





Nemotron 3 Super: modello AI open da 120 miliardi di parametri di NVIDIA per sistemi agentici

NVIDIA ha presentato Nemotron 3 Super, un modello AI open da 120 miliardi di parametri progettato per applicazioni multi-agente. Grazie a una finestra di contesto da 1 milione di token, architettura ibrida Mamba-Transformer e inferenza ottimizzata per GPU Blackwell, punta a ridurre costi e complessità nei workflow autonomi.
di Manolo De Agostini pubblicata il 12 Marzo 2026, alle 10:01 nel canale WebNVIDIA
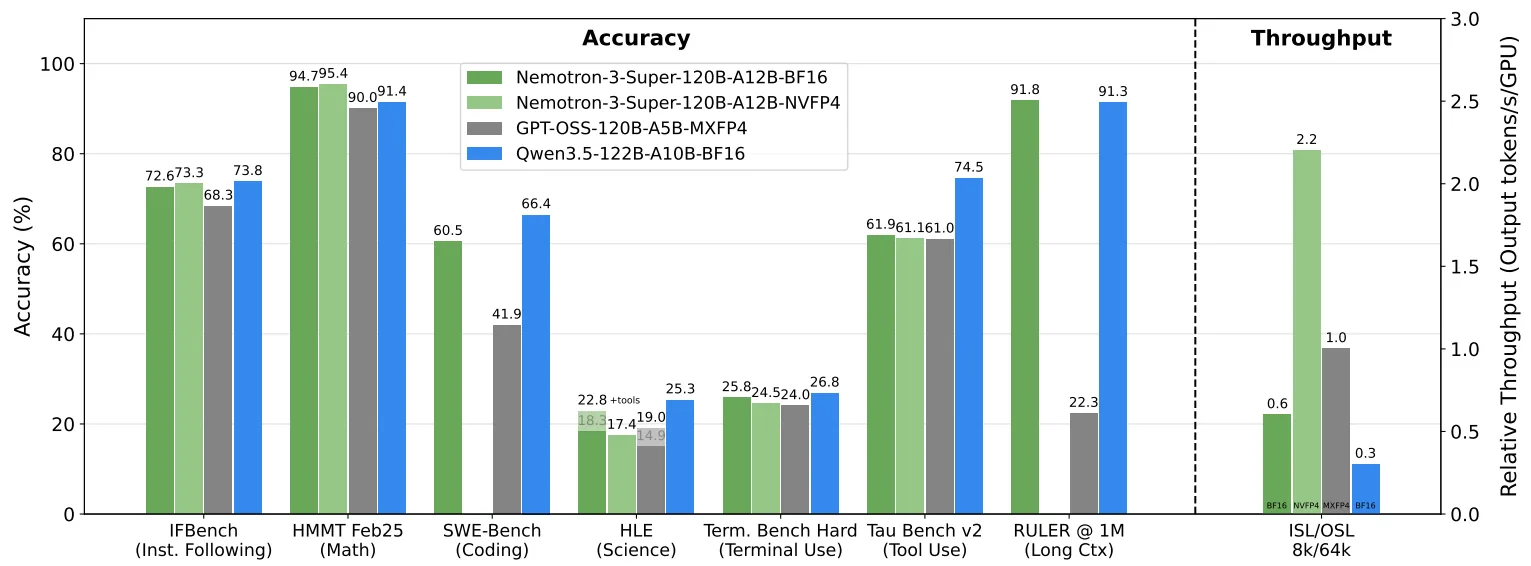
NVIDIA ha annunciato il rilascio di Nemotron 3 Super, nuovo modello linguistico open progettato per l'esecuzione di sistemi di AI agentica complessi. La soluzione introduce un'architettura da 120 miliardi di parametri totali, ma con soli 12 miliardi di parametri attivi durante l'inferenza, un approccio pensato per migliorare efficienza computazionale e costi operativi nelle applicazioni multi-agente.
Il modello è stato progettato per affrontare alcune delle principali limitazioni che emergono quando i modelli linguistici vengono utilizzati come motore decisionale in pipeline autonome. In questi scenari, infatti, l'esecuzione di workflow complessi comporta un forte aumento del volume di dati elaborati: secondo NVIDIA, i sistemi multi-agente possono generare fino a 15 volte più token rispetto alle normali conversazioni.

