Quote:
Originariamente inviato da CrapaDiLegno

Ma dove?
Nella documentazione di 20 anni fa dove asseriva che serviva solo il 5% dei transistor per avere il supporto di 2 thread?
|
Ciao,
allo stato attuale, Hyperthreading (o SMT) occupa *meno* del 5% del die.
Per capirci, questa era l'allocazione dei transitor ai tempi del P4:
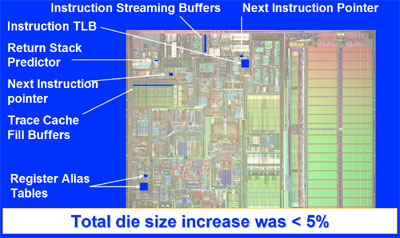
Il 5% di overhead era calcolato su un processore single core senza cache L3 né northbridge o switch PCIe integrato. Come puoi vedere dall'immagine, la logica "pura" della CPU occupava i 2/3 della superficie. Se guardi un die shot di Alder Lake, noterai che la CPU "vera e propria" occupa una parte molto più limitata (a occhio un 1/5) e quindi l'overhead dell'SMT, in termini di die space, è molto più basso.
Certo, nel tempo alcune strutture necessarie all'SMT che prima erano condivise sono state replicate, ma si parla davvero di poca roba (in termini numerici), per lo più focalizzate sul frontend. In linea generale, più complessa è la CPU, minore è l'overhead dell'SMT. Purtroppo le analisi in questo senso sono piuttosto vecchiotte, ma puoi trovare delle informazioni interessanti qui:
https://research.ac.upc.edu/pact01/papers/s7p2.pdf, dove puoi vedere che per un singolo processore "semplice" l'overhead può arrivare anche al 25% sulla sola CPU+L1, mentre il valore scende molto mano a mano che vengono simulati processori più complessi (sempre senza L2/L3/nb/ecc).
Il vero problema dell'SMT è che per dare buoni risultati deve essere accoppiato a un backend all'altezza, cosa che impiega *tanti* transistor e occupa molto spazio. Dove questo è stato fatto i risultati sono di tutto rispetto. Prendi Power8: l'SMT4 forniva un throughput quasi doppio rispetto al "noSMT", mentre l'SMT8 dava "solo" un 10-20% di throughput in più.
I processori con CPU eterogenee (es: E-cores) possono fornire prestazioni aggregate anche migliori di quelle ottenibili con HT/SMT, ma gestire tali CPU in ambito enterprise/cloud è piuttosto scomodo (es: immagina di migrare una VM che gira su un P-core su un E-core). Per questo in tali ambiti si è scelto di usare cores omogenei "potenziati" da SMT più o meno spinto, così da recuperare parte del throughput.
A livello enterprise, quello che mi aspetto davvero (e che sta accadendo) è la realizzazione di CPU con solo E-cores (o equivalente AMD, vedi Zen4D) per massimizzare il throughput e mantenere comunque una discreta latenza. Per certi versi gli E-cores sono più interessanti dei P-cores: prestazioni non troppo diversa da Skylake con 1/4 dell'area e del consumo.
La questione sicurezza / side channel tra i threads è un altro argomento spinoso, anche se generalmente a essere criticato non è l'SMT per se, ma alcuni effetti secondari visibili sulle CPU Intel di precedente generazione.
Ciao.