





|
|||||||


|



|
|
 |
|
|
Strumenti |
 08-04-2016, 08:51
08-04-2016, 08:51
|
#1341 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Si potrebbe arrivare all'80% (circa come il CMT) se le 4 ALU fossero universali, o almeno 2mul+2div, si avessero 4 AGU e 4 unità di load store... In pratica un modulo XV unificato ma con una unica cache L1D... Il 50% comunque è una media... Si può arrivare a +80-90% se entrambi i thread hanno poche mul, poche div e pochi accessi in memoria, magari con codice intrinsecamente seriale, come calcoli lunghi e complicati, come una formula matematica complessa in un loop, dove ogni risultato dipende dai precedenti (perchè è una unica formula complicata) e quindi la pipeline stalla spesso...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|

|

|
08-04-2016, 15:28
|
#1342 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
|
|
|
|
|
08-04-2016, 16:37
|
#1343 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
Ad AMD servirebbe un SMT4 e forse qualche porta L&S in più per scatenare la bestia... ps- il bench in questione (7zip), scala alla perfezione, quindi siamo davvero "vicino" al massimo potenziale. |
|
|
|
|
08-04-2016, 16:47
|
#1344 |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Se intel ha ottenuto il 30% con la sua architettura scarsa, forse vuol dire solo che il POWER ha un ottimo Single thread... Potrebbe essere per la ISA più RISC-like e completamente ortogonale, inoltre il power ha 32 registri... Mentre la isa x86, anche 64 ha pochi registri (16), non è ortogonale e quindi richiede più spesso l'uso della cache/memoria o trucchi con le istruzioni... Se il compilatore fa il suo dovere, con 32 registri si può intervallare molte istruzioni indipendenti e quindi avere un alto IPC e lasciare solo le briciole per gli altri thread... Comunque 7-zip è un carico che è molto memory intensive e i calcoli sono abbastanza semplici... Non mi stupisce che scali poco...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
08-04-2016, 16:47
|
#1345 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
|
|
|
|
|
08-04-2016, 16:48
|
#1346 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
08-04-2016, 16:49
|
#1347 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32184
|
(nulla a che vedere come discorso di bandiera)
Boh... a me l'SMT non piace...certo che vedere i numeri Power8 un po' di scimmia viene... però il Power8 (non li ho mai usati Però rimango sempre dell'idea che Carrizo 2 con "estrogeni", modificato da FX e portato sul desktop, sul 14nm, farebbe scintille... Però... leggendo i vostri post, concordo su jaguar/XV = Zen (preso un po' da uno ed un po' dall'altro)... spero solamente che l'imperativo di aumentare l'IPC non sia dovuto a frequenze inferiori a BD 32nm, ma c'è anche la possibilità (tutt'altro che remota) che AMD abbia potenziato l'IPC (Zen) ancor prima di conoscere il 14nm, in quanto non avendo più le FAB non può svilluppare a piacere il silicio e quindi aumentare l'IPC ridurrebbe il bisogn di frequenze alte-
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 08-04-2016 alle 17:59. |
|
|
|
08-04-2016, 16:49
|
#1348 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
08-04-2016, 16:52
|
#1349 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
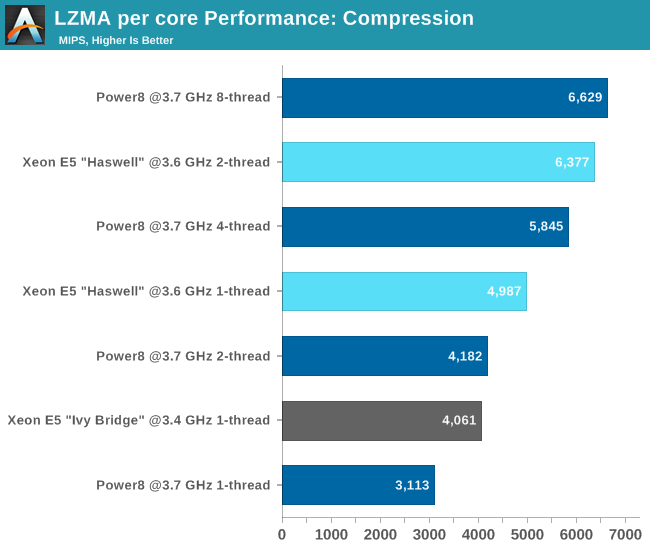
Cmq in single thread è una mezza calzetta e dicono di aver aumentato IPC sT del 60% rispetto al power7... Per l'incontentabile  bjt2 ecco il raytrace : bjt2 ecco il raytrace :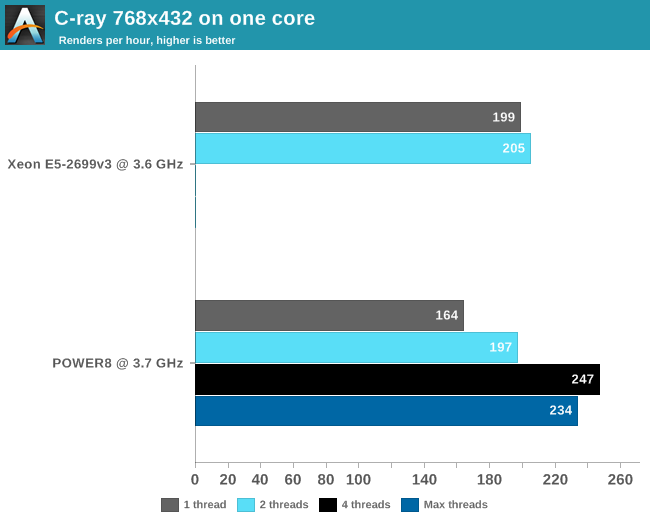
Ultima modifica di Ren : 08-04-2016 alle 17:14. |
|
|
|
|
08-04-2016, 16:57
|
#1350 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Allora sarà 30% max per INTEL e 50% max per AMD... Comunque questo è software compilato appositamente... Con software legacy, o non compilato appositamente, penso che si possa otterere di più...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
08-04-2016, 17:05
|
#1351 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
