





|
|||||||


|



|
|
 |
|
|
Strumenti |
 10-03-2016, 01:19
10-03-2016, 01:19
|
#741 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
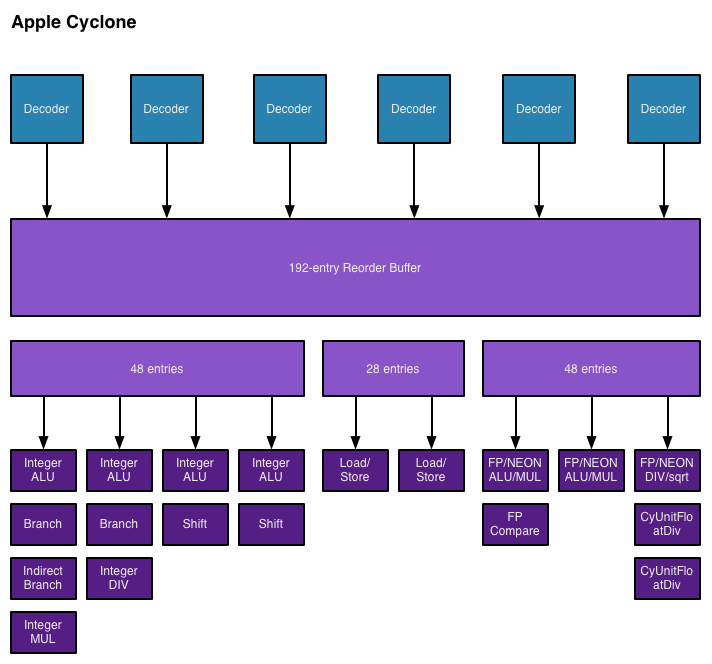
A7 CPU 28nm - 17mm2 A8 CPU 20nm - 12.2mm2 A9 CPU 16FF+(meno di mezzo nodo di scaling) - 13.5mm2 (con il triplo di L2) Il fattore di integrazione che hai usato è riferito allo scaling della SRAM, la logica scala meno... Ultima modifica di Ren : 10-03-2016 alle 01:35. |
|

