





|
|||||||


|



|
|
 |
|
|
Strumenti |
 19-11-2025, 13:01
19-11-2025, 13:01
|
#1 |
|
www.hwupgrade.it
Iscritto dal: Jul 2001
Messaggi: 75166
|
Link alla notizia: https://www.hwupgrade.it/news/skvide...on_146462.html
AMD presenterà ufficialmente FSR Redstone il 10 dicembre, aggiornamento destinato a Radeon RX 9000. Il pacchetto integra Neural Radiance Caching, Ray Regeneration, ML Super Resolution e ML Frame Generation, quattro tecnologie basate sul nuovo modello neurale Click sul link per visualizzare la notizia. |

|

|
|
19-11-2025, 18:26
|
#2 |
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 4111
|
"su architettura RDNA 3/3.5. Chiaramente, il limite rimane l'assenza delle unità neurali"
Smentisco immediatamente: RDNA3 ha gli acceleratori IA su linguaggio WMMA. Che poi AMD non li utilizzi è un altro paio di maniche È pure scritto in tabella: https://www.amd.com/en/technologies/rdna.html FSR4 su INT8 nemmeno utilizza gli acceleratori IA  ERGO si potrebbe andare meglio
__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET Ultima modifica di Max Power : 19-11-2025 alle 19:18. |
|
|
|
|
19-11-2025, 21:26
|
#3 | |
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4222
|
Quote:
Vedrai che a quel punto anche RDNA4 sembrerà una merda in confronto. Non estrai sangue da una rapa, e l'architettura RDNA di AMD è un ravanello. Diventerà competitiva solo da UDNA in poi, ma voglio vedere quanto diventerà grande, visto che già ora che non ha unità RT complete e niente unità matriciali il computo dei transistor è enorme. Ultima modifica di CrapaDiLegno : 19-11-2025 alle 21:34. |
|
|
|
|

|
20-11-2025, 08:01
|
#4 | ||
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 4111
|
Quote:
 Le unità accelerate si aggiungono agli HLSL Shader Model 6.8 E non devono di certo chiedere a te come implementarle Quote:

__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET Ultima modifica di Max Power : 20-11-2025 alle 15:59. |
||
|
|
|
|
20-11-2025, 12:09
|
#5 | |
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4222
|
Quote:
E sì, le unità RT di AMD sono mezze schifezze create al volo quando non sapeva più cosa fare quando è arrivato Turing. Usare le TMU modificate è stata una furbata per non dover riprogettare tutto, ma è anche una soluzione che ha efficacia molto ma molto bassa, come si è visto finora. Sei un fanboy ignorante come la peste che cerca solo di indorare una supposta veramente grande da inserire. AMD è passata da una RDNA1 priva di qualsiasi accelerazione per RT e AI (a livello di Pascal) a mettere man mano qualcosa in più nelle revisioni successive. Alla fine con RDNA4 ha una implementazione WMMA completa basata sugli shader che accelera sì, ma lontanissima dall'efficacia di unità matriciali dedicate e parallele. E il codice scritto per RDNA4 sulle architetture passate può solo essere emulato con molti più passaggi e semplificazioni, al punto che il vantaggio di usare l'AI per evitare di usare la pipeline 3D viene meno (è più lenta a calcolare un fake frame che a generarlo ex novo, da qui semplificazioni, tagli, imprecisioni che non ci sono su RDNA4). Quando hai capto questo, hai capito perché AMD non vuole usare FSR4 sulle architetture precedenti che si rivelano essere delle mezze merdate quando invece erano vendute come pari alla concorrenza usando metodi di