Questo fenomeno, definito "context explosion", deriva dalla necessità di reinviare continuamente lo storico delle interazioni, le risposte degli strumenti utilizzati e i passaggi intermedi di ragionamento. Con il tempo ciò può portare a un disallineamento rispetto all'obiettivo iniziale (goal drift) e a un aumento significativo dei costi computazionali.
Per mitigare questi problemi, Nemotron 3 Super introduce una finestra di contesto nativa da 1 milione di token, pensata per consentire agli agenti di mantenere in memoria l'intero stato di un workflow complesso. In teoria questo permette al modello di analizzare simultaneamente grandi quantità di dati, come interi codebase software o migliaia di pagine di documentazione.
L'obiettivo è ridurre la necessità di rielaborare continuamente le informazioni durante conversazioni o processi di lunga durata, migliorando al contempo l'allineamento del modello con il compito iniziale.
Uno degli elementi tecnici distintivi di Nemotron 3 Super è l'architettura ibrida Mamba-Transformer combinata con un sistema Mixture-of-Experts (MoE).
Un'altra caratteristica chiave è la multi-token prediction (MTP). A differenza dei modelli tradizionali che prevedono un token alla volta, Nemotron 3 Super genera simultaneamente più token futuri in un singolo passaggio.
Questo approccio garantisce una maggiore capacità di modellare sequenze logiche lunghe durante l'addestramento e un'inferenza più rapida grazie a una forma di speculative decoding integrato. Secondo NVIDIA, questa tecnica può portare a fino a tre volte la velocità di generazione nelle attività strutturate come codice o chiamate di strumenti.
Nemotron 3 Super è stato addestrato utilizzando NVFP4, formato floating-point a 4 bit progettato per l'architettura GPU Blackwell. Diversamente da molti modelli quantizzati dopo l'addestramento, in questo caso la riduzione di precisione è stata utilizzata direttamente durante il training.
Clicca per ingrandire
L'approccio consente di ridurre significativamente il fabbisogno di memoria mantenendo la stabilità numerica del modello. NVIDIA sostiene che l'inferenza possa risultare fino a quattro volte più veloce rispetto al formato FP8 utilizzato su GPU Hopper, mantenendo livelli di accuratezza comparabili.
NVIDIA distribuisce Nemotron 3 Super con pesi open, dataset e pipeline di addestramento pubblicate. Il modello può essere eseguito su workstation, datacenter o cloud ed è disponibile tramite piattaforme come Hugging Face, OpenRouter e build.nvidia.com.