|

|
10-03-2016, 06:54
|
#742 |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
li ho ricavati con un programma di fotoritocco, non credo di aver sbagliato così tanto
Se non scalano bene neppure le CPU da smartphone, che hanno obiettivi di frequenza assi più modesti, non avrebbe granchè senso la corsa alla miniaturizzazione...detto questo i core skylake sono piccolissimi: siamo passati dai 17,5mmq a 6,85mmq da SB a skylake (core+l2) per un fattore di integrazione pari a 2,5x (in realtà superiore considerando che skylake ha 2 pipeline e 1 decoder e tante altre cose in più) Ultima modifica di tuttodigitale : 10-03-2016 alle 06:59. |
|
|
|
10-03-2016, 07:34
|
#743 | |||||||
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
AMD ha anche un brevetto per il checkpointing che serve per ridurre tale latenza, ma non credo che faccia la stessa cosa, altrimenti il brevetto non sarebbe stato approvato Quote:
Quote:
Quote:
Quote:
Quote:
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|||||||
|
|
|
10-03-2016, 10:14
|
#744 | |
|
Senior Member
Iscritto dal: Oct 2003
Città: Milano
Messaggi: 4080
|
Quote:
riesci in due parole a spiegare cos'è e come funziona il checkpoint? EDIT: *ovviamente meglio se dedicando tutte le risorse necessarie al ramo indicato dal branch-predictor come probabile e le rimanenti all'altro ramo. Ultima modifica di digieffe : 10-03-2016 alle 10:56. |
|
|
|
|
10-03-2016, 12:17
|
#745 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
 Controlla le immagini che qualcosa non va. Apple con i 20nm(core simile) ha ridotto di circa 0.7. ps. Skylake è 8.2mm2 Ultima modifica di Ren : 10-03-2016 alle 12:19. |
|
|
|
|
10-03-2016, 12:24
|
#746 | |
|
Senior Member
Iscritto dal: Apr 2003
Città: Roma
Messaggi: 3237
|
Quote:
|
|
|
|
|
10-03-2016, 13:52
|
#747 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Il check pointing non l'ho approfondito... DOvrei leggere il brevetto, ma spesso sono inutilmente complicati... Se qualche anima pia mi linka un PDF di qualche paper...  Oppure quando ho tempo me lo cerco da solo... Oppure quando ho tempo me lo cerco da solo...
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
10-03-2016, 13:54
|
#748 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
Il checkpointing AMD sono curioso di vedere come funziona.
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
10-03-2016, 13:57
|
#749 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
10-03-2016, 14:03
|
#750 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
BJT2
Certo se funziona in questo modo, sarebbe davvero un mostro. La complessità per molti aspetti fondamentali sarebbe paragonabile a quella di una CPU con SMT... Tuttavia, caricare un dato inutile nel 90% dei casi, è un costo non trascurabile. Sei sicuro al 100%? Quote:
di skylake ho preso, le dimensioni dei core M, che dovrebbe essere semplicemente un core skylake con HDL, quindi piuttosto rappresentativo della differente complessità tra le architetture Intel ed Apple. Aldilà dei numeri che contano fino ad un certo punto, volevo semplicemente affermare che le cpu risc di apple dall'A7 sono dei mostriciattoli, molto più grandi di jaguar. |
|
|
|
|
10-03-2016, 14:09
|
#751 | |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6817
|
Quote:
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
|
10-03-2016, 14:35
|
#752 | |||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
Quote:
In pratica ritornando a BD, AMD avrebbe progettato questa architettura con in mente i 45-22 SOI, mentre ZEN per i finfet 14-10nm Quote:
 Quote:
 ) )Il gap dell'efficienza energetica a basse frequenze, è stato drasticamente mitigato dalle nuove tecnologie sul risparmio energetico che funzionano meglio con numerosi stadi. il FO4 influenza l'ipc, per questo spero che il +40% nel ST sia ottenuto con stadi poco complessi che permettono di lavorare a frequenze o vcore nettamente più favorevoli E' un compromesso. Spero che scelgano il migliore: FO4 10 - ipc +100% |
|||
|
|
|
10-03-2016, 18:54
|
#753 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
Quote:
L'ipotesi che mi sono fatto è questa. Se AMD si limita a 95W, significa che almeno 3,5GHz di base, li abbia...è un no-sense fermarsi quando le prestazioni aumentano ancora significativamente, con 30-45W di margine...a meno di non avere una superiorità tecnologica tale da permettersi questo ed altro...(a64 docet), ovviamente dovremmo rivedere a rialzo le stime... Per quello che ne sappiamo (davvero MOLTO poco), ZEN potrebbe raggiungere i 5 GHz in turbo mode... Al momento la patch riferisce latenze lato FPU identiche a quelle di Bulldozer. Potrebbe non essere veritiera, ma se fosse confermata vuol dire che ZEN è un demonio di velocità, esattamente come il suo predecessore Con tutto il bene del SOI, il bulk a 28nm si è dimostrato della stessa pasta del più prestante (sulla carta) 32nm, ad alte frequenze: il a10-7890k, gira a 4,1/4,3GHz. Siceramente, mi aspetto ulteriori aumenti di clock (turbo) passando ai finfet, qualora mantenesse un FO4 simile a BD. |
|
|
|
|
10-03-2016, 21:44
|
#754 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
Quote:
attualmente penso che l'ipc salga del 40% nel ST e del 100% nel MT (sono ritornato alle mie vecchie convinzioni, scaling del SMT migliore per AMD). In pratica, tra un core ZEN e uno skylake, le differenze nel multithread sarebbero irrisorie. Dirò di più, per i più pessimisti. IBM ha aumentato l'ipc nel ST del 40-50% dal power7/+ al power8..e non mi pare che abbia subito penalità a livello di clock (ha una frequenza massima di 5GHz vs 4,42 del predecessore)... certo partiva da un livello infimo di ipc, ma non avevano keller  . D'altra parte non si può non notare quanto sia ampio il core ZEN.. . D'altra parte non si può non notare quanto sia ampio il core ZEN.. un octa core nel MT paragonabile ad uno skylake, con una frequenza 3,5 GHz base in 95W, è un mostro efficientissimo, altro che aspettative basse. Quelle delle frequenze alte, 3,5GHz+ per l'octa core, è una inevitabile conseguenza delle commercializzazione di un opteron da 32 core. Se partono bassi (3GHz) con un octa core... |
|
|
|
|
10-03-2016, 21:57
|
#755 | |
|
Senior Member
Iscritto dal: May 2005
Messaggi: 12173
|
Quote:
__________________
AMD 9950X3D - MSI X870E CARBON WIFI - 198 Gb - 5080 - Dual 4K - Leica RTC360 & BLK360 
|
|
|
|
|
11-03-2016, 00:13
|
#756 |
|
Senior Member
Iscritto dal: Oct 2003
Città: Milano
Messaggi: 4080
|
@tuttodigitale
se intel produce/rra sul suo 14nm un 10core@3ghz 140W ed un [email protected] 140w, non capisco come amd possa produrre un throughput analogo al secondo in [email protected] non è più verosimile che a 95w si fermi a 3.0ghz? (con throughput inferiore all'intel x8) |
|
|
|
11-03-2016, 01:08
|
#757 | |
|
Senior Member
Iscritto dal: Jul 2012
Messaggi: 2824
|
Quote:
Inviato dal mio XT1092 utilizzando Tapatalk
__________________
AMD R5 3600 | MSI B450 Tomahawk Max II | 16gb Viper 3000MHz CL17 | AMD XFX RX 5700XT DD 8GB | SSD Patriot 240GB | SSD Kingdian 500GB | Super Flower Amazon 550W | Zalman Z11 |
|
|
|
|
11-03-2016, 08:17
|
#758 | |||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
Quote:
Più probabile che l'ipc sia bassino, e sicuramente lo sarà nel ST. Mi aspetto un bel boost con il SMT, proprio perchè ipotizzo che ci sia una scarsa efficienza nell'usare le 10 porte. Se i 2,7GHz saranno la frequenza base di Carrizo/BristolRIdge in 15W, AMD già con i 28nm, raggiungerebbe senza grossi sforzi le più efficienti soluzioni Xeon a 22nm.... Le prestazioni altissime nel MT, sono proprio il minimo che possiamo attenderci...tanto varrebbe fare un die shrink di quello che sarebbe il più prestante excavator..... Quote:
il meglio dei 14nm Intel, deve ancora venire. Quote:
Per curiosità più tardi vedrò un pò di test sui prodotti da 35-45W di Intel, per vedere quanto rullano rispetto alla generazione precedente Ultima modifica di tuttodigitale : 11-03-2016 alle 08:36. |
|||
|
|
|
11-03-2016, 08:25
|
#759 | |
|
Senior Member
Iscritto dal: Jul 2012
Messaggi: 2824
|
Quote:
Inviato dal mio XT1092 utilizzando Tapatalk
__________________
AMD R5 3600 | MSI B450 Tomahawk Max II | 16gb Viper 3000MHz CL17 | AMD XFX RX 5700XT DD 8GB | SSD Patriot 240GB | SSD Kingdian 500GB | Super Flower Amazon 550W | Zalman Z11 |
|
|
|
|
11-03-2016, 08:38
|
#760 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4394
|
Quote:
|
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 23:28.















