





|
|||||||


|



|
|
 |
|
|
Strumenti |
 19-11-2010, 14:01
19-11-2010, 14:01
|
#21 |
|
Moderatore
Iscritto dal: Nov 2006
Messaggi: 21702
|
Someone, il fatto di non poter usare un cluster per valutare le performance di una singola componente è palese
daltronde non si possono neanche confrontare direttamente le due architetture per "via numerica" (n° shader ecc ecc) in quanto le architteture sono troppo diverse. rimane solo la possibilità di testare mediante bench una singola gpu ma anche qui bisogna stare attenti in quanto le architetture fondamentalmente diverse permettono facilmente di taroccare il risultato in base a come viene svolto il benchmark e comunque a cappello di tutto visto il tuo storico messaggi diciamo non super partes chiederei gentilmente di dimostrare ogni tua tesi in maniera oggettiva e documentata
__________________
"WS" (p280,cx750m,4790k+212evo,z97pro,4x8GB ddr3 1600c11,GTX760-DC2OC,MZ-7TE500, WD20EFRX) Desktop (three hundred,650gq,3800x+nh-u14s ,x570 arous elite,2x16GB ddr4 3200c16, rx5600xt pulse P5 1TB)+NB: Lenovo p53 i7-9750H,64GB DDR4,2x1TB SSD, T1000 |

|

|
|
19-11-2010, 15:07
|
#22 | |||||||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Ti consiglio un'approfondita lettura dell'articolo di B3D, comprese le conclusioni. Forse ti servirà per chiarirti di più le idee. Quote:
Ultima modifica di yossarian : 19-11-2010 alle 17:57. |
|||||||
|
|
|

|
19-11-2010, 21:44
|
#23 |
|
Member
Iscritto dal: Sep 2007
Messaggi: 265
|
Comunque, per tornare alla parte tecnica dell'articolo
Quindi 3mila volte meno di quanto citato. Il che significa che purtroppo l'energia spesa per effettivamente fare le operazioni numeriche (cioe' quello che ci interessa) e' una frazione trascurabile dell'energia consumata dal chip. Questo non sorprende, il grosso dell'energia e' spesa nel trasferire i dati da e verso la memoria (specie off-chip). Se potessimo davvero spendere energia solo per fare la comptazione, un solo GF100 sarebbe potente circa quanto tutto il nuovo Tianhe In quest'ottica va letta la seconda parte dell'articolo, quando Dally parla di cache multilivello programmabili e tenere i dati il piu' vicino possibile alle unita' funzionali. |
|
|
|
|
20-11-2010, 01:12
|
#24 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
|
|
|
|
|
|
20-11-2010, 01:52
|
#25 |
|
Member
Iscritto dal: Sep 2007
Messaggi: 265
|
Ho scritto una cazzata
5 miliardi di istruzioni per Joule sono 5 gigaFLOPS, non teraFLOPS, quindi 1.5 teraFLOPS per 300 Watt, quindi un rapporto di 3, non 3mila Cmq il problema di fondo e' quello: l'energia per i bus (specie off-chip), il clock, il controllo, la decodifica delle sitruzioni eccetera e' ben maggiore dell'energia usata per fare i calcoli in se'. Questo e' un bel problema... e di non facile soluzione |
|
|
|
|
20-11-2010, 02:27
|
#26 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
in questi anni sono stati fatti diversi passi avanti: trasferimento di dati in batch dalla ram di sistema alla ram video e da questa all'interno dei registri, per ridurre l'impatto degli accessi a memorie esterne, soprattutto a quella di sistema che passa attraverso il collo di bottiglia del bus pci express); aumento esponenziale del numero di registri per avere più thread on fly (questo porta due vantaggi: riduzione degli accessi all'esterno e, soprattutto, miglior mascheramento delle latenze); introduzione di cache all'interno delle gpu (inizialmente solo per le texture che erano le più problematiche da gestire per le latenze, poi anche per i dati di altra natura); aumento dei bus verso l'esterno e, soprattutto, verso l'interno dei chip, con architetture di tipo asimmetrico sempre più complesse. I memory controller sono diventati, in molti ambiti, i veri arbitri delle prestazioni di un chip. I chip hanno aumentato notevolmente la loro efficienza passando agli shader unificati ma questo aumento è dovuto ad una diversa gestione del lavoro delle alu e non ad un aumento dell'efficienza della singola alu. Il rovescio della medaglia è stato l'aumento della complessità dei circuiti che si occupano di gestire e controllare il lavoro delle unità funzionali. Quella di tentare