebbe con gli shader unificati. Ovviamente l'efficienza generale farebbe comunque schifo in entrambi i casi visto lo spreco di tutto il resto dell'HW per gran parte del tempo... Che ti devo dire, secondo me è meglio avere 544 sp generici che 512+T, sempre se gli ordini di grandezza della perdita di efficienza sia tipo quella prospettata negli esempi. Bisogna tenere conto che ogni sp guadagnato è oro, visto il tempo per cui può essere impiegato all'interno dell'elaborazione del frame rispetto a quanto vengano utilizzate le unità di tessellazione. E' come se un programnmatore avesse scritto un programma che per eseguire un dato calcolo ci impiega 10 secondi suddivisi in questo modo: 1 secondo tramite la funziona A e 9 secondi tramite la funzione B. E' inutile che si sprema il cervello per ottimizzare fino all'inverosimile la funzione A; è la B che utilizza la maggior parte delle risorse. Siccome le fasi di hull e domai occupano una piccola parte del tempo per frame è molto meglio migliorare anche di poco le prestazioni del resto (avere maggiori sp) che dedicarsi a migliorare queste. Sono confronti che per chi progetta (e quindi ha l'hardware in mano con latenze e balle varie davanti al naso) sono abbastanza semplici da fare, se hanno optato per questa scelta mi sembra evidente che, almeno per come li avrebbero implementato loro (NVIDIA) hull e domain, la scelta è quella prestazionalmente migliore. Poi se ATi ha fatto Hull e domain moooolto più veloci di quello a suo tempo previsto da NVIDIA, peggio per loro... La mia è solo un'osservazione sull'architettura a livello generale, per far capire che "emulare" quelle due fasi non vuol dire togliere risorse alle altre, anzi, è il contrario. |
|
|
|
|
09-03-2010, 16:09
|
#21823 | |
|
Senior Member
Iscritto dal: Apr 2008
Messaggi: 3127
|
Quote:
__________________
Case: Stacker 830 nVidia Edition-Ali: Corsair HX1000W-Mobo: Asus R2E-CPU: i7 920 3,80 Ghz-Dissi: NH-U12P SE-Ram: Dominator 6GB 1600Mhz CAS8-VGA: Zotac GTX480 2-Way SLI-HDD: 2x150GB Raptor Raid0;1TB WD10EADS-Schermo: Acer GD245HQ+nVidia 3D Vision  -SO: Win8 Pro x64-Mouse: Razer Mamba-Cuffie: Sharkoon X-Tatic 5.1 Digital-Gaming: G13-G25-Rumble Pad 2, Xbox360 controller -SO: Win8 Pro x64-Mouse: Razer Mamba-Cuffie: Sharkoon X-Tatic 5.1 Digital-Gaming: G13-G25-Rumble Pad 2, Xbox360 controller
|
|
|
|
|
09-03-2010, 16:31
|
#21824 | |
|
Bannato
Iscritto dal: Dec 2003
Città: Monteveglio(Bo)
Messaggi: 10006
|
Quote:
Un gioco ha modelli da 20000 poligoni e questi vengono creati con la normale rasterizzazione. Con la tesselation attiva invece al principio ci sono modelli con 2000 poligoni e la tesselation li porta a 20000 poligoni. Mi sembra di avere capito che intendi questo e protrebbe portare anche ad un aumento delle prestazioni. Se mi sbaglio correggimi naturalmente. |
|
|
|
|
09-03-2010, 16:59
|
#21825 | ||||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
Quote:
Il vantaggio degli shader unificati è proprio che grazie alla possibilità di usare la stessa unità per più compiti (e grazie alla presenza di registri costanti di diverso tipo, ovvero, in pratica tutti quelli che erano presenti sia sulle unità di pixel che di vertex e geometry shader) c'è la possibilità di fare eseguire, a quella stessa unità (o meglio, a quel gruppo di unità di quello specifico cluster) il tipo di calcoli che mi servono o mi fanno comodo in quel momento; il che significa che posso farli lavorare su dei dati geometrici e, immediatamente dopo, se non c'è dipendenza, su dei pixel. Se mi metto a far eseguire, al contrario, prima VS, poi HS, quindi DS, GS e, infine, PS, torno allo schema a shader dedicati, localmente o globalmente non ha importanza o, quanto meno, ha un'importanza relativa. Quote:
RV870 ha 1600 alu e fermi 512 impegnate a fare altro. Istante t1, parte la tessellation; RV870 ha 1600 alu impegnate a fare quello che stavano facendo prima ed, in più, un'unità dedicata alla tessellation; fermi ha n alu impegnate a fare tessellation e 512-n impegnate a fare quello che stavano facendo prima. Questo significa sottrarre risorse. In RV870 il tessellator può diventare il collo di bottiglia? In fermi anche, direttamente o indirettamente (perchè provoca il verificarsi di colli di bottiglia altrove). Controprova: attivi physx, il frame rate cala anzi, se l'elaborazione è particolarmente pesante, crolla. Questo perchè n alu stanno facendo altro. Ulteriore controprova: il MSAA su R600 con il resolve via shader. Anche in questi casi non parliamo di emulazione ma il risultato è lo stesso Non vedo per quale motivo il tessellator su fermi debba fare eccezione. Inoltre, sei partito da un altro assunto sbagliato, ovvero che la parte del leone la faccia il tessellator. Niente di più lontano dalla realtà. Il tessellator lavora a 16 bit in virgola fissa ed esegue i suoi calcoli molto velocemente. In molti casi sono i DS, che si occupano anche di fare dispplacement mapping, ad occupare la maggrior parte del tempo (questo significa tenere bloccate delle unità generiche ocn delle chiamate a texture anche per le operazioni geometriche) Ultima modifica di yossarian : 09-03-2010 alle 17:54. |
||||
|
|
|
09-03-2010, 17:07
|
#21826 |
|
Senior Member
Iscritto dal: Sep 2006
Messaggi: 27924
|
si può fare un paragone (molto con le pinze) tra la potenza eleborativa dell'unità dedicata presente in rv870, e gli sp di fermi? molto teoricamente, quanti sp nvidia occorrono per arrivare alla stessa potenza dell'hw dedicato nelle ati?