Credo anche che ROB magri e pipeline lunghe(missprediction) si avvantaggino molto più del SMT, soprattutto con molti thread. Ribadisco, secondo me 50% con SMT2 è un utopia... |
|
|
|
|
08-04-2016, 17:10
|
#1352 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
|
|
|
|
|
08-04-2016, 17:53
|
#1353 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
EDIT: secondo wikipedia ha 2rw+2r pipeline, quindi non 2+1... Max 4 letture o 3 letture+1scrittura o 2 letture+2scritture... EDIT: 8 decoder, in media 1 per thread... E' intel che è anomalo con 2x256b r e 1x256b w... Se solo fosse possibile splittarle almeno in 2 (anche per avere più transazioni a 64 bit)... Magari per SMT4 faranno così... Passare a 4 porte a 256 bit mi sembra un po' troppo...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! Ultima modifica di bjt2 : 08-04-2016 alle 18:00. |
|
|
|
|
08-04-2016, 18:13
|
#1354 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
|
|
|
|
|
08-04-2016, 18:25
|
#1355 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
08-04-2016, 18:31
|
#1356 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
I decoder sono 8, ma hanno implementato il macrofusion. Il ROB supera di poco le 100e e gli stadi fino al decoder sono 10. Se serve altro chieda pure... ps. sto leggendo da un articolo ibm. |
|
|
|
|
08-04-2016, 18:45
|
#1357 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
P.S.: odio quando delle unità condividono delle porte... Il progetto di AMD mi sembra più pulito...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
08-04-2016, 22:08
|
#1358 | ||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
Quote:
E' tutto il tratto condiviso dai thread, dal prefetch al RoB, che deve essere "adeguatamente" dimensionato.. Quote:
Notare che nonostante ciò lo scaling SMT, ha subito incrementi minimi. Questo sta a significare, ad un analisi alla buona, che le risorse messe a disposizione sono pensate per le prestazioni nel ST, e solo in seconda battuta si cerca di sfruttare le risorse inutilizzate... Non sembrerebbe un caso che IBM sia passato ad una soluzione SMT8, con un aumento di ipc nel ST, che ha dell'incredibile (+40%  ), probabilmente per recuperare il recuperabile. ), probabilmente per recuperare il recuperabile.PS la strada maestra per aumentare il throughput di PICCO rimane quella di tanti piccoli core. Il SMT serve innanzitutto per poter aumentare il ILP, senza sacrificare il throughput complessivo REALE, ovvero non rendere svantaggioso l'aumento di ipc (ST ovviamente)
Ultima modifica di tuttodigitale : 08-04-2016 alle 23:21. |
||
|
|
|
08-04-2016, 22:28
|
#1359 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 32184
|
Ho fatto una carellata in vari forum, e alla fine questo TH è conservativo sulle frequenze di Zen. Praticamente oramai tutti danno Zen > 3,5GHz, una base di almeno 3,7GHz ma c'è chi si sbilancia sui 4GHz def.
E' chiaro che sono tutte voci, di sicuro c'è solo l'ES a 3GHz con turbo disattivato. Però, se non ricordo male, mi sembra che nelle previsioni di clock per proci AMD si è sempre stati più bassi, vedi Phenom II 3GHz e lo si dava per 2,5GHz, Thuban 2,5GHz ed invece 3,2GHz, Zambesi 3GHz ed invece 3,6GHz, Piledriver sempre 3,6GHz ed invece 4GHz... speriamo sia così anche per Zen, se lo danno 3,7GHz/4GHz, c'è la possibilità che sia 4,5GHz
__________________
9950X PBO 1X CO -33 Override +100 CPU-Z RS/DU 930/18.563 - CB23-2339 - 47682 47728 -CB24 144 2508 - OCCT - V-RAY 53.994 - GeekBench 6.3 3563/22664 - TEST RS Y-Cruncher BKT - core 0-15 NPbench - CPU-Z 19207 - CB23 49265 - CB24 2593 Ultima modifica di paolo.oliva2 : 09-04-2016 alle 06:33. |
|
|
|
08-04-2016, 23:06
|
#1360 |
|
Senior Member
Iscritto dal: Oct 2006
Città: Roma
Messaggi: 2514
|
Iscritto

__________________
Sotto la panza la mazza avanza win11 pro . 9800x3d nh-u12s . msi x870e carbon . trident z5 32Gb . rtx 4080 . enermax 850 . QN900A65 8k . m2 990 pro . G 502x . |
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 20:52.