di ridurre al minimo la necessità di accedere alla memoria esterna è una delle scommesse del futuro ma tu sai bene che anche la gestione di una gran mole di traffico all'interno del chip presenterebbe non poche criticità. Adesso si sta perseguendo la strada di strutturare le architetture interne su più livelli; così hai 2, 3, 4 macro blocchi di alu, ciascuno diviso, a sua volta, in gruppi più piccoli e via dicendo, fino ad arrivare alla singola alu. Ma anche questo tipo di architettura comporta problemi. Una logica a più livelli significa che tutti i circuiti che gestiscono i vari livelli devono dialogare tra di loro (il che si traduce in più cicli impiegati in operazioni che non coinvolgono le unità funzionali). |
|
|
|
|
|
20-11-2010, 03:31
|
#27 |
|
Member
Iscritto dal: Sep 2007
Messaggi: 265
|
Gia', ma alla fine ci tocchera' probabilmente rivedere tutta l'interazione hardware/software per raggiungere quei livelli di prestazioni (exascale e oltre). Ad esempio, ci sono tentativi di cambiare il paradigma di programmazione (sempre per applicazioni numeriche, ovviamente) in cui si programma direttamente la gerarchia di memoria: non e' tanto piu' una questione di dispacciare istruzioni alle unita' funzionali, ma una questione di portare i dati il piu' vicino possibile alle unita' funzionali e tenerli li', per ridurre i trasferimenti di memoria. Un esempio:
http://sequoia.stanford.edu/ e se guardi la documentazione, il backend e' in... CUDA! Surprise Cos'e' che si diceva nell'articolo? |
|
|
|
|
20-11-2010, 18:10
|
#28 | |
|
Bannato
Iscritto dal: Jun 2008
Messaggi: 122
|
Quote:
In OpenCL l'architettura nvidia mostra una efficienza migliore. Poi mi fa strano che tu chieda a me di dare dimostrazione di tesi quando dall'altra parte non ci sono link e si continua a distorcere il discorso su consumi e teorie varie per non rispondere alla semplice domanda posta: i problemi OpenCL di AMD sono di driver o di architetttura HW? E ripeto, come è possibile che due architetture apparentemente simili nel campo consumer poi mostrino tante differenze quando si tratta di usare programmi professionali? Come si vede questi programmi usano qualcosa di diverso rispetto ai videogiochi, dato che è ben visibile la differenza tra una Quadro e una GeForce con lo stesso chip. I driver sbloccano queste funzionalità sulle schede Quadro/FireStream, ma perchè da una parte queste funzioni vanno il doppio? Perché il Cypress spesso non raggiunge nemmeno le prestazioni del G200? Perchè? Pronto, dall'altra parte, invece di confondere il discorso con argomenti senza senso, rispondere a queste domande. Magari anche solo alla prima relativamente all'OpenCL. Grazie. |
|
|
|
|
|
21-11-2010, 01:02
|
#29 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Anche il fatto che non ci possa agire direttamente sui registri è un'altra limitazione. Le unità funzionali delle gpu lavorano quasi esclusivamente con i registri. Facendo un passo indietro ed ammettendo che siano accessibili direttamente anche L1 ed L2, a quali unità interne le si potrebbe abbinare? L2, magari, alle RBE o utilizzata in un sistema dual gpu sulla stessa vga ma per L1 l'unico uso che mi viene in mente è quello nell'ambito di un sistema multichip, magari anche di tipo asimmetrico, con cpu e gpu. In sintesi, al momento, non mi sembra l'ideale per gestire il lavoro di processori che fanno del parallelismo e del multithreading i loro punti di forza. Altra cosa, non mi pare (ma forse mi è sfuggito) di aver letto nulla riguardo alla gestione delle texture cache. Questo significa che Sequoia è progettato solo per il gpgpu? In caso contrario, ritengo che il modello di programmazione per gpu debba esporre anche le texture cache. Infine, ho letto che, la comunicazione tra livelli è limitata alla copia dei dati dalla cache di un livello a quella di un altro livello col meccanismo dei DMA. In tal caso, però, rischi di scontrarti con gli stessi limiti dei sistemi attuali. Un DMA è gestito dal memory controler in maniera trasparente al programmatore e quindi bus e MC potrebbero diventare, di nuovo, il collo di bottiglia. Queste sono considerazioni fatte dopo una lettura al volo del documento di presentazione di Sequoia (di cui avevo solo sentito parlare) e, ovviamente, qualcosa può essermi sfuggita. In quanto all'utilizzo di CUDA per il backend, la cosa non deve sorprendere, visto che, al momento, per le gpu, l'unico modello proposto si basa su CUDA ed è stato progettato basandosi su gt200 prima e gf100 poi. Ultima modifica di yossarian : 21-11-2010 alle 01:07. |