__________________
CPU: Ryzen 5700x COOLER: Noctua NH-D15S MOBO: Gigabyte b550 Professional RAM: 4x8 @3600 GPU: XfX Qick319 Rx6700XT  HD1: Sk Hynix Platinum p41 2TB HD2: Sabrent Rocket 1TB MONITOR: Xaomi Mi Curved 34" HD1: Sk Hynix Platinum p41 2TB HD2: Sabrent Rocket 1TB MONITOR: Xaomi Mi Curved 34"
|
|
|
|
09-03-2010, 17:26
|
#21827 |
|
Senior Member
Iscritto dal: Feb 2002
Città: Discovery
Messaggi: 34710
|
la GTX470 in vendita in Cina per l'equivalente di 366$.
http://diy.yesky.com/vga/259/11163259.shtml
__________________
Good afternoon, gentlemen, I'm a H.A.L. computer. |
|
|
|
09-03-2010, 17:34
|
#21828 | |
|
Senior Member
Iscritto dal: Nov 2005
Città: Zena
Messaggi: 23268
|
Quote:
__________________
Lian Li 011 Air Mini - Intel i5 12600k cooled by Cooler Master MasterLiquid PL240 Flux - Asus Prime Z690-P D4 - 4x16GB Corsair Vengeance 3600Mhz - MSI RTX 3070 Ventus 3X OC - Samsung SSD nvme 980 PRO 1TB - Samsung SSD 980 EVO 1TB - Corsair RM750x - LG 27GP850 - Corsair K70 - Evga X15 - Corsair HS80 |
|
|
|
|
09-03-2010, 17:35
|
#21829 | |
|
Senior Member
Iscritto dal: Feb 2002
Città: Discovery
Messaggi: 34710
|
Quote:
__________________
Good afternoon, gentlemen, I'm a H.A.L. computer. Ultima modifica di halduemilauno : 09-03-2010 alle 17:57. |
|
|
|
|
09-03-2010, 17:44
|
#21830 | ||
|
Senior Member
Iscritto dal: Oct 2001
Messaggi: 14739
|
Quote:
Abbassare il dettaglio geometrico di base significa avere una pessima grafica sulle schede che non supportano tessellation (la stragrande maggioranza ancora per un bel po'). Per questo mi pare plausibile che il dettaglio di partenza sarà comunque alto, e la tessellation venga utilizzata per aggiungere un "superdettaglio" su alcuni modelli, appesantendo nel complesso la scena. Quando poi le schede dx11 saranno più diffuse e magari ci saranno le nuove consolle, allora penso si possa fare un uso più "corretto" della tessellation. Quote:
|
||
|
|
|
09-03-2010, 17:48
|
#21831 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Battute a parte, è evidente che lo spazio occupato dal tessellator è inferiore rispetto a quello che sarebbe stato occupato da un numero di unità di calcolo equivalenti, per prestazioni, allo stesso tessellator. Sicuramente con altri 4 cluster attivi RV870 sarebbe stato più veloce, ma non nelle operazioni di tessellation |
|
|
|
|
09-03-2010, 17:51
|
#21832 | |
|
Senior Member
Iscritto dal: May 2005
Città: Zorcolandia...