calcolo standard del secolo scorso. Il resto dei tuoi commentini stupidi con le faccine idiote (che ti rappresentano perfettamente ) sono inutili tentativi di propaganda pro AMD.Spiaze che arrivi (o meglio arrivate perché non sei il solo tordo a non capire le cose in anticipo) sempre tardi e cerchi di girare la frittata per far combaciare le cazzate che hai detto precedentemente. Vedremo cosa ti inventerai quando arriverà UDNA con quello che dovrebbe essere il pieno supporto di tutte le feature moderne (se per moderne si intende quello che Nvidia ha introdotto nell'ormai lontano 2018). Intanto puoi continuare con la tua Ultima modifica di CrapaDiLegno : 20-11-2025 alle 12:12. |
|
|
|
|
|
01-12-2025, 00:16
|
#6 | |
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 4111
|
Quote:
Mettiamo in ordine la tua confusione freudiana: Le istruzioni WMMA sono implementate sulle shader array: è una scelta architetturale, punto. Le unità RT di AMD sono pipeline dedicate integrate nel texture pipe: gestiscono traversal e intersezioni in hardware. Il discorso delle TMU modificate è una tua invenzione. FSR4, argomento che ci ha permesso di apprezzare il tuo distillato di ignoranza pura: RDNA3 ha unità di calcolo FP16, 32 e 64. Mentre l'FSR4 lavora in FP8, che al momento ha RDNA4. Le possibilità per RDNA3 erano 2: fare una versione in FP16 oppure in INT8. Per ora si è vista la versione INT8, che peraltro funziona. Al momento AMD ci sta lavorando per PS5 Pro e Valve per la Steam Machine. E sono tutte RDNA3. Infine RDNA1 è nata per avere un ottimo rapporto prezzo prestazioni e così è stato. E pensare che ai tempi di Turing c’era gente che esaltava l’RT ibrido in BF5, Tomb Raider e compagnia come fosse il “vero” ray tracing… poi è arrivato il path tracing e gli stessi hanno fatto finta di averla sempre pensata diversamente. Tipico degli assoggettati mentali. Come sempre, cerchi di nascondere dietro ad un dito la vera realtà: che Nvidia è andata avanti a suon di sponsorizzazioni (mazzette ) per far implementare le proprie tecnologie, convincere gli influencer e rompere le palle agli altri (basti vedere quali e quante puttanate hanno fatto su Cyberbug, ma ci sono decine di esempi. Come pure la vergognosa vicenda con HwUnboxed, un comportamento da inferiori)E' storica la campagna diffamatoria nei confronti della GPU Kyro, ma cosa te lo scrivo a fare, all'epoca riempivi il pannolino...pannolino che ovviamente ora usi come cappello E niente, oggi siamo ancora qui con quella fetecchia del PathTracing by Nvidia, che non implementa nessuno se non ben pagato. Ma chi cazzo gli è venuto in mente di utilizzare la superficie di destinazione come emissiva di raggi e poi tutta la gestione geometrica va a merda cit. mod. Belusconi: Siete ancora, oggi e come sempre, dei poveri NVIDIARI!
__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET Ultima modifica di Max Power : 01-12-2025 alle 01:26. |
|
|
|
|
|
01-12-2025, 07:43
|
#7 | |
|
Senior Member
Iscritto dal: Oct 2010
Messaggi: 9863
|
Quote:
__________________
CPU: 7800x3D MOBO: ROG B650E-I RAM: G.Skill 32GB 6000 C30 GPU: RX 9070 NVMe: SN850X 1TB PSU: SF1000 CASE: MiniNeo S400 |
|
|
|
|
|
01-12-2025, 10:59
|
#8 |
|
Senior Member
Iscritto dal: Sep 2003
Città: Torino
Messaggi: 22306
|
speriamo in review comparative su giochi seri e non solo quello annunciato

