|
|
Quote:
|
Quote:
anche perchè la cpu non si cambia come la vga. bisogna farsi il pc nuovo in pratica |
Quote:
Quote:
:D Quote:
che è esattamente quello che farò pigliando un 6700k che ora si trova poco sopra i 300 :) |
Quote:
|
Quote:
Se costa poco più di 120 euro e va quanto una 960 e consuma quanto una 750 non mi pare male.:) Certo non fa per te, o meglio al caso tuo per sostituire la 290.:) Quote:
|
@mikael84
Stavo leggendo rumor in giro e dopo aver fantasticato ho pensato: "fammi chiedere a chi ne sà più di me nel forum!" :D Ipotesi 1° Volta con architettura simile ad amd che si rifletterebbe con un aumento enorme del numero di shader ed aggiunta dell'Asynchronous compute che eleverebbe le performance di un 50-100% rispetto a pascal Ipotesi 2° Volta con Cuda core migliorati con performance massimo 50% superiori a pascal anche se ipotizziamo cuda raddoppiati e mancanza di Asynchronous compute Tutte ste pippe mentali per aver letto che nvidia vuole aggiungere in futuro l'Asynchronous compute :confused: |
Quote:
|
Quote:
-o che con volta faranno appositamente una architettrua inefficiente (:asd:) che avrà gli ace per compensare (spiegazione data da alcuni in merito a gcn) -o che la cosa di cui sopra è una cazzata e che nvidia non ha gli ace perchè semplicemente non aveva nulla di gia pronto dopo maxwell che li avesse :stordita: |
Quote:
La prima architettura soffriva di overhead, questo rende praticamente impossibile alle radeon (tranne la 480) di sfruttare a corsia completamente il multi thread delle CPU, fattore che creava un buco di calcolo enorme. Gli ACE lavorano parallelamente su diversi tipi di calcolo per poi inviarlo allo shader core limitando le perdite. La GCN non è in grado come Pascal di memorizzare dati in cache e metterli in coda, tutto ciò che viene calcolato passa in shader core. La GCN pur operando a latenze in ms non soffre come maxwell la gestione delle code. Quindi se un'architettura ti lavora al 60%, con il lavoro parallelo puoi elaborare shader affinchè le ALU non rimangano in IDLE. Avere ACE hardware significa che si possono programmare 1000 shader su shader core 2 25000 asyncroni. La RX 480 utilizza 2 HWS e limita quasi del tutto il problema overhead, Nvidia invece sfrutta l'architettura quasi sempre al meglio, e con Pascal usa i buffer cache (in ns) per memorizzare dati ed elaborarli quando richiesto, ma se l'architettura viene sfruttata al 90%, che te ne fai di dati in memoria (rimangono in coda);) Quote:
Su Volta prevedo un simil Tesla con 1024 istruzioni per cuda e lavoro su 64 cuda, per fare in modo di avvicinarla maggiormente a GCN (thread max multiprocessor 2048). Ricorda che più istruzioni hai contemporanee meno accedi in cache, meno accedi in cache (10-12 cicli) ti ritrovi con latenze migliori, banda sgravata e minimi migliori. Quote:
|
Quote:
|
Quote:
Fortuna che c'è mikael che subito sotto spiega la reale situazione... ah no ma mikael e ren non sono affidabili, sparano supercazzole :asd: NVIDIA già supporta e usa pienamente l'async compute sebbene in modo diverso da AMD.... ne beneficia meno però perchè si, ha un'architettura molto più efficiente di AMD attualmente. |
@mikael
da quello che hai scritto si puo' dedurre che per le 480 gli ACE sono meno influenti che per le schede precedenti? |
Quote:
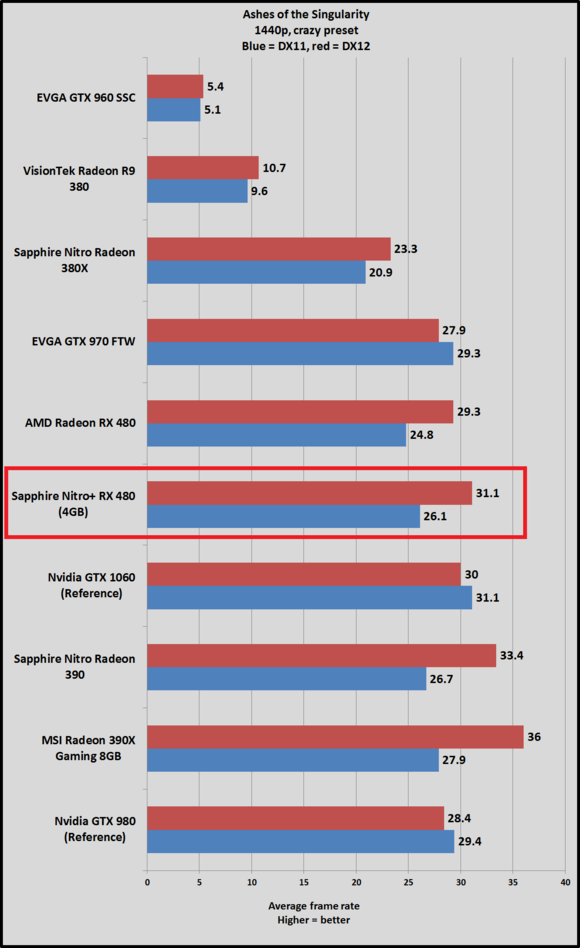 Se guardi la 480 Nitro e la 390 Nitro, che hanno quasi gli stessi FPS in DX11, nel passaggio in DX12 abbiamo + 25% circa per la 390 Nitro + 19% circa per la 480 Nitro Ci sono oscillazioni in base ai preset, quello è il più pesante, a 1440p con un preset più morbido la 480 va persino di più in DX11 della 390 per poi andare di meno in DX12 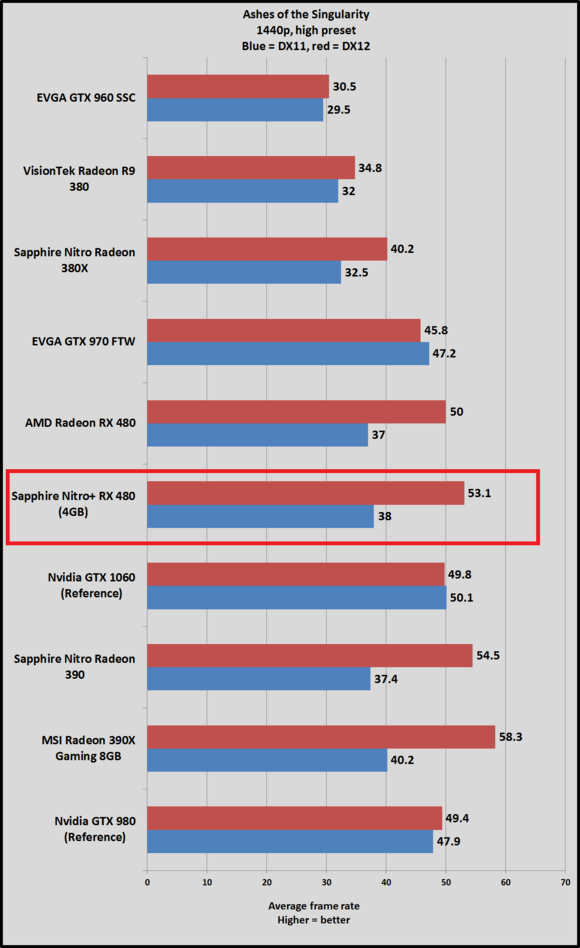 Si parla ovviamente di percentuali basse di per se, un fps e mezzo ma se si considera che 3 fps sono la differenza in quel gioco tra la 390 e 390x comunque non ci sono nemmeno 4fps... |
Quote:
quello che dici tu :Prrr:, che nvidia non ha ace perchè "non ne ha bisogno". Quindi se sulla prossima architettura li avesse le ipotesi sono quelle: o sono inefficienti e dovranno montarli per mettere na pezza (tua spiegazione in merito alla presenza degli ace in gcn) o semplicemente che non li aveva prima perchè non ne ve ne era "bisogno" era una bubbola, delle due l'una. Quanto detto da mikael non c'entra col discorso di cui sopra: ha detto che di volta non sa nulla come nessuno del resto e a quello mi riferisco, le future gpu Quindi io vorrei proprio sapere che diresti se su volta nvidia dichiarasse esplicitamente delle unità async compute hardware :D |
Quote:
JHH ha mille risorse, e si è sbattuto le poppone di lisa su. |
Quote:
Quello che penso io è quello che ho scritto sopra, ed è quello che Mikael e Ren ripetono da mesi :asd: |
Quote:
..eeeh comodo così, ha perso il meglio: la provocazione finale :read: :Prrr: |
Quote:
|
Quote:
Ha scelto quindi di dimezzare gli ACE per poter migliorare l'overhead.  Qua siamo di fronte ad un passo netto, tuttavia AMD ancora non riesce a fruttare completamente le ALU che i vettori forniscono. Le ALU su questa scheda sono molto performanti, tanto che a livello di puro calcolo supera tranquillamente sia 980 che 1060, avvicinandosi a schede superiori come 1070 e 980ti. Il trucco sta nello spremere il più possibile le unità di calcolo e cercare di fare lavorare il più possibile lo shader core. La 480 ha un handicap, ovvero il bus di memoria troppo stretto che spesso si satura, tale scheda dovrebbe integrare un 384bit o delle ddr5x belle spinte almeno 12gb/s. Ricordo che i dati di banda sono solo teorici e vanno rapportati all'MC e duna 290x con 263gb/s effettivi (non 312 teorici) è piuttosto più potente. Chi necessita realmente del calcolo asyncrono è la fury, una scheda sbilanciata con problemi di overhead e con delle ALU che devono essere sfruttate. A livello di ALU (float/vect4), una fury x è simile ad una 1080 ma ha un reparto geometrico scadentissimo, problemi con il backfaceculling, e delle rop's che sono specializzate per blending MSAA. 64 rop's AMD battono 128 rop's Nvidia su MSAA campionato 4x e passano ben avanti su MSAA8x. Chiaramente la scheda spesso in 1080p e 1440p va quanto una 980 custom, questo è dovuto ad architettura totalmente sballata e non sfruttata. Se un gioco dx11 usa principalmente i punti carenti di una fury è finita. La 1080 no, usa quasi tutta l'architettura e grazie ai GPC ogni stadio moltiplicatore rende la scheda equilibrata e potente su ogni calcolo. |
Quote:
|
| Tutti gli orari sono GMT +1. Ora sono le: 00:44. |
|
Powered by vBulletin® Version 3.6.4
Copyright ©2000 - 2024, Jelsoft Enterprises Ltd.
Hardware Upgrade S.r.l.