|
|
|
|
|
21-11-2010, 01:06
|
#30 | |
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Tra l'altro, sei talmente preso dal tentativo ridicolo di dimostrare l'esistenza di "armi segrete" che non ti sei neppure reso conto di quanto, in questi test, la 480 GTX faccia, insolitamente, schifo anche rispetto alla 5870 da cui le prende sonoramente ovunque. Considerato che si parla sempre e solo di "muovere poligoni" e che il chip è lo stesso IDENTICO delle quadro, trai tu le tue conclusioni. Per la cronaca, in nessuno di quei bench si fa uso di fp64 e queste Cinebench OpenGL testing reveals similar performance between the Quadro 6000 and 5000 videocards. Looking at the rest of the scores, its apparent that ATI has optimized their drivers for this particular benchmark, while NVIDIA has yet to do so. As new drivers are released, we expect to see Cinebench scores of the Quardo cards increase. che tu hai preso per verità assoluta, sono solo pippe mentali del recensore Ultima modifica di yossarian : 21-11-2010 alle 03:37. |
|
|
|
|
|
21-11-2010, 06:38
|
#31 | ||||
|
Member
Iscritto dal: Sep 2007
Messaggi: 265
|
Quote:
Quote:
Quote:
Quote:
|
||||
|
|
|
|
21-11-2010, 15:21
|
#32 | ||
|
Bannato
Iscritto dal: Jun 2008
Messaggi: 122
|
Quote:
Quote:
Se vuoi te la ripeto un'altra volta, con parole diverse, non si sa mai che tu non l'abbia capita: perchè in OpenCL, sistema dove AMD sta impiegando tutte le proprie forze mentre nvidia è ben più interessata a lanciare CUDA, le schede nvidia vanno di più in praticamente tutti i bench che vengono mostrati? Compresi quelli preparati da AMD insieme a SiSoft? |
||
|
|
|
|
21-11-2010, 15:40
|
#33 | ||||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
Quote:
Quote:
Ultima modifica di yossarian : 21-11-2010 alle 16:48. |
||||
|
|
|
|
21-11-2010, 15:47
|
#34 | |||||||||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
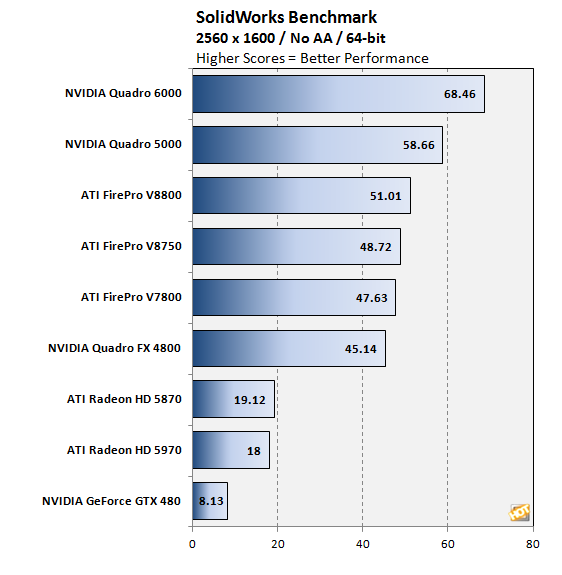 il resto dei test hanno andamento analogo (in alcuni anche peggiore per la geforce) come spieghi le prestazioni della 480 GTX anche in rapporto alla 5870 (due chip di tipo consumer)? Quanto devo aspettare per avere la risposta? A questo intervento, per altro pertinente Quote:
Quote:
Quote:
Quote:
 Quote:
hai idea di cosa sia un loop di fma di tipo scalare a fp32 e chi avvantaggi? Ovviamente no, perchè per te la teoria non serve a niente, l'importante è la pratica che equivale a dire ile "barrette colorate" (anche se poi non capisci neppure a cosa facciano riferimento) hai tirato in ballo gli HPC e presunti test che dimostrerebbero non so cosa. Se ti riferivi a quest'articolo che, tra l'altro, contiene dati sbagliati, devo ripeterti quanto già detto: non dimostra un bel niente e, per quanto possa darti fastidio, da questo link si legge: "Un notevole incremento delle prestazioni del sistema è da imputare al sistema di comunicazione custom sviluppato internamente dal NUDT. Questo sistema permette comunicazioni a 160 Gigabit, il doppio del precedente sistema InfiniBand". Quote:
da uno dei tuoi link p.s. nVidia fa parte del consorzio che sviluppa OpenCL, non è affatto indietro con il supporto e OpenCL non è in competizione con CUDA come non lo è con CAL (chi è il tuo informatore, Paperino?) Ora, prova a cercare, le risposte alle tue domande ci sono tutte. Quelle che non vedo sono le risposte alle mie Quote:
Ultima modifica di yossarian : 22-11-2010 alle 14:09. |
|||||||||
|
|
|
|
22-11-2010, 17:49
|
#35 |
|
Bannato
Iscritto dal: Jun 2008
Messaggi: 122
|
Tutti i test che io ho linkato mostrano che Fermi, sia nelle applicazioni professionali che in quelle di calcolo è nettamente superiore al Cypress. Tu hai postato solo link a test sintetici o particolarmente studiati per eseguire solo un determinato tipo di calcolo.