Messaggi: 10085
|
Quote:
__________________
CPU Ryzen 9 7900 Scheda Madre MSI MPG X870E Carbon Memorie G.Skill Trident Z5 Neo RGB F5 64GB 6000 mhz SSD Kingston KC3000 M.2 NVMe 1TB , SSD Samsung Evo 870 1TB Scheda Video MSI GeForce RTX 5060 Ti 16G GAMING TRIO OC Case MSI MPG Velox 100R Alimentatore MSI MEG Ai1300P PCIE5 Dissipatore AIO MSI MAG CORELIQUID I360 Monitor ASUS PB277Q UPS APC BGM2200B-GR |
|
|
|
|
09-03-2010, 17:54
|
#21833 | |
|
Senior Member
Iscritto dal: Feb 2006
Messaggi: 15361
|
Quote:
|
|
|
|
|
09-03-2010, 18:00
|
#21834 | ||
|
Senior Member
Iscritto dal: Feb 2002
Città: Discovery
Messaggi: 34710
|
Quote:
Quote:
__________________
Good afternoon, gentlemen, I'm a H.A.L. computer. |
||
|
|
|
09-03-2010, 18:04
|
#21835 | |
|
Senior Member
Iscritto dal: Sep 2006
Messaggi: 27924
|
Quote:
__________________
CPU: Ryzen 5700x COOLER: Noctua NH-D15S MOBO: Gigabyte b550 Professional RAM: 4x8 @3600 GPU: XfX Qick319 Rx6700XT HD1: Sk Hynix Platinum p41 2TB HD2: Sabrent Rocket 1TB MONITOR: Xaomi Mi Curved 34"
|
|
|
|
|
09-03-2010, 18:08
|
#21836 | |
|
Senior Member
Iscritto dal: Feb 2002
Città: Discovery
Messaggi: 34710
|
Quote:
http://www.trovaprezzi.it/categoria....zoMax=&sbox=sb se andasse di + sarebbero 400 e passa .
__________________
Good afternoon, gentlemen, I'm a H.A.L. computer. |
|
|
|
|
09-03-2010, 18:12
|
#21837 | |
|
Senior Member
Iscritto dal: Jan 2010
Città: Phanteks P600s white - Gigabyte x670e Aorus Master - Ryzen 7800x3D cooled by Corsair H115i pro - 64GB DDR5 Corsair vengeance pro@6000mhz - Gigabyte 5090 Aorus Ice - Corsair hx1200i - Gaming on LG 55" CX Gsync + DELL Alienware QD-OLED AW3423DW
Messaggi: 13108
|
Quote:
__________________
GALLERY - Phanteks P600s white - Gigabyte x670e Aorus Master - Ryzen 9800x3D cooled by Corsair H115i pro - 64GB DDR5 Corsair vengeance pro@6000mhz - Gigabyte 5090 Aorus Master Ice - WD Black SN850X 4TB - Corsair hx1200i ||Gaming on LG 55" CX Gsync + DELL Alienware QD-OLED AW3423DW Lenovo Legion 14" slim rtx 4060 powered |
|
|
|
|
09-03-2010, 18:36
|
#21838 | |||
|
Member
Iscritto dal: Oct 2006
Messaggi: 102
|
Quote:
Quote:
La sequenzialità delle operazione è quindi rispettata se si considera, diciamo, un poligono singolarmente. Poi è ovvio che la GPU ne esegua molti in parallelo e che non tutti abbiano lo stesso peso computazionale, per cui finiranno e cominceranno in momenti diversi, ma ai fini dell'analisi che stiamo esaminando non ha importanza. Detto questo, sicccome i dati di input non sono infiniti (poniamo 10'000 triangoli, 1'000'000 di pixel) e che le operazioni di fragment shading impiegano molte più risorse rispetto a quelle di vertex, è sempre possibile che in un'architettura a shader dedicati alcuni sp rimangano in alcuni momenti inutilizzati. DA qui il vantaggi degli shader unificati. Ma mi sembra che su questo (e ci mancherebbe) siamo daccordo. Quote:
Con questo non dico che fermi è meglio di cypress. Non ci sono ancora le prestazioni definitive, ma è molto probabile che fermi sia meno efficiente di cypress rapportando le prestazioni al die-size. Ma non centra nulla con quello di cui stiamo parlando x calabar hai capito cosa volevo dire |
|||
|
|
|
09-03-2010, 18:43
|
#21839 | ||
|
Senior Member
Iscritto dal: May 2006
Messaggi: 19401
|
Quote:
Quote:
Specifiche: 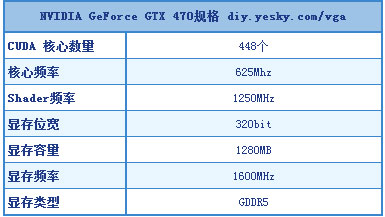 Prestazioni fra la hd5850 e la HD5870 (ma più vicine a quest'ultima) ottime prestazioni con uso intensivo di Tesseletion, FPS più costanti (se i test sono veri), scheda lunga 24cm, consumo atteso attorno ai 190w. |
||
|
|
|
09-03-2010, 18:48
|
#21840 |
|
Senior Member
Iscritto dal: Dec 2000
Messaggi: 305
|
per 350 deve andare meglio della 5870, pochi cazzi. Altrimenti non ha nessun senso.
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 13:48.















