





AMD delinea ulteriormente il futuro delle proprie GPU

Emergono nuovi dettagli sulla futura generazione di architetture di GPU previste da AMD; debutto possibile giŕ per la fine del 2011?
di Paolo Corsini pubblicata il 17 Giugno 2011, alle 12:27 nel canale Schede VideoAMD
FSA, Fusion System Architecture: č questo il futuro per AMD in termini di architetture di GPU. Eric Demers, CTO della divisione graphics di AMD e pertanto responsabile della direzione futura delle GPU AMD in ambito desktop e professionale, ha evidenziato nel corso di un keynote al Fusion Developer Summit quali saranno gli elementi tecnici alla base della futura architettura di GPU AMD.
Cambia l'approccio, innanzitutto: per AMD č ora indispensabile sviluppare architetture di GPU che possano operare come potenti coprocessori che si affiancano alle proprie CPU. Affinché l'unione di GPU e CPU porti ad un approccio che sia il piů possibile eterogeneo sono necessarie numerose innovazioni non solo a livello di silicio ma anche di sistema operativo e, ovviamente, di supporto agli sviluppatori software.
L'architettura futura abbandona gli approcci VLIW5 e VLIW4, adottati il primo per tutte le GPU dalle serie Radeon HD 2900XT in poi e l'ultimo per le soluzioni della famiglia Radeon HD 6900, in favore di un design che abbina componente vector ad una scalar. Il cuore č indicato con il termine di Compute Unit o CU, all'interno della quale trovano posto tutte le unitŕ funzionali. La componente vettoriale interna ad ogni CU integra 4 core, mentre ogni CU prevede cache L1 proprietaria, unitŕ di branching e MSG, unitŕ di control e decode oltre a funzionalitŕ di instruction fetch arbitration.
La combinazione all'interno di ogni CU di componenti vector e scalar permette di gestire comportamenti molto differenti per ogni CU. In un caso puň operare come MIMD (Multiple Instructions Multiple Data), oppure come SIMD (Single Instruction Multiple Data), oppure ancora come SMT (Symmetric Multi-threading) in quanto ciascuno dei 4 core presenti nella vector unit puň operare su blocchi di istruzioni differenti. La risultante č quindi la possibilitŕ per ogni CU di operare ogni tipo di carico di lavoro in un dato istante, indipendentemente da quale sia la fonte dei dati e delle istruzioni.
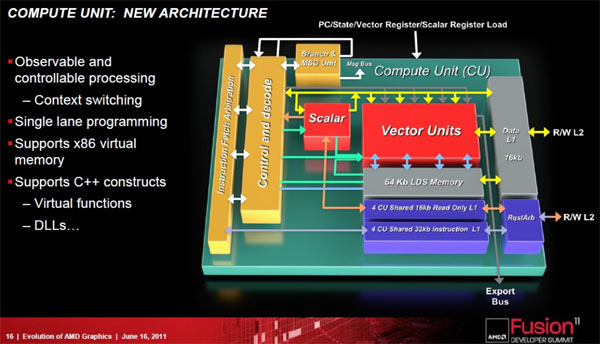
Cambia anche il tipo di supporto alla memoria; nelle nuove GPU verrŕ implementato l'indirizzamento alla memoria x86-64, di fatto unificando lo spazio di memoria indirizzabile tra CPU e GPU. Questo permetterŕ di rendere la GPU piů efficiente in contesti di elaborazione GPU Computing, soprattutto con dataset molto ampi.
Verrŕ ovviamente implementato il supporto alla double precision, con un livello prestazionale massimo teorico che potrŕ essere pari alla metŕ di quello in single precision per come č composta l'architettura della GPU. AMD potrebbe in ogni caso decidere di fornire differenti livelli prestazionali per la double precision, segmentando a seconda della specifica scheda. Le massime prestazioni verrebbero destinate alle sole proposte FirePro, passando a livelli prestazionali di 1/4 per le proposte desktop top di gamma scendendo sino a 1/16 per quelle entry level, mantenendo in ogni caso supporto alla double precision in tutte le tipologie di GPU.
Il debutto delle prime soluzioni basate su questa nuova architettura avverrŕ nel corso del quarto trimestre 2011, con soluzioni di tipo discreto posizionate teoricamente nel segmento top di gamma del mercato. Al momento attuale non č noto quale CU verranno implementate in GPU di fascia alta; alla stessa stregua non sono stati ancora rilasciati dettagli specifici sugli altri tradizionali elementi architetturali che caratterizzano le GPU.