 Wi-Fi 7 con il design di una vetta innevata: ecco il nuovo sistema mesh di Huawei
Wi-Fi 7 con il design di una vetta innevata: ecco il nuovo sistema mesh di Huawei Core Ultra 7 270K Plus e Core Ultra 7 250K Plus: Intel cerca il riscatto ma ci riesce in parte
Core Ultra 7 270K Plus e Core Ultra 7 250K Plus: Intel cerca il riscatto ma ci riesce in parte PC Specialist Lafité 14 AI AMD: assemblato come vuoi tu
PC Specialist Lafité 14 AI AMD: assemblato come vuoi tu Musica generativa, arriva Lyria 3 Pro: ora Gemini compone brani completi
Musica generativa, arriva Lyria 3 Pro: ora Gemini compone brani completi Melania Trump scortata da un robot umanoide alla Casa Bianca. Il video è virale
Melania Trump scortata da un robot umanoide alla Casa Bianca. Il video è virale HONOR 600: nuove conferme sulle specifiche del nuovo mid-range con batteria enorme
HONOR 600: nuove conferme sulle specifiche del nuovo mid-range con batteria enorme Blade 16: Razer sostituisce AMD con Intel, e i prezzi volano
Blade 16: Razer sostituisce AMD con Intel, e i prezzi volano Solo 649 con coupon: questa e-bike da città HillMiles ha 100 km di autonomia, batteria rimovibile IP65 ed è in offerta in 3 colori
Solo 649 con coupon: questa e-bike da città HillMiles ha 100 km di autonomia, batteria rimovibile IP65 ed è in offerta in 3 colori Arriva AI Dividend: 1.000 dollari al mese per chi ha perso il lavoro a causa dell'intelligenza artificiale
Arriva AI Dividend: 1.000 dollari al mese per chi ha perso il lavoro a causa dell'intelligenza artificiale Forza Horizon 6 sorprende con requisiti PC accessibili e supporto al gaming handheld fin dal lancio
Forza Horizon 6 sorprende con requisiti PC accessibili e supporto al gaming handheld fin dal lancio Smart TV QLED 50'' a un super prezzo: 4K, 120Hz e HDMI 2.1 tornano a 249 con Google TV e DAZN gratuito per 6 mesi
Smart TV QLED 50'' a un super prezzo: 4K, 120Hz e HDMI 2.1 tornano a 249 con Google TV e DAZN gratuito per 6 mesi Crypto, GPU e miliardi: la causa che mette NVIDIA all'angolo entra nel vivo
Crypto, GPU e miliardi: la causa che mette NVIDIA all'angolo entra nel vivo Gap e Google portano l'acquisto conversazionale a un nuovo livello: si potranno acquistare vestiti all'interno di Gemini
Gap e Google portano l'acquisto conversazionale a un nuovo livello: si potranno acquistare vestiti all'interno di Gemini DLSS 5 è qui per restare: ecco cosa ha detto il director di Kingdom Come: Deliverance 2
DLSS 5 è qui per restare: ecco cosa ha detto il director di Kingdom Come: Deliverance 2 Un PC HP tuttofare a 649 imperdibile: 32GB di RAM, 1TB SSD, Intel Core i5, ma solo 9 pezzi
Un PC HP tuttofare a 649 imperdibile: 32GB di RAM, 1TB SSD, Intel Core i5, ma solo 9 pezzi I leader di Meta, NVIDIA e Google entrano nel consiglio tecnologico di Trump per guidare le politiche su AI e innovazione
I leader di Meta, NVIDIA e Google entrano nel consiglio tecnologico di Trump per guidare le politiche su AI e innovazione Dreame vs ECOVACS: 4 robot aspirapolvere super interessanti in offerta su Amazon, da 379 a 649
Dreame vs ECOVACS: 4 robot aspirapolvere super interessanti in offerta su Amazon, da 379 a 649



























3 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoIl modello è open ma questa ottimizzazione
vincola all'uso di architettura Nvidia?
Il modello è open ma questa ottimizzazione
vincola all'uso di architettura Nvidia?
Si fp4 è lo standard generico (4bit) mentre nvfp4 è una tecnica per manipolare i piccoli numeri che si è inventata Nvidia, comunque sempre di matematica parliamo,ovvero manipolazione dei numeri.
Nvfp4 richiede hardware Nvidia,potrebbe girare anche su altro hardware ma ci girerà male naturalmente.
Nella pratica non ci sono molte alternative reali ad NVidia se vuoi usare LLM localmente, ma è sempre possible convertire da NVFP4 ad altri formati compatibili anche con CPU (se hai memoria RAM multicanale sufficientemente veloce), come è stato già fatto qui:
https://huggingface.co/unsloth/NVID...-120B-A12B-GGUF
Blackwell ha supporto nativo (hardware) per il formato NVFP4, ma alla fine per l'inferenza il limite prestazionale è dato principalmente dalla larghezza di banda della memoria.
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".