Ora, ripeto, magari la colpa è dell'ottimizzazione dei driver da parte di AMD, ma il risultato finale è che le schede nvidia vanno di più. Che la GTX480 vs 5870 vada meno può avere milioni di motivi, come detto, anche il fatto che nvidia sulle versioni consumer delle proprie schede blocca una serie di funzionalità (calcolo DP per esempio) mentre le sblocca nella versione professionale del chip ottenendo prestazioni più che doppie rispetto alla versione ottimizzata di Cypress. Continui a girare il manico in un paiolo vuoto. Non ha nessuna importanza per chi acquista una Quadro che la GTX480 va una schifezza. Gli interessa che la scheda che acquista faccia il suo mestiere al max, e visti i risultati direi che la concorrenza è una generazione indietro (forse con raddoppio ulteriore degli SP e contorno raggiungerà le performance). Comunque ti rigiro la frittata: se nel campo professionale le operazioni fatte sono le stesse di quelle usate nei videogiochi, come mai due architetture così simili nei videogiochi poi hanno performance così diverse quando operano (sbloccate, ottimizzate quello che vuoi) nel campo professionale dove ovviamente si cerca di fare in modo che il proprio prodotto dia il massimo senza limitazioni di sorta? Il link di Sisandra che mostra la potenza del Cypress maggiore di quella di Fermi è frutto proprio di uno di quei bench semplici che sfruttano le potenzialità dell'architettura 4+1 di AMD (a la 3D Mark). Ma se guardi i test specifici dove vengono fatti dei bench meno semplici, il Fermi mostra di avere capacità decisamente diverse. Cioè è come se le schede AMD nel 3D mark segnassero il doppio dei punti e poi nei giochi andassero la metà della concorrenza. Ora, dato che sei tu l'esperto, non è che l'efficienza totale di una architettura non si misura solo nella capacità pura di fare calcoli nella condizione ottimale (come nei bench che TU hai postato) mentre è un qualcosa che prende in esame anche altre cose che a quanto pare, visti i risulti sul campo, AMD non ha? Prendi per esempio F@H che è un'applicazione a cui sia ATI che nvidia hanno dato grande supporto per avere un client ottimizzato. Come la spieghi la questione che le schede nvidia siano 3 o 4 volte più veloci? Eppure non è una applicazione sviluppata da nvidia in CUDA e basta. E non è in sviluppo da ieri. D'altronde, io da puro ignorante al tuo cospetto, mi chiedo che cosa facciano quei 600 milioni di transistor in più in Fermi rispetto al Cypress (o i 500 milioni in più che aveva il G200 rispetto all'RV870) che lo rendono una piastrella da bagno... forse nvidia aveva voglia di contribuire al riscaldamento globale o ha fatto un accordo con qualche produttore di silicio per consumarne di più senza alcun apparente motivo? OpenCL non è un concorrente a CUDA? Secondo il marketing AMD lo è. E a guardare i risultati non si direbbe che abbia una grande arma in mano. Perchè anche se domani le applicazioni (consumer) invece che in CUDA scritte specificatamente per HW nvidia fossero scritte in OpenCL per supportare anche AMD la differenza di prestazioni sarebbe comunque elevata e non favorirebbe certo AMD. E mi (ti) chiedo. Dove sta il problema di AMD? Architettura (intesa non solo come tipo di scelta per gli SP vettoriali vs scalari) o driver? O per te non ci sono problemi e AMD offre le stesse capacità di nvidia nei settori dove le due architetture vengono spremute? A parte i bench sintetici con moltiplicazioni vettoriali, hai qualche altro link dove mostri che AMD è a questo livello? Io per ora vedo le "famose" barrette mostrare risultati migliori per nvidia invece che per AMD. |
