





|
|||||||


|



|
|
 |
|
|
Strumenti |
 20-11-2024, 13:16
20-11-2024, 13:16
|
#1 |
|
www.hwupgrade.it
Iscritto dal: Jul 2001
Messaggi: 75166
|
Link alla notizia: https://www.hwupgrade.it/news/skvide...00_132947.html
Secondo un noto leaker piuttosto affidabile, la scelta di non proporre schede video di fascia alta per la prossima generazione è dovuta all'accelerazione nello sviluppo dell'architettura UDNA. Stando a quanto riportato, la società di Sunnyvale passerà direttamente a UDNA con le Radeon RX 9000. Click sul link per visualizzare la notizia. |

|

|
|
20-11-2024, 15:04
|
#2 |
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 3526
|
RDNA3 ha le unità IA parallele agli RT core.
Ma nessuno se lo ricorda, AMD compresa 
__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET |
|
|
|
|
20-11-2024, 15:34
|
#3 | |
|
Member
Iscritto dal: Dec 2022
Messaggi: 240
|
Quote:
|
|
|
|
|

|
20-11-2024, 16:02
|
#4 |
|
Senior Member
Iscritto dal: Apr 2002
Messaggi: 4385
|
"Potrebbero esserci dei piccoli intoppi"
Attendo "con ansia" i test tra RX 10900 XTX e RTX 7090. |
|
|
|
|
20-11-2024, 21:15
|
#5 | |
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4053
|
Quote:
1. AMD non ha nessuna unità AI specializzata. I soli calcoli AI che è in grado di fare sono tramite gli shader (semplici unità vettoriali) usando ottimizzazioni per poter calcolare x2 valori a FP16/BF16 invece che FP32 (il vecchio e ormai vetusto math packing). E solo da RDNA3 in poi, perché prima non godeva neanche di questo boost di 2x. 2. AMD non ha neanche nessuna unità RT specializzata. Forse pochi lo sanno, anche se è documentato proprio nella descrizione del funzionamento di RDNA, che AMD usa le TMU (le unità texture per essere chiari) per eseguire qualche timido calcolo sulle BVH in parallelo agli shader. Ma la capacità delle TMU potenziate (2 su 4 per ogni CU) di eseguire questo tipo di calcolo è molto limitato dovendo usare un formato primitivo come una texture debitamente formattata per estrarre e passare i dati da elaborare, e quindi deve ripiegare su un uso molto più intensivo degli shader che perdono un sacco di tempo per fare questi calcoli e non quelli prettamente grafici. In più l'uso ibrido delle TMU ruba capacità di elaborazione anche alla parte di rasterizzazione. E' un po' come all'inizio dell'uso delle GPU per il calcolo generico quando si tentava di usare le unità a funzione fissa per elaborare dati che non fossero di tipo grafico, l'antico supporto a OpenGL. E come al tempo i risultati sono penosi. Alla fine si vedono i risultati rispetto a chi ha delle vere unità di elaborazione che funzionano