|
|
|
|
|
02-12-2025, 20:09
|
#9 | ||
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4222
|
Quote:
Praticamente ora sei arrivato a dire quello che ho detto io, che conosco molto bene come funziona l'architettura AMD. 1. NON CI SONO LE UNITA' MATRICIALI DEDICATE. Le istruzioni per il calcolo matriciale sono fatte sulle unità vettoriali e per fare una moltiplicazione servono una serie di cicli a cui aggiungere pure quelli necessari per la somma. E il tutto richiede un sincronismo tra PIU' shader vettoriali perché un calcolo matriciale ne occupa più di una. Dire "è una scelta progettuale" non significa un cazzo. Significa solo che AMD non era pronta a mettere delle unità dedicate e rifare tutta l'architettura da zero. E questo vale anche per le unità RT: Quote:
E' chiaro che dietro tutti quei ci sta un poveretto che non sa fare 2+2: secondo te perché hanno usato delle unità che elaborano texture invece di fare una unità capace di fare i calcoli senza dover mettere i dati dentro una immagine?Non credo che ci arriveresti mai, nemmeno se chiedi a tutte le AI del pianeta (che sono addestrate con i contribuiti da gente ignorante come te). Lo ha fatto per 3 motivi che sono più che validi dal punti d vista del TTM e costi che AMD non può permettersi di aumentare avendo già GPU enormi rispetto a quelle che realizza Nvidia a pari capacità raster. Le restanti funzionalità sono un miraggio per quelle stesse GPU, quindi una parvenza per accontentare i polli come te che poi vanno in giro a dire che AMD ha tutto e che funziona anche meglio della concorrenza bastavano 2 TMU modificate. Ma ecco i motivi: 1. Le TMU hanno accesso diretto alla memoria e alla cache, non serve dover creare un path specifico per dati e istruzioni ed è un immenso vantaggio in termini di tempi di progettazione, complessità e spazi risparmiati 2. Le TMU già nel 2005, si era trovato il modo di farle funzionare come rudimentali unità di calcolo. Esperimento fatto proprio da AMD stessa. Ovviamente rivelatosi un fallimento perché incapace di fare qualcosa di utile senza dover scomodare mille strutture e data path non pensati per quello scopo e quindi alla fine risultavano più lente di un bradipo per fare 4 conti della serva. Ma ecco che si fa di necessità virtù e che con 4 modifiche (che hanno richiesto giusto 2 annetti) una TMU diventa una unità sufficientemente capace di fare qualche conto in autonomia. 3. Le TMU che sono unità in sviluppo da che esiste l'accelerazione grafica sono molto ottimizzate e abbastanza contenute in dimensioni ed essendo fixed function basta riempire una struttura texture con i dati come fosse un disegno ad hoc, inviarglielo e il risultato te lo trovi automaticamente "dall'altra parte", dove l'altra parte è la cache, cui ri-accedi con gli shader in tempo zero. Il rovescio della medaglia di questa implementazione posticcia è che la potenza di calcolo ottenibile è una frazione di quella che si ha con una unità ad hoc che usa strutture ad hoc con data path dedicati e maggior integrazione, controllo e autonomia da parte della pipeline. MA che costa tempo, fatica e transistor per essere realizzata. E no, le TMU modificate non completano l'algoritmo BVH, serve ancora del lavoro con gli shader. Ora anche tu sei erudito sul fatto che le unità NON dedicate di AMD sono state finora surrogati delle unità reali presenti nelle schede Nvidia consumer dal 2018 e infatti AMD parla proprio di cambiamento radicale con UDNA, che userà unità di questo tipo, non i surrogati che ti ha (s)venduto fino adesso. INT8 non è un tipo ottimizzato per l'AI. E' un altro modo di surrogare i risultati con qualcosa che non è adatto allo scopo. Se fosse stato così semplice non avremmo mezzo modo di ricerca sulle architetture AI che cerca di implementare tutto come fosse FP (fino a FP4), non ci sarebbero le unità matriciali FP (che costano una follia in termini di spazio e consumo di risorse) ma costerebbe una frazione mettere più ALU INT negli shader vettoriali. Tra le aziende impegnate a suon di miliardi a NON usare gli INT, sì, c'è anche AMD nelle sue schede MI. Sarà perché la scelta degli INT per fare i calcoli AI è roba da poveracci che non si usa più neanche nei tostapane connessi. Il fatto che tu pensi che un algoritmo che è addestrato e pensato per svolgere i calcoli in FP possa essere adatto agli INT8 e ottenere gli stessi risultati mostra ancora una volta (se ce