|
|
|
|
22-11-2010, 19:40
|
#36 | |||||||||||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:

|
|||||||||||
|
|
|
|
23-11-2010, 09:37
|
#37 | ||
|
Bannato
Iscritto dal: Jun 2008
Messaggi: 122
|
Quote:
Cypress scheda con prezzo/prestazioni migliore nel professionale? Ahahah... sìsì, perchè va il doppio dell GF100 montato su una GTX480 e 1/20 dello stesso su una Quadro? Il chip tra GTX e Quadro è lo stesso, cambia le funzionalità che sono possibili tramite i driver. Ora ti ripeto la domanda, che è di una semplicità disarmante: se i chip sono gli stessi (e lo sono) e con i driver ad hoc si abilitano tutte le funzionalità di cui questi sono capaci (e ci mancherebbe, con quello che si pagano quelle schede) perchè Fermi va il doppio del Cypress? Stiamo parlando di 2 soluzioni che stanno dando (o dovrebbero dare) il massimo delle prestazioni. Dove sta il limite di AMD? Quote:
Poi ascolta, cerchiamo di recuperare la situazione perchè mi sembra che sia abbastanza degenerata. Tu non hai dato alcuna risposta. Fai solo accenni a cose che tu solo capisci. Io ho fatto delle domande ben precise, a cui normalmente una persona informata e seria risponde in maniera chiara e comprensibile. Cosa che non è avvenuta. I test che ho postato come questi: http://www.anandtech.com/show/4008/nvidias-geforce-gtx-580/16 non sono tutti sintetici. In uno di questi si vede che AMD ha un vantaggio rispetto a nvidia, ma in tutti gli altri, dove sono coinvolti operazioni molto complesse come la transcodifica H264 nvidia è decisamente avanti. Allora, pongo la domanda in maniera diversa: l'approccio VLIW di ATI è efficiente in generale? Ovvero, quanta probabilità c'è in generale che un problema generico possa essere risolto più efficientemente con un approccio vettoriale rispetto a uno scalare? Guardando le prestazioni di alcuni benchmark, con un calcolo a spanne, sembra che in media gli SP di AMD siano impegnati meno della metà delle loro capacità massime (tenendo conto di numero e frequenza rispetto a quelli nvidia, intendendo come shader proprio le unità singole di calcolo non i gruppi 4+1, ovvero i 1600 shader contro i 512 Cuda core). Quindi di quelle 5 unità di calcolo solo 2 (più o meno) vengono usate in media. Se i conti spannometrici che ho fatto sono esatti (correggili pure se ho fatto errori), secondo te, è un approccio efficiente rispetto a quello nvidia che li satura sempre tutti magari usando 2 cicli per completare le stesse operazioni che l'architettura AMD fa in un ciclo solo? |
||
|
|
|
|
23-11-2010, 16:02
|
#38 | ||||||||||||||||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
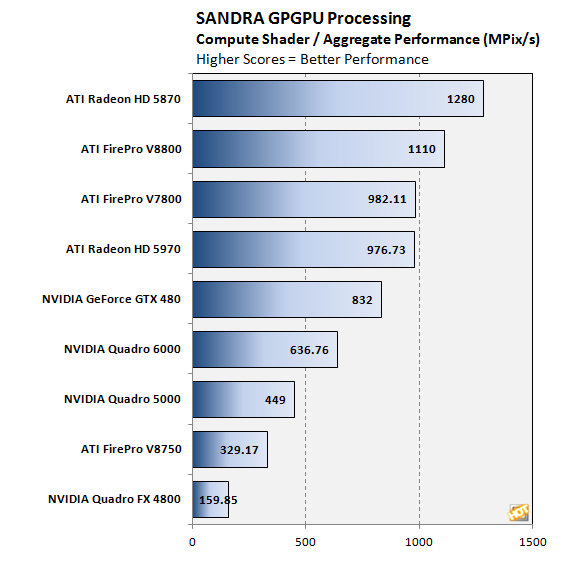 Quote:
Quote:
Quote:
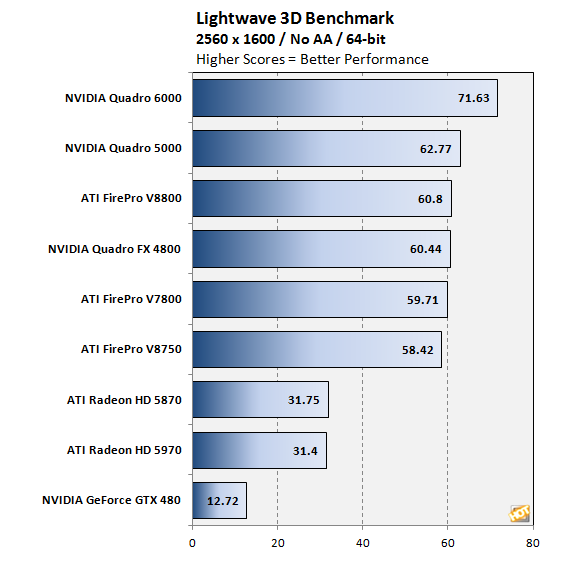 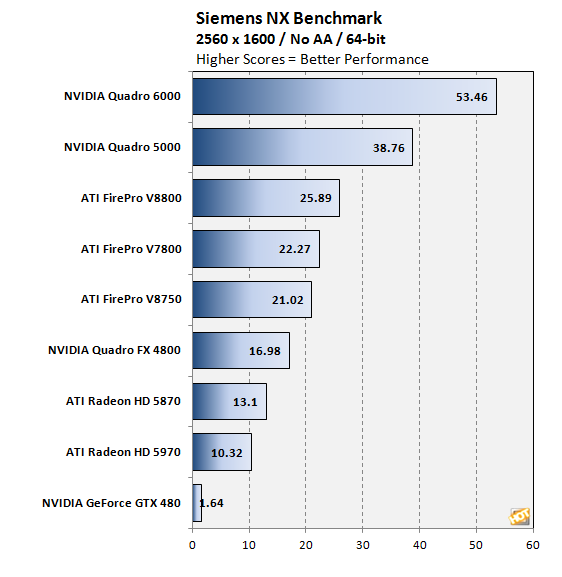 http://www.ciao.it/Nvidia_Quadro_6000__3161202 i tuoi conti non tornano Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