realmente in parallelo agli shader e sono ottimizzate per fare quello che gli shader fanno male, quindi unità ottimizzate per il BVH e unità matriciali per fare calcoli AI, non limitate moltiplicazioni tra ALU nello stesso shader. Tutte che possono lavorare in parallelo. Nei giochi appena si attiva un qualsiasi vero effetto di raytracing le Radeon vanno in crisi completa. Parlo di veri effetti, non di roba all'acqua di rose che calcola in pixel ogni 10000 con la tecnica dei raggi oppure usa mappe radiosity che occupano GB di VRAM per effetti pre-calcolati. Tutto questo non è colpa di altri se non del fatto che AMD ancora è carente dal punto di vista dell'implementazione di unità RT decenti. Forse gioca un ruolo fondamentale anche qualche brevetto depositato da chi queste unità le ha inventate perché anche se si è trovata spiazzata dall'introduzione del raytracing dopo tutti questi anni la soluzione "posticcia" di usare le texture dovrebbe già essere stata superata. Nell'esecuzione di un qualsiasi programma che usi algoritmi di AI, anche la migliore Radeon da 300W va peggio di una 4060 da 120W, segno che se le unità di calcolo apposite non ce le hai, gli algoritmi di AI non li esegui in tempi decenti con gli shader che non sono ottimizzati per questo tipo di calcoli neanche se fai math packing. Non esistono scorciatoie per l'enorme capacità computazionale richiesta da questi algoritmi. Speriamo quindi che con UDNA AMD metta tutto quello che serve per raggiungere, almeno sulla carta, le caratteristiche HW che la concorrenza ha introdotto 10 anni prima. Per quanto riguarda il discorso una sola architettura o 2 diverse secondo la destinazione d'uso, Nvidia ne ha due specializzate che hanno diversi elementi in comune ma anche molti elementi che le differenzia notevolmente, tanto che Hopper e Blackwell non possono fare quello che fa una "semplice" 4090, e vale naturalmente anche l'opposto. Quindi non so se è buona cosa fare una sola architettura come ai vecchi tempi con GCN dove era chiaro che non si riusciva ad avere il meglio né dell'una né dell'altra e i consumi sparavano verso l'infinito e oltre per avere prestazioni grafiche decenti. |
|
|
|
|
|
23-11-2024, 03:06
|
#6 | |||
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 3526
|
Quote:
Ovviamente ti smentisco subito, premetto che non entro nel merito del test utilizzato, se premia una o l'altra architettura. Al momento c'è poco o nulla di dedicato. Ma quantomeno è un riferimento comune: 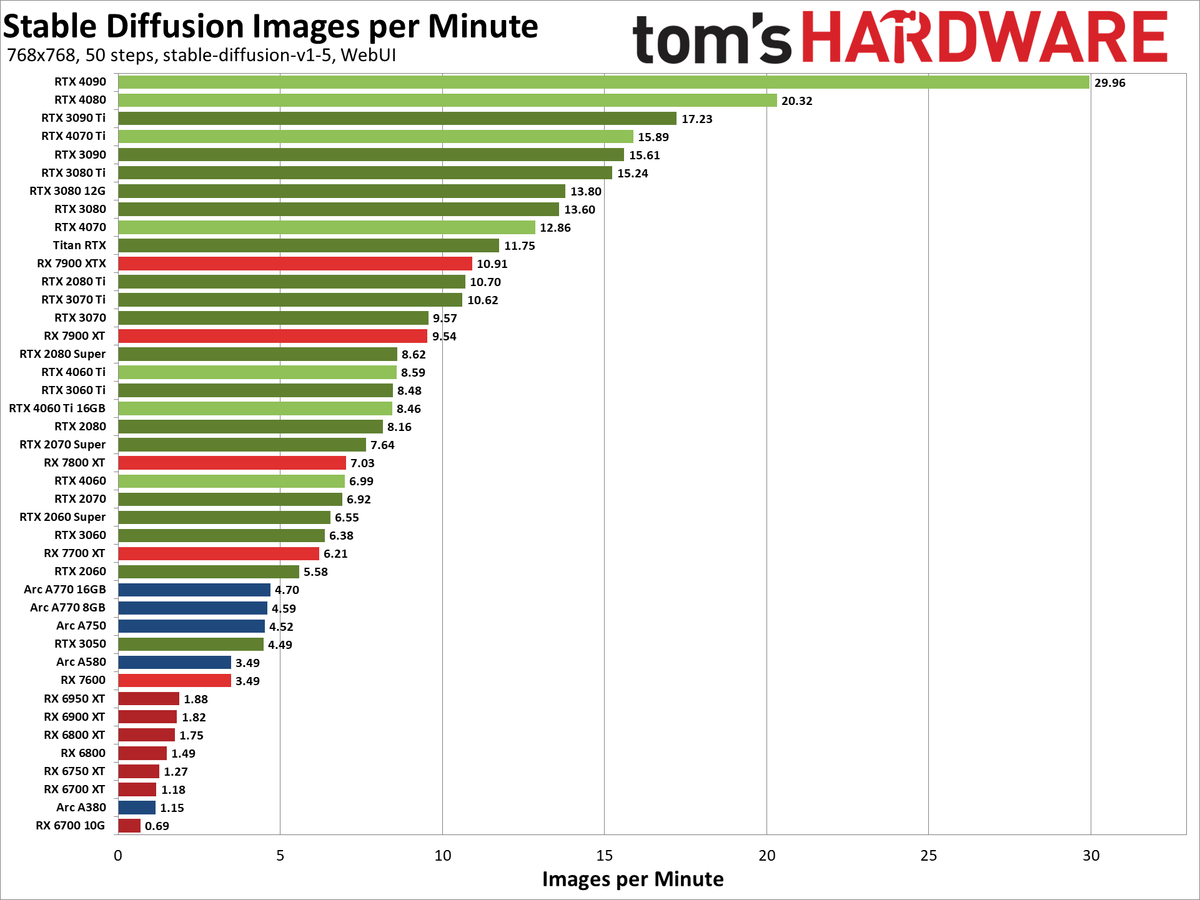 E' palese la differenza fra RDNA2 ed RDNA3 Quote:
 E adesso passiamo alle eresie Quote:
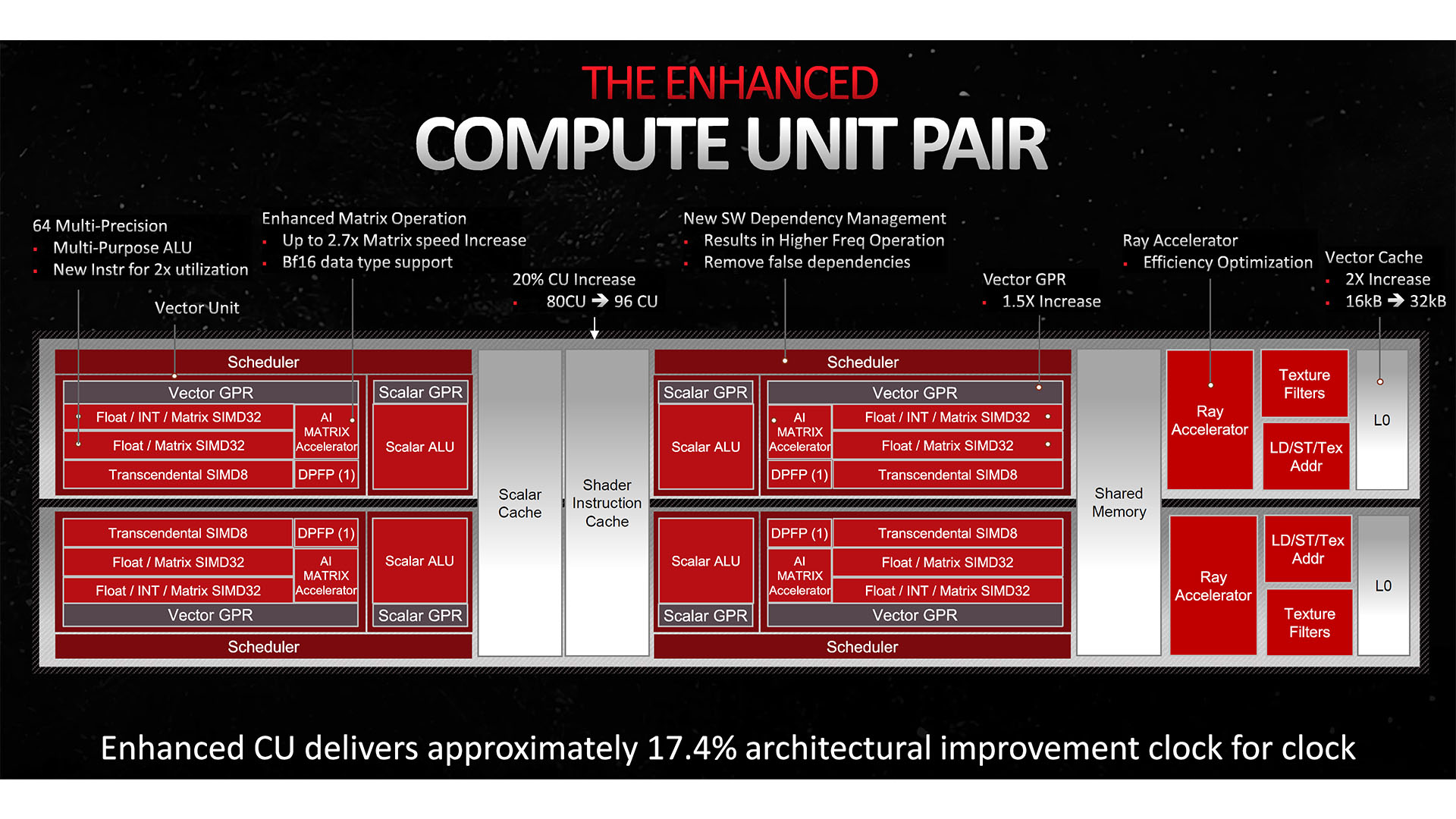 Come ho già spiegato più volte ci sono differenze architetturali: - Nvidia -> RT Paralleli alla pipeline - AMD -> RT Core in fondo alla pipeline - Intel -> RT Core Ibridi con gli shaders Tornando ai VG, in realtà è il software a fare la differenza maggiore (o meglio le sponsorizzazioni... )Finchè si andranno a cucire su un'architettura e artificiosamente peggiorare le altre, si vedranno delle situazioni letteralmente ridicole (il caso Alan Wake 2 è letteralmente eclatante, a tratti demenziale) Senza poi parlare del risultato effettivo...abbiamo esempi di Path Tracing / Full RT peggiori del Raster (ma ovviamente ben più lento) come Plague Tale RT, tanto per dirne una. Ma ce ne sono altri. Per concludere, tutta questa filosofia non serve ad un fico secco se poi i risultati sono soggetti a macchinazioni. Ergo, che non si venga a raccontarla
__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET Ultima modifica di Max Power : 23-11-2024 alle 04:53. |
|||
|
|
|
|
25-11-2024, 20:42
|
#7 |
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4053
|
La racconti eccome.
La differenza tra RDNA2 e RDNA3 sta solo nella capacità di quest'ultima di eseguire con le stesse ALU il doppio dei calcoli rispetto alla prima in FP16. NON CI SONO UNITA' DEDICATE. Solo una ottimizzazione nel picco del calcolo FP16 (e solo di picco, nella realtà infatti non va il doppio), supporta finalmente i BF16 (che RDNA2 non supportava) e usa le istruzioni WMMA CHE NON USANO UNITA' MATRICIALI MA LE UNITA' VETTORIALI DEGLI SHADER. Scrivo in maiuscolo così elimino ogni dubbio su qualche possibile male interpretazione di cose che evidentemente non conosci. Leggi qui e comprendi come fa RDNA3 a eseguire le operazioni di moltiplicazioni matriciali: https://gpuopen.com/learn/wmma_on_rdna3/ Quando l'hai capito torna e di che ci sono ancora unità dedicate al calcoli AI. Per quanto riguarda le unità RT anche qui è evidente che fai finta di non capire: Nvidia ha le unità in parallelo perché le ha pensate e implementate così dal day one, ovvero con unità dedicate appositamente per supportare quel tipo di lavoro in collaborazione con il resto della pipeline, non in sostituzione o sacrificio di altre funzionalità durante il loro uso. AMD non ha potuto pensare ad una cosa del genere, visto che per il raytracing in tempo reale aspettava forse di avere qualche centinaio di migliaia di shader. Ma è stata fregata dalle idee più lungimiranti di Nvidia, iniziate con le unità matriciali e poi quelle per l'RT. Due cose che vanno a braccetto se si vuole ottenere qualche risultato qualitativo e non cubetti colorati ad