_L.jpg) Nothing Ear e Ear (a): gli auricolari per tutti i gusti! La ''doppia'' recensione
Nothing Ear e Ear (a): gli auricolari per tutti i gusti! La ''doppia'' recensione Sony FE 16-25mm F2.8 G: meno zoom, più luce
Sony FE 16-25mm F2.8 G: meno zoom, più luce  Motorola edge 50 Pro: design e display al top, meno il prezzo! Recensione
Motorola edge 50 Pro: design e display al top, meno il prezzo! Recensione SYNLAB sotto attacco: sospesa l'attività presso i punti prelievo e non solo
SYNLAB sotto attacco: sospesa l'attività presso i punti prelievo e non solo BYD Seal U, primo contatto. Specifiche, design e prezzo, questa elettrica ha tutto al posto giusto
BYD Seal U, primo contatto. Specifiche, design e prezzo, questa elettrica ha tutto al posto giusto Intel ha completato l'assemblaggio dello scanner High-NA EUV: fondamentale per il processo 14A
Intel ha completato l'assemblaggio dello scanner High-NA EUV: fondamentale per il processo 14A Cina: aumenta del 40% la produzione di chip, le sanzioni statunitensi stanno diventando controproducenti
Cina: aumenta del 40% la produzione di chip, le sanzioni statunitensi stanno diventando controproducenti GPT-4 quasi come un oculista: in un test l'IA ottiene risultati simili agli specialisti
GPT-4 quasi come un oculista: in un test l'IA ottiene risultati simili agli specialisti  Prezzi super per gli Apple Watch SE di seconda generazione: eccoli a partire da 239€
Prezzi super per gli Apple Watch SE di seconda generazione: eccoli a partire da 239€ L'intelligenza artificiale ruba posti di lavoro? Ora hanno paura anche i CEO (ma intanto la usano per prendere decisioni)
L'intelligenza artificiale ruba posti di lavoro? Ora hanno paura anche i CEO (ma intanto la usano per prendere decisioni) The Witcher 3: disponibile su Steam il REDkit, lo strumento ufficiale per la creazione delle mod
The Witcher 3: disponibile su Steam il REDkit, lo strumento ufficiale per la creazione delle mod Xiaomi 15: trapelano importanti specifiche del futuro flagship. Ecco la scheda tecnica
Xiaomi 15: trapelano importanti specifiche del futuro flagship. Ecco la scheda tecnica Fallout 5? Meglio aspettare la seconda stagione della serie TV Amazon, arriverà prima!
Fallout 5? Meglio aspettare la seconda stagione della serie TV Amazon, arriverà prima! Motorola Edge 50 Pro č ora disponibile su Amazon: č stupendo e costa molto meno del prezzo ufficiale di 699€
Motorola Edge 50 Pro č ora disponibile su Amazon: č stupendo e costa molto meno del prezzo ufficiale di 699€ La tecnologia digitale sta trasformando la medicina di base in Italia. MioDottore ne è l'esempio
La tecnologia digitale sta trasformando la medicina di base in Italia. MioDottore ne è l'esempio S8 MaxV Ultra e Qrevo Pro: i nuovi aspirapolvere smart di Roborock arrivano in Italia. Prezzo e dettagli
S8 MaxV Ultra e Qrevo Pro: i nuovi aspirapolvere smart di Roborock arrivano in Italia. Prezzo e dettagli













_XXL.jpg)













35 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoGo Amd Gooooo!!!
e ciò che mi entusiasma di più è il fatto che queste architetture sono fortemente parallele...in poche parole, non stiamo parlando di un x86 dual - quad - six - octa core
Purtroppo ancora non hanno parlato di prestazioni... ma da quando ho capito sempre su B3D sembra che per clock si possano elaborare anche 128bytes contro i 64 di fermi... poi sono discorsi troppo tecnici che solo yossarian potrebbe delucidare
no ci stanno dicendo che da questo autunno l'architettura delle schede cambierà come non aveva fatto da 5 anni a questa parte e che in teoria le schede hanno un potenziale enorme
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".