puoi farti un'idea del tipo di codice che può favorire una o l'altra architettura. Apparentemente, l'architettura vliw ha più situazioni in cui è in vantaggio. Però queste situazioni coinvolgono sempre operazioni di tipo vettoriale. Nelle operazioni scalari (tipo la fma fp32 più volte citata), solo una delle 5 vie di ogni alu è occupata nell'esecuzione dell'istruzione. I SW sono un mix di istruzioni di tipo scalare e vettoriale, in floating point o con interi. Se ho un SW che propone un loop di fma o mad fp32, fermi andrà alla massima velocità mentre cypress ad 1/5 della velocità possibile. Diciamo che l'architettura vliw è più dipendente rispetto alle ottimizzazioni del codice ed alla bontà del compilatore, perchè per avere il maggior numero di alu attive è necessario trovare più istruzioni, relative allo stesso thread, indipendenti tra loro (in modo che possano essere chiamate contemporaneamente). In caso di istruzioni scalari dipendenti le une dalle altre (devo aspettare il termine dell'esecuzione di una perchè nella successiva devo inserire il risultato della precedente) l'approccio vliw è molto penalizzato. Un esempio pratico è quello che hai fatto sulle transcodifiche. In quel tipo di operazioni, si fa molto ricorso all'utilizzo di interi e, dalle tabelle, puoi vedere che, ad esmepio, nell'escuzione dei calcoli con interi fermi, tranne il caso di mad di tipo vect4 (poco usata in questo contesto) è alla pari con cypress e, addirittura, si avvantaggia nell'uso della mad di tipo scalare. Quote:
Se guardi, sempre nella stessa pagina, i grafici (con esclusione di quelli DP che è usata solo per il gpgpu), puoi vedere che, a parte i domain shader (una delle componenti dell'operazione di tessellation), in tutte le operazioni di tipo geometrico fermi è mediamente avanti, mentre nelle operazioni di pixel shading è avanti solo con valori scalari (lo stesso puoi vederlo qua e qua). Sia i grafici (sperimentali) che le tabelle (teoriche) comprendono tutte le situazioni possibili (scalari, vettoriali con 2, con 3, con 4 istruzioni indipendenti per ciclo). Ad esempio, un singolo thread con 3 istruzioni indipendenti, su cypress è eseguito in un solo ciclo su fermi in 3 cicli. Quindi, in quel caso, avere 3 alu in parallelo è vantaggioso rispetto ad averne una sola per thread. Sulle operazioni di tipo trascendentale è avvantaggiato cypress perchè ha una unità per ogni alu, dedicata a quel tipo di operazioni, mentre fermi ne ha solo 4 per ogni cluster di alu. Nelle operazioni con interi, invece, fermi ha una unità dedicata ogni due alu floating point mentre cypress una ogni 5. Poi ci sono le operazioni di texturing dove è avvantaggiato cypress; questo perchè il texture filtering è eseguito dallo shader core e nei chip nVidia le texture arrivano compresse e devono essere decompresse prima dell'applicazione. Però, all'aumentare delle dimensioni delle texture, il vantaggio di cypress diminuisce a causa del fatto che le texture sono decompresse nel passaggio in L1 e, di conseguenza, occupano più spazio, mentre fermi le decomprime solo quando prima di effettuare l'interpolazione. . Nelle operazioni di branching fermi utilizza una granularità inferiore (quad di 16 vertex value o 32 pixel vs 16 vertici o 64 pixel) e risulta più efficiente mentre nelle operazioni di color blendong è in vantaggio cypress. Infine ci sono gli accessi alle varie memorie e il triangle setup engine in cui è in vantaggio fermi grazie alla possibilità