caxxum giusto per dire "Eh, ma sono realizzati con i raggi". Per fare quello che ha fatto Nvidia non ci vuole certo un giorno. E neanche in mese. E neppure un anno. Però per evitare di presentarsi con il NULLA per 2 generazioni intere ha ben pensato di usare un vecchio metodo di calcolo (un antiquato metodo a dirla tutta) che è quello di modificare una unità a funzione fissa già esistenti per supportare qualche algoritmo semplice di calcolo. Come detto si era già tentato molto prima dell'arrivo degli shader unificati e programmabili. Perché semplice? Perché altrimenti diventa una unità enorme e visto che non è bel pensata all'interno del flusso saranno comunque transistor sprecati (e già non sono pochi un RDNA). Inutile raddoppiare la dimensione se poi si ottiene un miglioramento del 10% su un già non brillante 30%. E quale unità migliore per la modifica se non la TMU che è a diretto collegamento con la L2? La pensata è stata molto buona. Ha permesso ad AMD di non fare la figura della pera cotta caduta dall'albero all'arrivo delle unità raytracing di Nvidia "solo" 2 anni prima. Con RDNA2 ormai finita alla presentazione di Turing, quella modifica dell'ultimo minuto è stato il massimo ottenibile. Si sperava però che con RDNA3 facesse quello che doveva fare, ovvero mettere unità dedicate A FIANCO degli shader non dove capitava perché era il punto con più banda, ma così non è stato. C'è stato solo il giochino di mettere quanta più cache possibile addirittura tramite chiplet esterni e di ulteriormente portare i propri shader a funzionare come quelli delle concorrenza. Ci penserà finalmente RDNA4 (credo stavolta senza l'idea balzana dei chiplet per i memory controller + cache)? Forse, si spera, giusto per cominciare a sistemare l'architettura come si deve in vista di UDNA tra un altro paio di anni abbondanti (così saranno 8 dall'introduzione di Turing). Intanto però gli altri non stanno a guardare, Neanche la "disperata" Intel. Anche lei ha unità RT e matriciali vere già dal primo giorno. |
|
|
|
|
26-11-2024, 02:43
|
#8 | ||||
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 3526
|
Quote:
Piuttoso, ti invito a ritornare dopo un corso intensivo di italiano, ma non troppo accelerato, non vorrei che ti perdessi qualcosa per strada Inoltre ho portato delle prove sulle evidenze, ben interpretabili da chiunque. Vuoi contestare anche quelle?  Quote:
Se proprio vogliamo dirla tutta è Intel che con i core Ibridi che ha fatto la scelta "migliore" non per l'efficenza assoluta in un contesto cucito ad hoc, ma come flessibilità, tuttavia al costo di un maggiore n° transistor. Detto questo non ha (più) la forza commerciale per imporsi. (...ovviamente cosa già scritta e ribadita più volte dal sottoscritto...) E qui torniamo al discorso delle sponsorizzazioni (+ qualità driver aggiungerei) per pensare di "influenzare" il mercato. Quote:
1) L'infinity cache ha lo scopo di fornire banda passante (quindi su due logiche: abbasare i costi ram oppure massimizzare le prestazioni) 2) Dalle 6000 alle 7000 a parità di fascia, l'infinity cache è stata RIDOTTA per quasi tutte le schede (6700XT 96MB / 7700XT 48MB - 6800XT 128MB / 7800XT 64MB - 6900XT 128MB / 7900XT 96MB) 3) Nvidia ha COPIATO l'infinity cache di AMD per i motivi al paragrafo 1 4) Prendendo in considerazione i rumors della B580, non mi stupirei che anche intel adottasse l'infinity cache di AMD, sempre per i motivi al paragrafo 1 Quote:
. . . Quindi fammi capire, Nvidia ti regala i punti mulino bianco per ogni carattere che spendi per loro? No perchè vedo parecchio impegno, certamente mal riposto (per via dei risultati ovviamente) ma certamente ti impegni
__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET Ultima modifica di Max Power : 26-11-2024 alle 03:24. |
||||
|
|
|
|
26-11-2024, 20:53
|
#9 | |||
|
Senior Member
Iscritto dal: Jan 2011
Messaggi: 4053
|
Quote:
Poi, l'infinity cache non l'ha mica inventata AMD. Al solito ha dato un nome fantascientifico ad una tecnologia che esiste da tempo. Le cache sulle GPU crescono da sempre perché è il modo più economico per aumentare la banda istantanea. Tranne quando qualcuno decide, come AMD, che è meglio allargare il BUS da 256 bit della 6900XT ai 384 bit della 7900XTX (questo ti è fuggito eh?) mettendo i MC nei chiplet esterni insieme alla cache. E sono su chiplet separati altrimenti l'N31 diventava più grande del il GA203 e in tal modo invece di perdere 100 per ogni GPU venduta ne avrebbe persi 150. Comunque prima o poi AMD troverà la pace con le cache, dopo che ogni nuova architettura finora realizzata ha layout e collegamenti alla cache sempre diversi, ma che poi si rivelano sempre poco performanti nonostante le dimensioni e le bande teoriche. Le lezioni di comprensione del testo in italiano dovresti prenderle tu, visto che io ho parlato abbastanza chiaramente (e con parole semplici) di come AMD abbia modificato i suoi shader per avvicinarsi ancora una volta al funzionamento di quelli di Nvidia partendo da quel cesso completo di CGN. Se non sai come funzionano gli uni o gli altri (e da quanto hai detto prima, non non lo sai) studia un po' di più prima di dire che sono gli altri a non capire l'italiano. L'idea della infinity cache come qualcosa di innovativo ed esclusivo ce