ne fosse ulteriore bisogno) di quanto non sai un CAZZO della materia. Tanto è che la stessa AMD fa quello che può con quello che ha (o meglio, si è data) specialmente sulle console dove ovviamente tutto è un surrogato a basso costo di quanto dovrebbe stare in un sistema decente ed escono già vecchie al day one. AMD sulle console può fare quello che vuole che non ha un contraltare con cui confrontarsi, ma sul desktop c'è Nvidia che la sta facendo a pezzi da tutti i punti di vista, e di figuracce ne ha fatte già parecchie a partire degli annunci che poteva fare a meno della AI usando gli algoritmi di Matusalemme (senza parlare di quelli che le unità RT sono inutili, Vega fa tutto con gli shader.. dove sono finiti quelli? Ah, sì, sei rimasto solo tu a difendere la cosa). Non è il caso che si presenti con roba che azzoppi ulteriormente prestazioni e qualità d'immagine oltre alle schifezze che ha già proposto in passato. Giusto è supportare solo l'architettura che è in grado do farlo in maniera decente, e questa è RDNA4. Quello che è venuto prima è ormai utile come ferma porta, convincitene. E UDNA metterà una pietra anche sul supporto di RDNA4, che in confronto (si spera se stanno facendo tutto a modo) sarà come un triciclo. RDNA1 è una schifezza nata vecchia e risultata peggio di quanto AMD stessa aveva previsto. Senza una che sia una funzione avanzata, va quanto Pascal 3 anni dopo usando il doppio dei transistor. Paragonarla a Turing è come paragonare una bicicletta ad un shuttle e dire che la prima è il risultato di una attenta operazione di massima ingegneria di semplificazione e riduzione dei costi. Rendersi ridicoli più di così non si può. E parla solo di quel che conosci: il path tracing (che è una modalità di calcolo RT, non definisce un bel niente riguardo a "quanto RT c'è nello schermo") funziona comunque in modalità ibrida lo stesso. La differenza è che Nvidia con le sue unità di calcolo (tra matrici e RT) può permettersi di usare tecniche di calcolo RT molto avanzate (anche se decisamente pensanti), mentre AMD deve mettersi alla finestra e al massimo sputare su chi sta passando sotto a tutta velocità perché non può neanche pensare di implementare tali scelte se non vuole dimostrare in maniera palese anche a quel 7% che ancora non ha tolto gli occhiali rossi, che le sue GPU sono roba antiquata da ammodernare il prima possibile. Ovviamente poi quando anche AMD accenna a riuscire a fare qualcosa di simile, tutto il resto è dimenticato e il nuovo è uguale alla concorrenza che a detta di voi ignoranti come la peste, è sempre un passo indietro mentre AMD è quella che domina in ricerca, sviluppo e soprattutto efficacia delle soluzioni. Saluti, e studia prima di scrivere stronzate da correggere con altre stronzate che cercano di girare la frittata quando invece non fai che confermare quanto ho scritto. Ultima modifica di CrapaDiLegno : 02-12-2025 alle 20:18. |
||
|
|
|
|
02-12-2025, 23:37
|
#10 | ||||||||||
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 4111
|
Quote:
 Quote:
Forse con una foto, ce la puoi fare (o forse no) 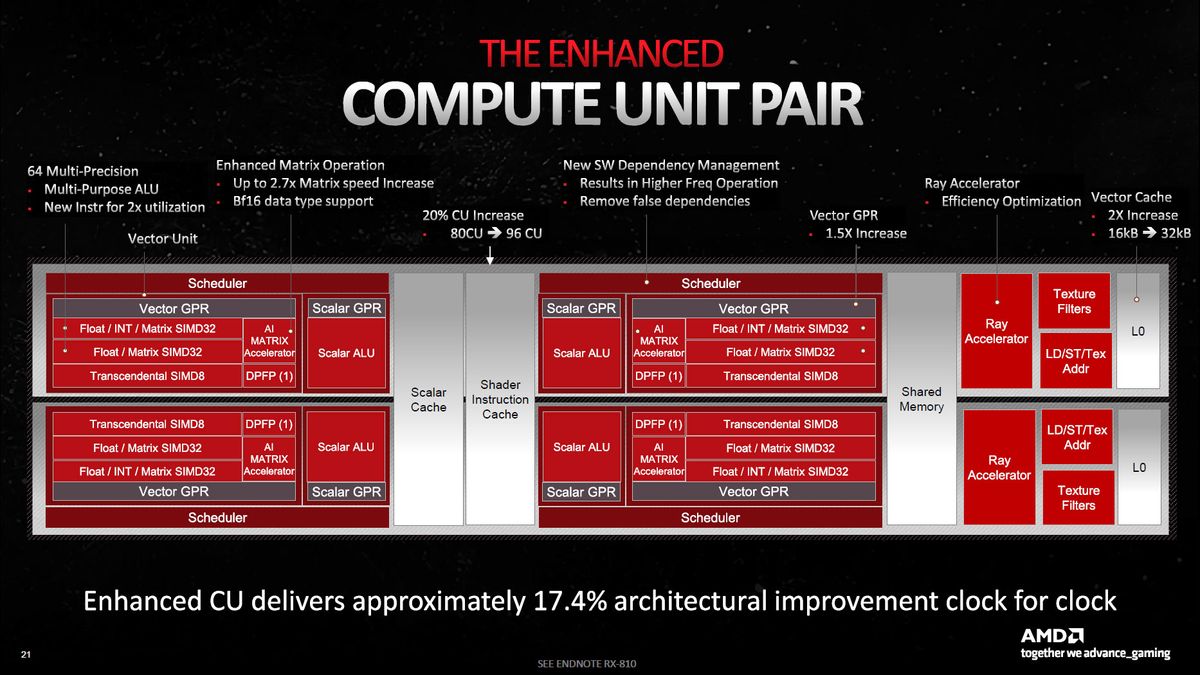 E non c'è scritto da nessuna parte che devono essere separate dalla pipeline di elaborazione. Fattene una ragione. Quote:
Amd (all'epoca ATI) da sempre predilige il fillrate. Lo fa da sempre, a partire dalle Rage 128 (RF Maxx), con le Radeon (tech. HyperZ Buffer), il RingBus delle X1000 ecc ecc. E' ovviamente una filosofia costruttiva che portano avanti, e continueranno. Quote:
Quote:
Quote:
Quote:
Quote:
E quindi le 1650, 1650S, 1660, 1660S, 1600Ti, fantastiche Turing senza funzionalità avanzate, sono delle stronzate? ERGO chi le compra sono degli stronzi...perfetto: sono state le più vendute della gen Quote:
Quote:
il Path Tracing è uno scherzo, dietro c'è solo Marketing da mentalisti, perfetto per le deboli menti. Alla fine, la morale, non l'hai ancora capita? Senza le mazzette di Nvidia tutte quelle "tech", non se le fila nessuno. E lo vediamo bene nei titoli non prezzolati. Ma è ancora più visibile in tutte le pratiche mendaci per danneggiare la concorrenza. Ma come si fa a mettere nelle brochure le perfomance di riferimento e comparativa in fake frame
__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET Ultima modifica di Max Power : 02-12-2025 alle 23:53. |
||||||||||
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 06:03.