di caricare più di un triangolo per ciclo di clock. Le variabili in gioco sono tantissime e non è possibile ridurre tutto ad un confronto tra l'efficienza delle sole alu, fermo restando che un'architettura vliw è, in assoluto, meno efficiente se si fa il confronto con i limiti teorici, rispetto ad una superscalare. La diminuzione di efficienza dipende, come detto, in massima parte d come è ottimizzato il SW (per questo un bench che prevede un loop di mad fp32 non può essere stato studiato insieme ad amd, ad esempio). La cosa curiosa di tutto questo è che c'è stata un'inversione in molti campi rispetto al passato; ad esempio, fino a G70 ed R5x0, il dynamic branching di nVidia era un disastro mentre era in vantaggio con le operazioni di texture filtering. Discorso analogo per le operazioni geometriche e per le raster operation (color e alpha blending). Nelle prime era in vantaggio ATi e nelle seconde nVidia. Quote:
Dal canto suo, invece, nVidia ha spostato la maggiore complessità a livello di hardware. Questo significa che i suoi chip sono meno dipendenti dall'ottimizzazione del SW ed è più semplice ottimizzare via driver. Lo svantaggio di questo approccio è che gran parte dei transistor sono utilizzati per circuiti che svolgono compiti non funzionali ai calcoli (circuiti di controllo, feedback, gestione dei clock, instruction e data fetch). Inoltre, un altro vantaggio di cypress è che per mascherare le latenze necessità di un numero inferiore di thread in circolazione all'interno della pipeline, il che si traduce in un minor ricorso a buffer di registri atti temporanei, atti a contenere i risultati intermedi delle elaborazioni. Il core di un chip come fermi, quindi, rispetto a cypress, ha, in percentuale, un'area di molto inferiore dedicata alle unità di calcolo vere e proprie. La scelta è stata dettata principalmente dal fatto che nVidia è obbligata a spingere sul gpgpu non potendo realizzare architetture x86 (che resta, nonostante tutto, il modello più utilizzato anche nei sistemi HPC) mentre AMD può puntare su apu asimmetriche con una cpu e una o più gpu come coprocessori Di conseguenza, da un lato hai una maggiore efficienza che paghi con il poco spazio da poter dedicare alle unità di calcolo (da qui la necessità di differenziare il clock degli shader rispetto al resto del core del chip). Dall'altro una minor efficienza che compensi potendo, ad ogni nuovo processo produttivo, inserire un numero molto maggiore di unità di calcolo rispetto alla concorrenza. Chiudo con la conclusione dell'articolo di B3D Quote:
In quanto all'ultima parte, sono curioso di vedere se e come sarà affrontato il problema di cercare di ridurre le dimensioni dei chip. Per quanto detto prima, se nVidia mantiene questa tipologia di architettura avrà sempre poco spazio sul die da poter dedicare alle unità funzionali. Ridurre ancora la granularità dei cluster (dai 16+16 attuali) porterebbe ad un incremento dell'efficienza del singolo cluster ma anche ad un ulteriore aumento dello spazio da dedicare a elementi non funzionali. Ultima modifica di yossarian : 24-11-2010 alle 10:45. |
||||||||||||||||
|
|
|
|
29-11-2010, 16:22
|
#39 | ||
|
Bannato
Iscritto dal: Jun 2008
Messaggi: 122
|
Sono finalmente riuscito a leggere tutta la review di Beyond3D riguardo a Fermi (il lavoro, questa rottura...)