l'hai solo tu. Intel usa la cache esterna L3 nelle sue GPU da tempo con le Iris. Nvidia non ha (per ora) cache di terzo livello nelle sue GPU, solo L1 e L2, che crescono sempre per ridurre la penalità di bus verso la VRAM relativamente sempre più lento, per cui l'idea che Nvidia abbia copiato AMD te la sei fatta al solito da solo giusto perché non comprendi come funzionano le cose nella realtà. Quote:
E la stessa cosa vale per l'accelerazione RT. Quote:
Ultima modifica di CrapaDiLegno : 26-11-2024 alle 21:01. |
|||
|
|
|
|
09-12-2024, 00:55
|
#10 | |||||||
|
Senior Member
Iscritto dal: Jan 2003
Messaggi: 3526
|
Quote:
Quote:
AMD ed Nvidia mediamente impiegano circa 2 anni per progettare un'architettura (ex-novo), e certamente se ne sviluppa uno alla volta, altrimenti andrebbero in concorrenza di risorse gli stessi reparti...una cosa talmente banale che è fin ridicolo doverla spiegare. Se è un aggiornamento di architettura, ovviamente anche meno. Che poi a livello di mercato ci siano delle tempistiche "commerciali" è tutto un altro paio di maniche. E se proprio volevano cambiare idea l'avrebbero fatto con RDNA3, ma probabilmente non capisci il significato di scelta. Così come intel ha scelto di fare diversamente. Quote:
Piccolo Recap RTX 2080 Ti (5.5 MB) RTX 3090 Ti (6 MB ) RTX 4090 (72 MB ) Fun Fact: Toms HW ha menzionato "Infinity Cache" anche su Nvidia https://www.tomshardware.com/feature...ything-we-know Nvidia poteva starsene con la miserabile cache precedente, ma evidentemente, la soluzione AMD funzionava e bene. Tantè che Intel, guardacaso combinazione, con le nuove B580/B570 ha fatto la stessa cosa Quote:
Quote:
Quote:
 Quote:
La vera realtà che hai una visione (e sono generoso) completamente imposta dal marketing, assolutamente ottusa. Siccome la teoria va bene, ma fino and un certo punto come ho detto prima, andiamo sul pratico, ti faccio io una domanda: Prendiamo in considerazione N°2 schede: la 4060 e la 3080. La 3080 è una scheda che ha capacità computazionali maggiori della 4060, overall; Mi spieghi allora perché la 3080 non può usare il DLSS 3.x e nemmeno il Frame Generator? STUPISCIMI
__________________
MASTER: Ryzen 5 9600X LC,Powercolor RX 7700XT,MSI PRO B650M-A WIFI,32GB Ram 6400 CL32 RIPJAWS X in DC,Samsung 980Pro 512GB G4 + 980Pro 2TB G4 + SSHD 2TB SATA + HDD 1TB SATA,Audio ALC897,MSI MPG A650GF,Win 11 PRO,TK X-SUPERALIEN + AQUARIUS III,MSI 32" Optix MAG322CQR,MSI VIGOR GK30 COMBO,MSI Agility GD20 PAD,MSI IMMERSE GH10 HEADSET Ultima modifica di Max Power : 09-12-2024 alle 13:40. |
|||||||
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 12:36.