Premesso che questi test estremamente sintetici hanno solo valore indicativo, dato che come hai detto tu le variabili in gioco sono tantissime e sarebbe bello avere un bench in cui si faccia qualcosa di concreto che prenda in esame la collaborazione delle varie parti della pipeline di calcolo/3D invece che una sola parte specifica, aggiungo solo che i valori di performance nel calcolo DP in quei test è 1/4 e il setup dei triangoli è una frazione di quello che Fermi è in grado di fare per via proprio dei driver "consumer" a cui le GTX sono relegati. Relativamente agli apparenti risultati deludenti dei bench della GTX470 in esame: Quote:
Quote:
Ecco perchè Fermi su una GTX480 nei test professionali è una schifezza assoluta, mentre montato su una Quadro risulta essere decisamente più veloce anche della concorrenza che secondo i test di Beyond3d dovrebbe essere teoricamente molto (ma molto) più veloce. L'unica cosa che sembra non essere all'altezza con la concorrenza è il fillrate e la gestione delle texture, sempre secondo i test riportati. Poi per via della diversa modalità di gestione delle texture sarebbe interessante capire quanto di quel vantaggio che i grafici mostrano siano reali in una applicazione reale dove le texture non sono normalmente completamente contenibili nella L1 del Cypress (oltre a verificare che impatto ha la trasmissione di più dati nel Cypress o lo switching di thread che necessitano della L1 che deve essere liberata). A parte questi dettagli, quello che sembra è che Fermi sia pensato veramente come un sistema General Purpose senza "additivi" vari specialistici. Per quanto è possibile nvidia ricicla le unità standard presenti nel chip per eseguire in maniera generica tutte le possibili computazioni, mentre AMD sembra aver aggiunto HW apposito là dove lo riteneva opportuno. I due approcci sono equivalentemente validi, ma quello nvidia (sebbene non particolarmente performante in alcune situazioni) sembra permettere una gestione più facile del proprio HW dato che percorsi e inevitabili conflitti sono più facilmente prevedibili e lo scheduler può in questa maniera essere più efficiente. E la logica di gestione la può fare in HW. Ecco perchè ritengo che la valutazione delle performance andrebbe fatta con un bench che implichi l'uso reale delle risorse per evidenziare l'architettura meglio bilanciata (più efficiente) invece che un'ispezione particolare di ogni sottoparte. Queste analisi sono molto interessanti, ma non danno il senso di quello che è poi il risultato finale, che come in tutti i sistemi complessi (e questi sono forse la cosa più complessa che l'uomo abbia mai creato) non sono la semplice somma dei risultati parziali. Premesso che la soluzione VLIW sia 4 volte più veloce della soluzione scalare di nvidia in alcune istruzioni, se queste però sono il 5% del totale delle istruzioni eseguite (faccio una ipotesi di quello che potrebbe essere un algoritmo generico) allora il vantaggio prestazionale non sarà evidente e si manterrà un misurabile vantaggio solo se il resto delle istruzioni vengono eseguite almeno con la stessa efficacia della concorrenza. Basta un punto che faccia da collo di bottiglia (o semplicemente il fatto che i risultati ottimali mostrati dai test non si riesca mai a ottenerli in condizioni reali) e tutta la teoria va a escort. La pratica per ora dice che le Quadro vanno il doppio delle FirePro anche se i test fin qui mostrati suggerirebbero proprio il contrario. Più difficile valutare la parte di computazione dove l'implementazione dell'algoritmo è fondamentale , ma quelli OpenCL mostrano una situazione analoga. Domanda finale: e' possibile la situazione futura in cui AMD "restringe" la sua architettura VLIW (oltre a quello fatto con Cayman) mentre nvidia "espande" la sua magari a 2 unità in parallelo? O per nvidia la cosa sarebbe troppo difficoltosa e la preferenza sarebbe piuttosto quella i raddoppiare le proprie unita scalari (a discapito della logica HW necessaria a connetterli e gestirli)? |
||
|
|
|
|
01-12-2010, 01:30
|
#40 | |||||||||
|
Senior Member
Iscritto dal: Mar 2001
Messaggi: 5390
|
Quote:
Quote:
ora è chiaro che con SW pro vengono castrate le gpu consumer (nVidia lo fa in maniera molto più pesante ma lo fa anche ati) e viceversa (guarda caso, con i giochi, le schede pro vanno sempre "un po' di meno" a parità di specifiche Quote:
Per le operazioni di texturing, quando si fa un accesso a texture la pipeline non va in stallo in attesa del completamento dell'operazione ma il relativo thread vìene "parcheggiato" in attesa del dato mancante (la texture nella fattispecie) e si passa ad un altro thread (indipendente dal risultato di quello in esecuzione, ovviamente). Un altro fattore che non hai considerato nella generazione delle operazioni di texture e non solo è la gerarchia delle memorie interne. In questo l'architettura vliw è superiore i quanto i dettagli dell'architettura sono completamente esposti. Il risultato è una maggiore efficienza che si traduce in una maggiore velocità nelle operazioni di load e store dai registri e un miglior mascheramento delle latenze (dovuto soprattutto alla maggior velocità di accesso ai vari ordini di memoria). In quanto al discorso sulla L1, questo è valido solo in caso di cache miss, piuttosto improbabile con gerarchia delle cache di tipo fully associative associata ad algoritmi di branching. . Quote:
Quote:
La differenza la possono fare applicazioni difficilmente parallelizzabili che favoriscono l'HW nvidia. Quote:
Quote:
Quote:
Quote:
|
|||||||||
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 03:21.















